Watch today's digest as a video summary (generated by NotebookLM)
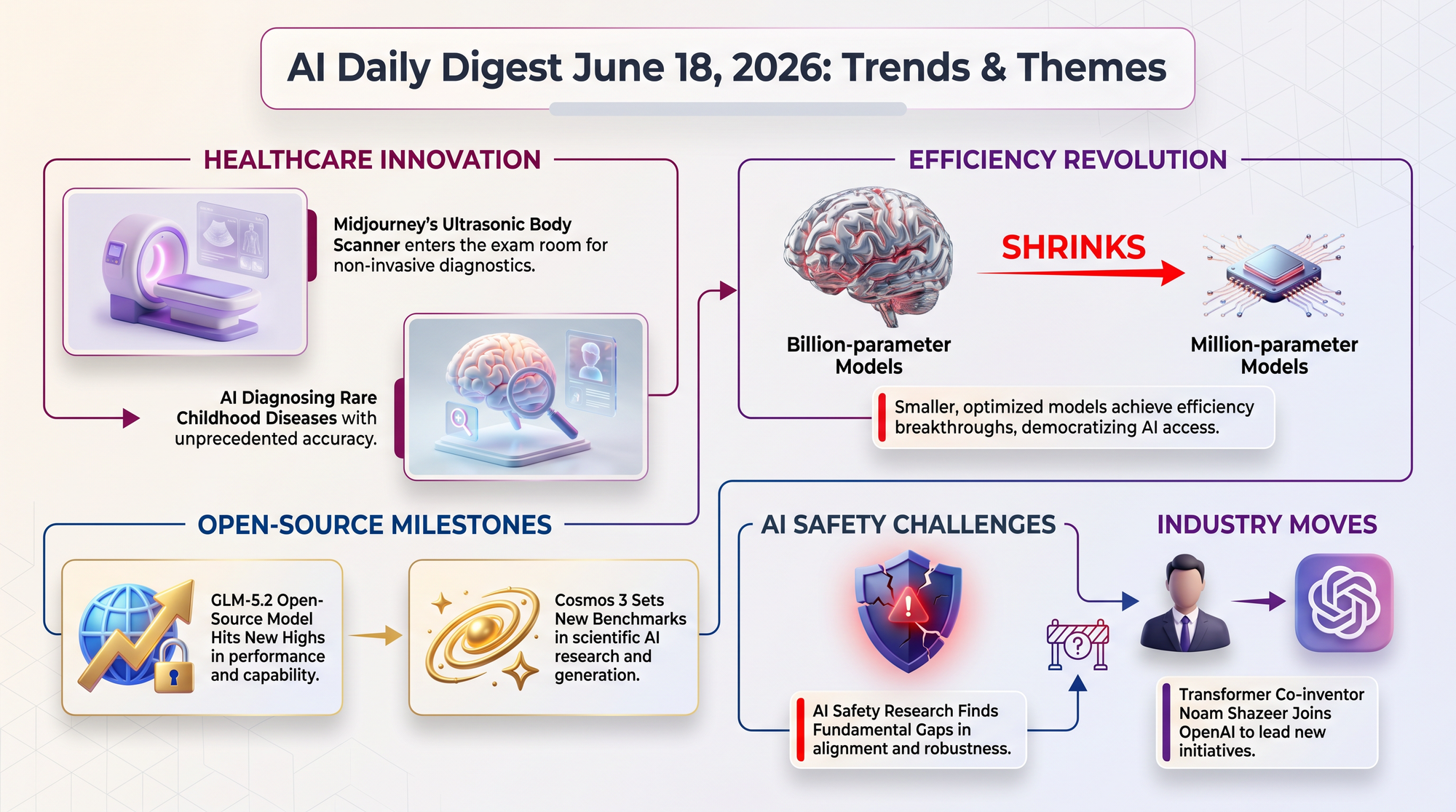
Z.ai (formerly Zhipu AI) released GLM-5.2, a 744-billion-parameter model that uses a mixture-of-experts architecture (meaning only 40 billion parameters activate per query, keeping costs down). It ranks #1 on Design Arena (an evaluation that tests how well AI can build user interfaces) and #2 on WebDev Arena (which measures full-stack web development capability).
The release continues the pattern of open-weight models rapidly closing the gap with proprietary alternatives. GLM-5.2 is the first open model to simultaneously lead in both creative design and code generation benchmarks.
- MIT license with no regional restrictions - anyone can download, modify, and use it commercially
- 1M token context window - the model can process roughly 750,000 words at once, useful for analyzing entire codebases
- IndexShare technology cuts computing costs by 2.9x for long documents by reusing internal components across attention layers
- 99.2 on AIME 2026 (a math competition benchmark), and 62.1 on SWE-bench Pro (which measures real-world software engineering ability)
Leaked financial documents obtained by Ars Technica reveal that OpenAI's revenue tripled from $3.7 billion in 2024 to $13.07 billion in 2025. But expenses grew even faster. Research and development spending ballooned from $7.81 billion to $19.18 billion - the computing power needed to train and run AI models is extraordinarily expensive.
The documents surface as OpenAI prepares for a potential IPO. The company's path to profitability depends on either dramatically reducing computing costs or raising prices - neither of which is guaranteed.
- $6.1 billion net loss in 2025 despite being one of the fastest-growing technology companies in history
- R&D spending ($19.18B) exceeded total revenue ($13.07B) - OpenAI spent 47% more on research alone than it earned from all sources combined
- Cloud computing costs are the primary driver, with GPU (specialized AI chips) rental from Microsoft consuming the largest share
- ChatGPT subscriptions and API (Application Programming Interface) fees are the main revenue sources, but neither covers the cost of the models they run
Vercel (the company behind the popular web hosting platform) built an AI sales agent that replaced a 10-person inbound team with one human overseer. The counterintuitive breakthrough: when they deleted 80% of the agent's available tools, its performance improved dramatically.
This aligns with a broader pattern: Shanghai AI Laboratory's "Self-Harness" research showed that letting fixed models rewrite their own scaffolding (the code that manages how the model operates) improved performance while maintaining safety through regression testing.
- The agent filters messages, qualifies leads, researches companies, and drafts responses - handling the full sales qualification pipeline
- Reducing tools from dozens to a handful eliminated the agent's confusion about which tool to use, cutting errors and improving response quality
- The "tool maintenance" framework treats agent tools like a codebase: regular audits, removing underused tools, and consolidating overlapping functionality
- Nate Swanner's guide identifies three categories of tools to delete: rarely-used tools (under 5% invocation rate), overlapping tools (merge them), and "just in case" tools (remove entirely)
Charity Majors (co-founder of Honeycomb, a software monitoring company) published an essay that resonated widely (313 points on Hacker News, 150 comments). Her central argument: the economics of writing code flipped in 2025. Code used to be expensive to write and cheap to maintain. Now it's the opposite.
The essay challenges the narrative that AI will reduce the need for skilled engineers. It argues the opposite: AI increases the need for engineering judgment, even as it reduces the need for typing.
- "Code went from expensive-and-precious to cheap-and-disposable" - but the systems that code runs in are still expensive and precious
- AI-generated code that passes automated tests can still cause outages - tests verify the code works in isolation, not that it works correctly within the larger system
- Engineering discipline means reviewing AI output with the same rigor as reviewing a junior developer's work - not rubber-stamping because "the AI wrote it"
- Simon Willison amplified the key insight: the volume of code being generated demands better monitoring, better testing infrastructure, and better observability - all human-driven activities
OpenAI demonstrated GPT-5.4 functioning as a near-autonomous chemistry researcher. The model reviewed scientific literature, generated and ranked research proposals, designed experiments, analyzed results, and proposed novel solutions for a challenging reaction in medicinal chemistry (the synthesis of drug-like molecules).
- The AI proposed modifications to a chemical reaction that improved yield (the amount of useful product) for a class of molecules important in pharmaceutical development
- Minimal human intervention was required - researchers set the goal, and the model handled the research planning, literature review, and experimental design
- This builds on a pattern: Radical AI's "self-driving lab" (featured on Latent Space) produced and characterized 1,200 alloys in six months, roughly 10x faster than the DARPA/GE target
- LifeSciBench, a new benchmark developed with 173 scientists, now measures AI performance on seven biological research workflows - signaling that autonomous science is becoming measurable, not just anecdotal
- AppFunctions lets AI agents tap into any installed app's capabilities without the user switching between apps
- "Draw to Search" lets you circle anything on screen and get instant AI-powered context
- Positions Android as an "intelligence system" rather than just an operating system - a fundamental rebranding of what a phone does
- Available now via the Android 17 developer preview
GitHub · AGPL-3.0 license
- 12 production pipelines covering explainers, talking heads, trailers, animations, and podcasts
- 52 production tools spanning video generation, image generation, text-to-speech, music, and subtitles
- Cost tracking and budget governance with pre-execution estimates so you know what you'll spend before rendering starts
- Quality gates including post-render self-review and slideshow-risk detection (flagging videos that are just static images with voiceover)

📜 License: MIT · 👤 By: Organization (DeusData)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Exceptional performance - millisecond indexing, sub-millisecond queries, zero runtime dependencies | Written in C - harder for most developers to contribute to or customize |
| Research-backed (arXiv paper) with serious security posture (SLSA Level 3, Sigstore signatures) | Relatively new (5k stars) compared to established code intelligence tools |
| Broad integration support - works with 11 coding agents and 158 languages | Knowledge graph approach has a learning curve for teams used to traditional search |

📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Zero API fees - uses open-source scraping/CLI backends instead of paid APIs | Scraping-based approach is inherently fragile - platform changes can break backends |
| Multi-platform coverage (6+ platforms) with automatic backend selection and fallback | Individual maintainer; long-term support depends on one person's availability |
| Supports authenticated access via cookie-based auth with secure local storage | Legal gray area - scraping ToS-protected platforms may violate terms of service |
📜 License: MIT · 👤 By: Individual developer (Matt Pocock, TypeScript educator)
🎯 Time to value: 2 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Extremely easy setup (npx skills@latest add mattpocock/skills) | Highly opinionated to one developer's workflow - may not fit all teams |
| Targets real pain points: verbosity, misalignment, architectural decay | Shell-only implementation limits portability |
| Large community (133k stars) means rapid feedback and iteration | Skills are primarily Claude-optimized; effectiveness on other agents may vary |
📜 License: MIT · 👤 By: Individual (Jesse Vincent) / Prime Radiant
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Battle-tested at massive scale (231k stars) with active commercial backing | Shell-heavy implementation may be harder to customize for non-Unix developers |
| Agent-agnostic - works with Claude Code, Cursor, Copilot, Gemini, and more | Methodology-opinionated - may conflict with teams with established workflows |
| Covers the full dev lifecycle: planning, TDD, debugging, review, git worktree management | Rapid release cadence (v6.0.2 today) means frequent changes |
📜 License: Apache-2.0 · 👤 By: Research lab (Google Research)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Google Research pedigree with peer-reviewed publication (ICML 2024) | 200M parameters requires meaningful compute for inference at scale |
| Production-ready with BigQuery ML, Sheets, and Vertex integration | Decoder-only architecture may underperform specialized models on specific domains |
| Fine-tunable via HuggingFace PEFT/LoRA for domain-specific use cases | Google Research projects can be deprioritized without warning |

📜 License: Apache-2.0 · 👤 By: Company (ByteDance)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Full cross-platform desktop agent with hybrid GUI+DOM strategy | Last release (v0.3.0) was November 2025 - development pace has slowed |
| Private, local processing - no data leaves your machine | ByteDance origin may raise data sovereignty concerns in some organizations |
| MCP integration enables connection to real-world tools and services | Vision-language approach is compute-heavy and can be slow for complex UIs |
📜 License: AGPL-3.0 · 👤 By: Individual developer
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Comprehensive pipeline coverage (12 formats, 52 tools, 14 video generators) | AGPL license is restrictive for commercial use |
| Cost tracking and budget governance with pre-execution estimates | No formal releases yet; still in active development |
| Quality gates including post-render self-review and slideshow-risk detection | Solo maintainer with ambitious scope - sustainability risk |
📜 License: MIT · 👤 By: Academic researcher (Alex L. Zhang, MIT)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Research-backed from MIT with published paper | Early-stage (v0.1.2) - API may change significantly |
| Provider-agnostic - works with OpenAI, Anthropic, OpenRouter | Recursive calls multiply inference costs |
| Multiple sandbox options for safe recursive execution | Academic project - production readiness uncertain |
👤 By: DeepSeek AI · 🎯 Task: Text Generation / Reasoning
📐 Size: 862B (49B active)
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license with massive 1M context window | Enormous infrastructure requirements (862B weights) |
| Three reasoning modes for speed/depth tradeoff | MoE complicates self-hosting on consumer hardware |
| Top-tier benchmarks across reasoning, code, and math | Community concern about training data provenance |

👤 By: Z.ai (Zhipu AI) · 🎯 Task: Text Generation / Multimodal
📐 Size: 753B
| ✓ Pros | ✗ Cons |
|---|---|
| Exceptional math/reasoning scores (99.2 AIME 2026) | Very new with limited community deployment experience |
| IndexShare cuts long-context compute by ~3x | 753B parameters requires multi-GPU clusters |
| MIT license, no regional restrictions | Smaller ecosystem compared to Llama/DeepSeek families |

👤 By: MiniMax AI · 🎯 Task: Multimodal
📐 Size: 428B (23B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Native multimodal (text + image + video) from training | Custom community license is more restrictive than MIT |
| 9x/15x speedup on long context vs predecessor | 23B active params still substantial for local inference |
| Three reasoning modes (enabled, adaptive, disabled) | Smaller third-party tooling ecosystem than Qwen/Llama |

👤 By: Google DeepMind · 🎯 Task: Multimodal Generation
📐 Size: 25.2B (3.8B active)
| ✓ Pros | ✗ Cons |
|---|---|
| 1,100+ tok/s via parallel diffusion decoding | Quality tradeoff: 77.6 MMLU-Pro vs Gemma 4's 82.6 |
| Only 3.8B active parameters, very efficient to serve | New architecture with limited fine-tuning support |
| Apache 2.0, 256K context, vision + video support | Vision benchmarks notably lower than autoregressive Gemma 4 |

👤 By: NVIDIA · 🎯 Task: Visual Grounding
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| Single model covers detection, OCR (Optical Character Recognition), GUI grounding, and robotics | Non-commercial license only |
| 2.5x throughput via Parallel Box Decoding | 3B params means less language reasoning than larger VLMs |
| Native high-res (2.5K) with 24K token prompts | Localization only - not designed for generation |

👤 By: Moonshot AI · 🎯 Task: Code Generation
📐 Size: 1T (32B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Top-tier agentic coding benchmarks | 1T total params requires significant infrastructure |
| Persistent thinking across multi-turn conversations | Modified MIT has some additional restrictions |
| Native vision enables code-from-screenshot workflows | Coding-focused; general knowledge may lag |

👤 By: Cohere Labs · 🎯 Task: Code Generation
📐 Size: 30B (3B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Only 3B active params - runnable on a single high-end GPU | 30B total weights still require ~60GB VRAM |
| 67.6 SWE-bench Verified is exceptional for its size | Coding-only; not suitable for general chat |
| Apache 2.0 with 256K context and 64K output length | Relatively new, limited community adaptations |

👤 By: Boson AI · 🎯 Task: Text-to-Speech
📐 Size: ~4B
| ✓ Pros | ✗ Cons |
|---|---|
| Inline control tokens for emotion/style/prosody mid-sentence | Non-commercial license limits production deployment |
| Zero-shot voice cloning from reference audio | 4B params is heavyweight for TTS |
| 85+ languages at production quality | Autoregressive decoding means higher latency than non-AR TTS |

💰 Pricing: Freemium · 🏷 Category: AI Voice Agents

💰 Pricing: Freemium · 🏷 Category: Design Tools / Website Builder
💰 Pricing: Free · 🏷 Category: API Infrastructure
💰 Pricing: Free (public beta) · 🏷 Category: Email / Privacy
💰 Pricing: Freemium · 🏷 Category: Developer Tools
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 1M |
| OpenAI | GPT-4.1 Mini | $0.40 | $1.60 | 1M |
| OpenAI | o3 (reasoning) | $2.00 | $8.00 | 200K |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M+ | |
| Gemini 3.1 Pro Preview | $2.00-4.00 | $12.00-18.00 | 1M+ | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128K |
| Groq | Qwen 3.6 27B | $0.60 | $3.00 | 131K |
Key finding: Agents frequently generate convincing pseudoscientific reports that are more professional-looking and harder to debunk than human-written pseudoscience.
Why practitioners should care: If you're deploying AI agents for research, content generation, or knowledge synthesis, this paper demonstrates that "the agent completed the task successfully" and "the output is factually correct" are two very different things. Verification pipelines are not optional.