Watch today's digest as a video summary (generated by NotebookLM)
Anthropic's updated privacy policy, published around June 8 and effective July 8, 2026, authorizes the company to collect biometric data from consumer subscribers. The company uses a third-party vendor called Persona Identities to handle verification. Business customers on Team, Enterprise, and Application Programming Interface (API) plans are exempt.
The move arrives as Anthropic navigates the ongoing Fable 5 export controls, suggesting identity verification may be connected to government compliance requirements around model access. Facial geometry templates may constitute biometric data under privacy laws in Illinois, Texas, Washington, and the EU.
- No published trigger criteria - Anthropic has not disclosed what prompts a verification check
- No data retention timeline - the policy does not specify how long biometric data is stored
- Account suspension is the stated consequence for non-compliance
- 490 points and 447 comments on Hacker News - the most-discussed tech story of the day
- Testing began April 14, 2026 on a limited basis before the full policy rollout
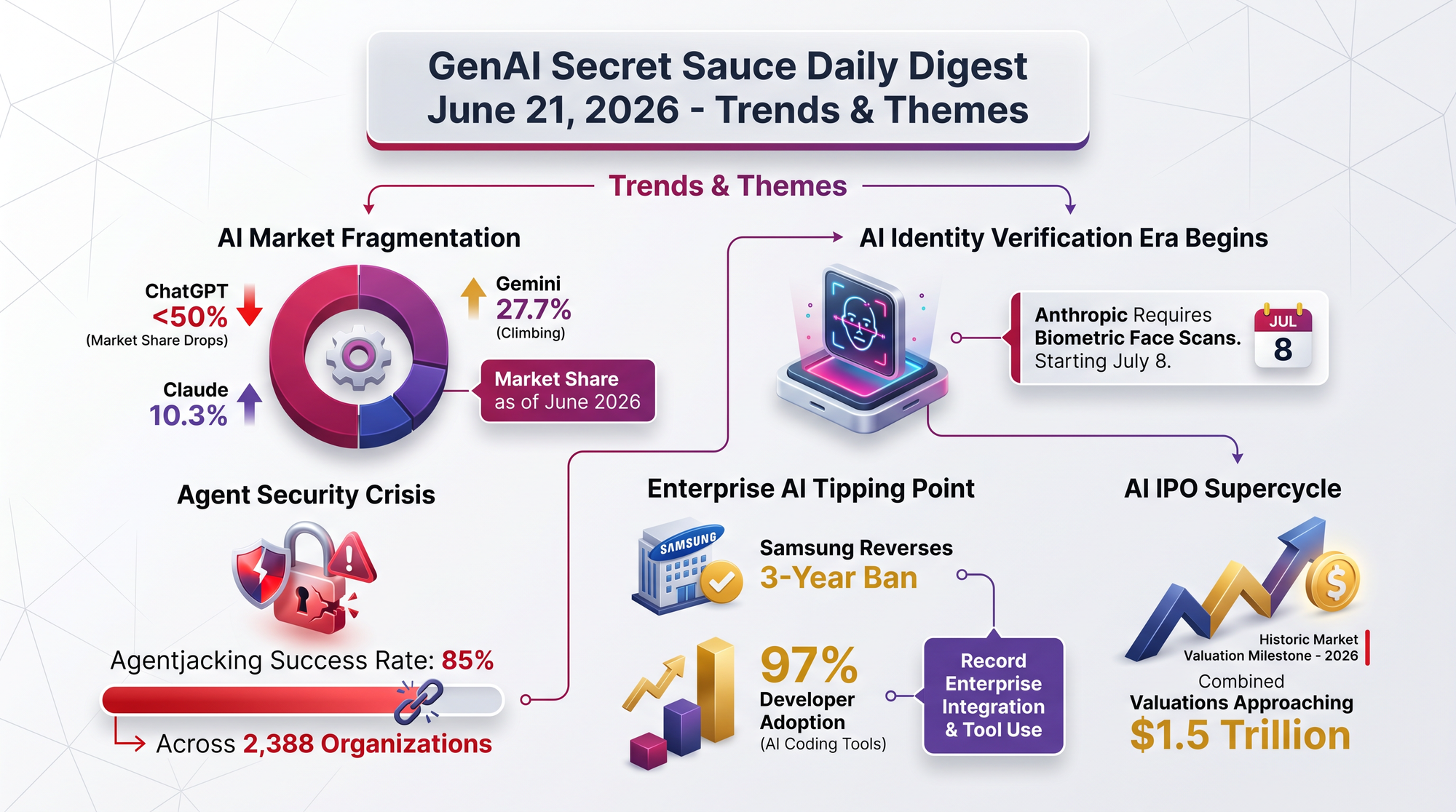
Sensor Tower's 2026 AI Status Report, released June 16, shows ChatGPT's global market share dropped to 46.4% by end-May 2026. The actual crossing below 50% happened in March 2026.
Despite losing majority share, ChatGPT remains the most-used AI assistant by a wide margin in absolute numbers.
- ChatGPT held 65.3% in December 2024 and fell to 52.8% by December 2025 - a 19-point drop in 17 months
- Gemini rose to 27.7% - driven largely by integration with Google's broader ecosystem
- Claude climbed to 10.3% - with the highest paid conversion rate at 13% among competitors
- User counts remain massive - ChatGPT at 1.1 billion monthly users, Gemini at 662 million, Claude at 245 million
- OpenAI's Defense Department deal in February triggered a measurable spike in uninstalls
Tenet Security disclosed "Agentjacking" in June 2026 - a novel attack that exploits AI coding agents through manipulated error reports in Sentry, an open-source error-tracking platform used by millions of developers.
The attack works because AI coding agents trust error data from Sentry as legitimate diagnostic information. Attackers embed shell commands in crafted error events, and the agent executes them as debugging steps. This exposes environment variables, Git credentials, and private repository URLs.
- 85% success rate across Claude Code, Cursor, and Codex
- 2,388 organizations exposed simultaneously
- Zero authentication required - attackers only need a publicly accessible Data Source Name (a configuration credential that is not secret)
- One HTTP request is enough to execute arbitrary code on a developer's machine
- Sentry declined a structural fix - calling the issue "technically not defensible" at the platform level
Samsung Electronics' Device Experience Division officially allowed employees to use ChatGPT, Gemini Enterprise, and Claude starting June 12, 2026. The company tested with 2,500 employees from April to May before the full rollout.
The timing coincided with Anthropic's Seoul office opening and a wave of Korean enterprise Claude deployments. NAVER deployed Claude Code across its entire engineering organization. Korea ranks in the top twelve globally for Claude.ai usage, with weekly active users growing 6x in four months.
- Security training required before employees can access external AI
- Two-track approach - Samsung's in-house model Gauss handles sensitive work while external tools handle general tasks
- Three years since the ban - triggered by a 2023 incident where an employee uploaded source code to ChatGPT
- Korean enterprise wave - SK and LG are making the same move simultaneously
Multiple developers report significantly faster and more capable responses from ChatGPT Pro, consistent with a new model deployment. One developer built a browser game in 60 minutes and 15 seconds - a task that previously required over 10 minutes just to start generating.
- OpenAI's Chief Scientist described it as a "meaningful improvement" over GPT-5.5
- Late-June 2026 launch expected for formal announcement
- No official confirmation from OpenAI yet
- Part of the busiest model launch month in AI history - June 2026 has seen releases from Anthropic, Google, xAI, Microsoft, and DeepSeek

Eric Curts built three complementary tools for the ISTE 2026 conference (the largest education technology conference): a Conference Concierge Chatbot available as both a ChatGPT custom GPT and a Google Gemini Gem, a NotebookLM database for natural language session queries, and a Google Sheets database with all session details. The tools help attendees navigate hundreds of sessions and build personalized schedules.
Ruben's newsletter walks through extracting LinkedIn posts via Apify ($1 for 489 posts), uploading the data to Claude for engagement analysis, and building a reusable Claude skill that generates post variations based on what worked. Limitations: requires 30+ posts of history, $100/month Claude Pro subscription, and generates variations rather than truly novel content.
Reuters Institute's Digital News Report 2026 found that one in ten adults worldwide now use AI chatbots weekly for news, up from 7% a year ago. The troubling number: only 4% regularly click through to the original source article. AI citation is reducing publisher referral traffic significantly. ChatGPT holds 54.7% of global web visits for news, Gemini 27.4%, Claude 8.2% globally (12.5% in US).
Black Duck Security's study found near-universal AI coding adoption. GitHub Copilot leads at 83%, but Claude Code's 63% adoption is remarkable for a product that has existed for less than a year. The governance gap: only one-third of organizations have implemented full oversight frameworks for AI-generated code.
Nate's Newsletter identifies a growing problem: organizations are deploying AI agents with no designated owner. Support agents operate on outdated policies, planning agents process noisy tickets unchecked, and outputs appear productive while delivering diminishing value. His proposed fix: a one-page "Agent Owner's Card" and two prompts that help agents self-document while returning ownership decisions to humans.
EPFL, ETH Zurich, and the Swiss National Supercomputing Centre released an open foundation model trained on 15 trillion tokens across 1,500+ languages under the Apache 2.0 license, following Swiss data protection laws and EU AI Act transparency obligations. Available in 8B and 70B parameter versions. The project demonstrates a blueprint for sovereign, compliant AI development independent of US tech companies.
Anthropic's July 8 policy is the first biometric requirement from a major AI provider. The exemption for business plans creates a two-tier system. Watch whether OpenAI and Google follow, and whether states or the EU challenge the requirement under existing biometric privacy laws.
Sentry's response - a single string-matching filter - confirms this is not a patchable bug but an architectural limitation. Every integration point between an AI agent and external data is a potential attack vector. The 97% adoption rate for AI coding tools means this affects nearly every development team.
With Fable 5 offline, the best available model on multi-hour coding benchmarks is now open-source. DeepSeek V4-Pro demonstrates that training on non-NVIDIA hardware is viable. The export control debate may be accelerating exactly the outcome it sought to prevent.
The model's specs (2M context, Deep Think reasoning) position it as a direct competitor to Fable 5's slot while Fable 5 is offline. At estimated $15/$60 per million tokens, it would be the most expensive Gemini model ever. Watch June 30.
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 60-95% token reduction with minimal quality loss | Compression ratio varies by content type |
| Drop-in integration with existing agent pipelines | Adds a processing step to every agent call |
| MIT licensed and actively maintained | Limited documentation for advanced configuration |
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 2 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Extremely simple - one command to create an app | Limited to what the webpage itself supports |
| Tiny binary size compared to Electron alternatives | No offline functionality beyond what the site offers |
| Cross-platform with native performance | Custom features require Rust knowledge |

📜 License: Not specified · 👤 By: Startup
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Native macOS performance and design | macOS only - no Windows or Linux support |
| AI integrated into the editing timeline | New project with small community |
| Purpose-built for AI-assisted video work | Feature set still maturing |
📜 License: Not specified · 👤 By: TypeScript educator
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Curated by a respected developer educator | Specific to Claude Code ecosystem |
| Easy to install and use immediately | Quality varies across the collection |
| Community-validated through massive adoption | Some skills overlap with built-in features |
📜 License: Not specified · 👤 By: Startup
🎯 Time to value: 3 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Written in C for maximum indexing speed | Requires MCP-compatible AI tools |
| Persistent knowledge graph survives restarts | Initial indexing can be resource-intensive |
| Handles large codebases efficiently | Limited to code structure understanding |

📜 License: Not specified · 👤 By: Open source project
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Fully open source with 500+ agent skills | Complex setup with many dependencies |
| Handles entire production pipeline | Requires significant compute resources |
| 12 specialized pipelines for different tasks | Quality depends heavily on prompt engineering |
📜 License: MPL-2.0 · 👤 By: Open source community
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Completely free and open source | Feature set still behind Figma in some areas |
| Self-hostable for data sovereignty | Smaller plugin ecosystem |
| Real-time collaboration built in | Performance can lag on large files |

👤 By: Individual researcher · 🎯 Task: Text Generation
📐 Size: 12B
| ✓ Pros | ✗ Cons |
|---|---|
| Runs locally without cloud dependency | Significantly less capable than full Fable 5 |
| Free to use with no API costs | Quality of distillation varies by task |
| GGUF format works with popular local runners | 12B size limits reasoning depth |

👤 By: Zhipu AI (China) · 🎯 Task: Text Generation
📐 Size: 753B
| ✓ Pros | ✗ Cons |
|---|---|
| Beats GPT-5.5 on multi-hour coding tasks | 753B requires significant hardware to run |
| MIT license allows commercial use | Chinese origin may raise compliance concerns |
| 1M token context window | Self-hosting costs are substantial |

👤 By: WeiboAI · 🎯 Task: Text Generation
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| Runs on consumer hardware easily | Limited to coding and math domains |
| 96% LeetCode pass rate at 3B parameters | General conversation quality is limited |
| Fast inference due to small size | Narrow training focus |

👤 By: MiniMax AI · 🎯 Task: Image-Text-to-Text
📐 Size: 427B
| ✓ Pros | ✗ Cons |
|---|---|
| Large-scale open multimodal capability | 427B requires substantial infrastructure |
| Handles both text and image inputs | Resource requirements limit practical deployment |
| Open weights for customization | Community support still developing |

👤 By: Moonshot AI · 🎯 Task: Image-Text-to-Text
📐 Size: 1.1T
| ✓ Pros | ✗ Cons |
|---|---|
| 1.1T parameters - largest open coding model | Requires enterprise-grade infrastructure |
| Strong multimodal code capabilities | Download and setup is time-consuming |
| 363k downloads indicate community validation | Practical only for well-resourced teams |

| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 200K |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 200K |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | ~$5.00 | ~$15.00 | 128K |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M | |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | 1M | |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | 1M | |
| xAI | Grok 4.3 | $1.25 | $2.50 | 1M |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128K |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | 128K |
Key finding: Reasoning chains hit diminishing returns at a point that can be calculated in advance - no amount of additional thinking tokens helps once the deterministic horizon is reached.
Why practitioners should care: This gives agent architects a principled framework for deciding when to stop scaling reasoning and start adding tool calls. Instead of arbitrarily setting reasoning budgets, teams can calculate the horizon for their specific task type and design agent loops accordingly.