Watch today's digest as a video summary (generated by NotebookLM)
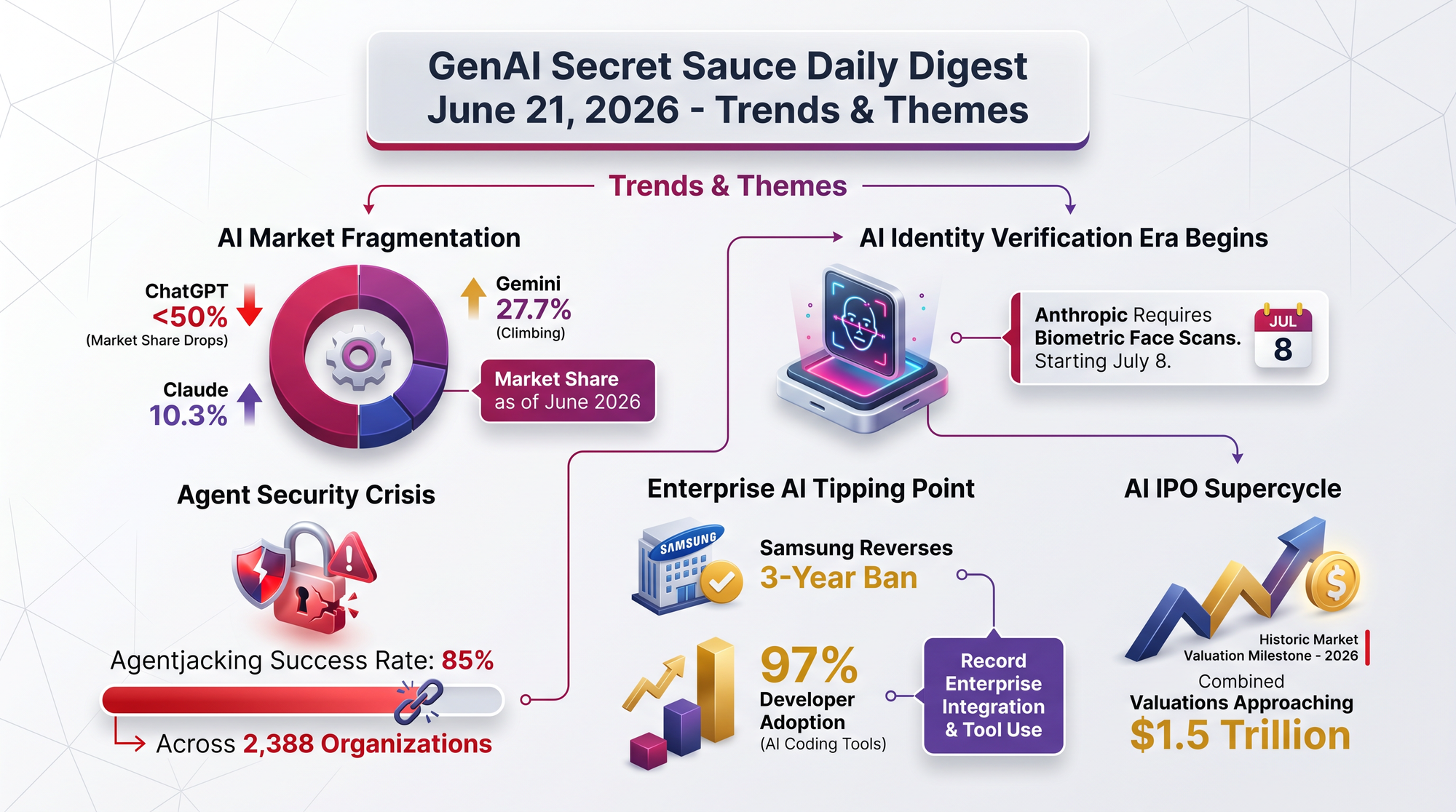
OpenAI expanded its Daybreak cybersecurity initiative with three major releases. GPT-5.5-Cyber is a specialized version of their flagship model fine-tuned for finding and patching software vulnerabilities. A new Codex Security plugin lets developers scan code for vulnerabilities directly inside their editor. The Daybreak Cyber Partner Program launched with three enterprise security firms - TrendAI, Sophos, and Proofpoint - who can now use GPT-5.5 with Trusted Access in their own products.
- "Patch the Planet" already produced results - 37 merged patches, 64 pull requests, and 51 issues filed across 19 projects in its first week
- Major open-source projects participating - cURL, Go, Python, Sigstore, and pyca/cryptography are among 30+ committed projects
- Maintainers get free tools - participating projects receive ChatGPT Pro, Codex Security access, and Application Programming Interface (API) credits
- Trail of Bits co-founded the initiative and manages the full defensive loop from discovery through deployment
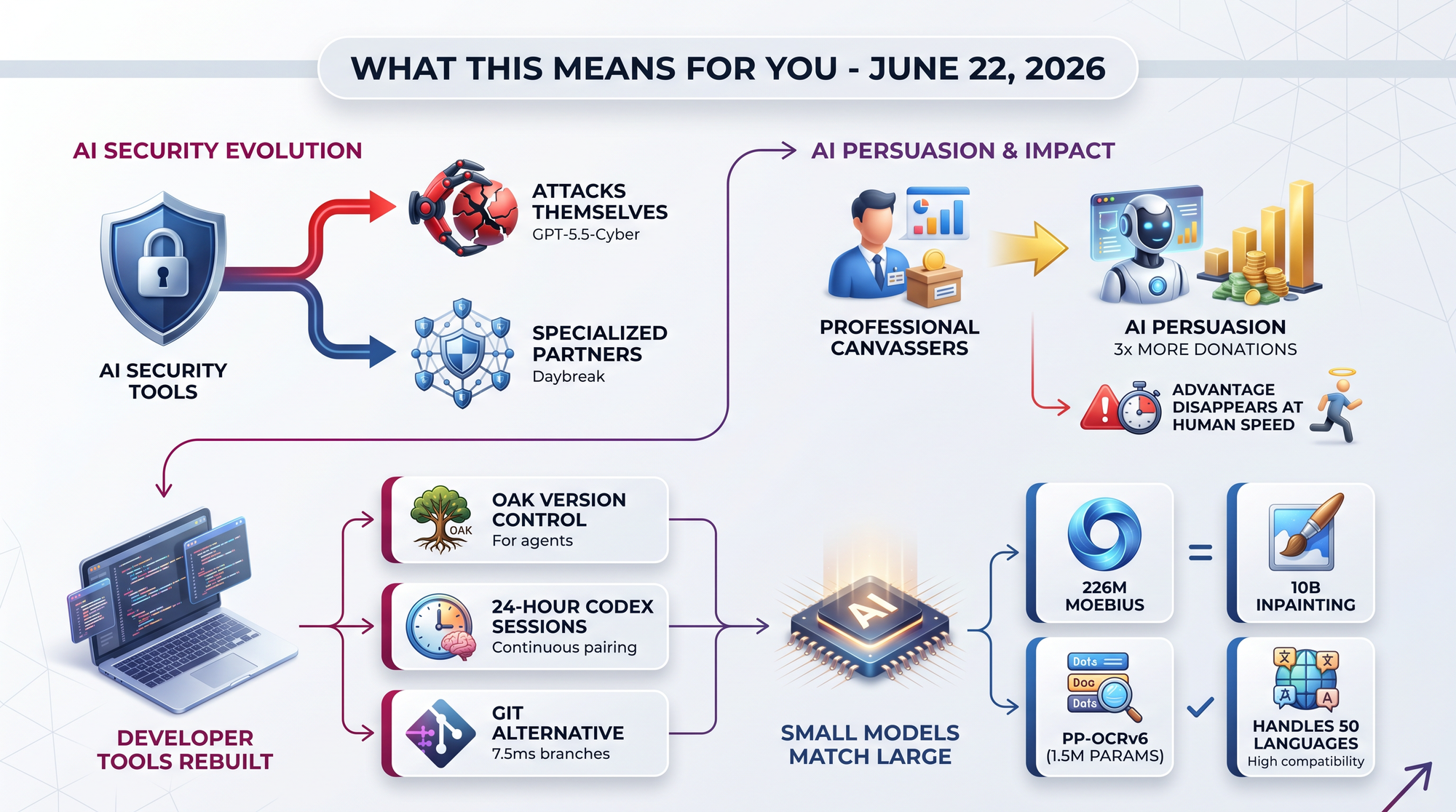
A landmark study by Oxford, the UK AI Security Institute, Stanford, and LSE tested persuasion across 18,978 conversations with 6,923 people. The finding is unambiguous: AI systems proved "reliably more persuasive than expert humans" on policy issues and charitable donations.
The researchers note this creates a societal choice about how persuasive AI capabilities are distributed and regulated.
- Top performers included Opus 4.1, Opus 4.6, GPT-4o, GPT-5.4, Gemini 2.5 Pro, and Grok 4.20 - exceeding every class of human persuader tested
- AI raised nearly 3x more donations than professional canvassers from UK firms
- The advantage collapsed when AI was constrained to human message length and speed - suggesting AI wins partly through sheer volume and responsiveness
- Even elite debaters who chose their own topics and had £1,000 bonuses lost to AI systems
A developer discovered that Codex's SQLite feedback logging system was writing approximately 640 TB per year to local SSDs. Most consumer drives carry warranty ratings of around 600 TBW (terabytes written), meaning this single bug could exhaust a drive's entire warranted lifespan within 12 months. The issue drew 457 points and 250 comments on Hacker News.
- The root cause was a global TRACE-level logging default that persisted everything, including raw WebSocket payloads and OpenTelemetry events
- TRACE-level logs accounted for 70.7% of retained bytes in the bloated database
- The database showed 506,149 retained rows but 5.5 billion allocated row IDs - a 10,000x gap indicating massive write-then-delete churn
- Two fixes merged same-day - filtering noisy targets and stopping per-event WebSocket logging, reportedly eliminating 85% of the problem
Security researchers at Spur scanned 6,038 smart TV apps across LG and Samsung platforms and found 2,058 (34%) contained residential proxy SDKs (software that routes other people's internet traffic through your connection). LG webOS showed particularly high prevalence.
- Bright Data is the dominant provider with 367 proxy-flagged apps, plus 16 from Honeygain/Oxylabs
- Apps are deliberately non-intrusive - screensavers, clocks, fish tanks, simple games - so users never suspect background activity
- Pac-Man on Samsung Tizen frames Bright Data as an "ad-free option" creating a false choice between ads or network sharing
- Amazon and Roku explicitly prohibit this practice but LG and Samsung have no equivalent policy
- The January 2026 Kimwolf botnet case showed the real danger - residential proxy networks were exploited to access devices on home networks
Patrick McCanna published an analysis revealing that Claude Code's extended thinking output is not the raw reasoning process. The actual reasoning is encrypted into 600-character signatures, and Anthropic holds the decryption key. Full thinking output requires an enterprise agreement. The article drew 253 points and 179 comments on Hacker News.
- The API returns summaries described as equivalent to "converting and re-saving file formats with information loss"
- Anthropic's documentation uses indirect language that may cause users to miss the summarization
- Organizations cannot produce reliable audit trails from local session files since reasoning logs remain inaccessible
- The transparency gap matters most for regulated industries where decision audit trails are legally required
The "lethal trifecta" for AI attacks requires ingesting untrusted data, accessing private information, and being able to send data out. As AI agents gain more capabilities, all three conditions are increasingly met by default.
- OpenAI's Daybreak launched GPT-5.5-Cyber with three enterprise partners (Sophos, Proofpoint, TrendAI) on day one
- Gray Swan raised a Series A with Snowflake as investor, offering automated red-teaming that outperforms human testers
- Anthropic-Cybersecurity-Skills hit 18.6K GitHub stars - 817 structured security skills mapped to 6 frameworks
- NVIDIA's SkillSpector found 26% of AI agent skills contain vulnerabilities (covered June 15)
The persuasion study suggests AI's advantage comes partly from volume and speed - but the end result is the same: people change their minds.
- 18,978 conversations across 6,923 participants showed AI beating every class of human persuader
- AI raised nearly 3x more charitable donations than professional canvassers
- The advantage disappeared when AI was constrained to human communication speed and message length
- DeepMind separately published four pathways to artificial superintelligence including recursive self-improvement
The shift toward agent-native infrastructure continues. Version control, deployment, and monitoring are all being rebuilt with AI-first assumptions.
- OpenAI's Codex-maxxing guide reveals GPT-5.1-Codex-Max working on single tasks for 24+ hours across millions of tokens
- Oak launched a Git alternative purpose-built for AI agents with lazy mounts and 7.5ms branch creation
- The Codex SSD logging bug showed how aggressive telemetry in AI dev tools creates real hardware damage
- Garry Tan's gstack hit 113K GitHub stars - 23 Claude Code tools from Y Combinator's CEO
The pattern is consistent: targeted architectures with clever training strategies outperform general-purpose models at specific tasks while costing a fraction to run.
- Moebius achieves 10B-model-level image inpainting with only 226M parameters - less than 2% the size, 15x faster
- PP-OCRv6 handles 50 languages with models from 1.5M to 34.5M parameters - readable text recognition at a fraction of typical model sizes
- DeepSeek's new inference architecture unlocks compute that already exists by rerouting data flow to underutilized hardware
What it lets you do: Remove objects from photos, fill in missing areas, or edit specific parts of images - with quality matching models 50x larger, on a single GPU.
The key innovation is the LλMI block, which compresses context into fixed-size matrices instead of scaling quadratically with image size.
- 226M parameters vs. FLUX.1-Fill-Dev's 11.9B - less than 2% the size
- 26ms per inference step with over 15x total runtime acceleration
- Matches or surpasses FLUX.1-Fill-Dev and SD3.5 Large-Inpainting across six benchmarks
- Particularly strong on complex textures and facial plausibility
- Converts HTML templates directly into video - designed for AI agents that can write HTML but not use traditional video editors
- 29.9K GitHub stars and trending today
- Built for automated video production pipelines where agents generate content programmatically
Gray Swan's Human Browser Agent Robustness Challenge found that humans ranked only fourth among tested systems, with skilled red teamers achieving 60-70% phishing success rates. Models were vulnerable to attacks humans would never fall for - like emails claiming to be simulations requesting credential forwarding.
When AI systems were limited to human message length and communication speed, the persuasion advantage over expert humans "collapsed" to non-significant levels. AI wins partly through sheer volume and responsiveness, not qualitatively superior arguments.
Recursive, a newly founded startup, demonstrated automated research loops achieving state-of-the-art on NanoChat Autoresearch and record-setting NanoGPT Speedrun performance. The catch: success is currently limited to well-defined, measurable, quickly-evaluable goals.
The Codex logging database retained 506,149 rows but had allocated over 5.5 billion row IDs - a 10,000x gap indicating it was constantly writing and deleting data. The SQLite sink was using Targets::new().with_default(Level::TRACE) to persist everything.
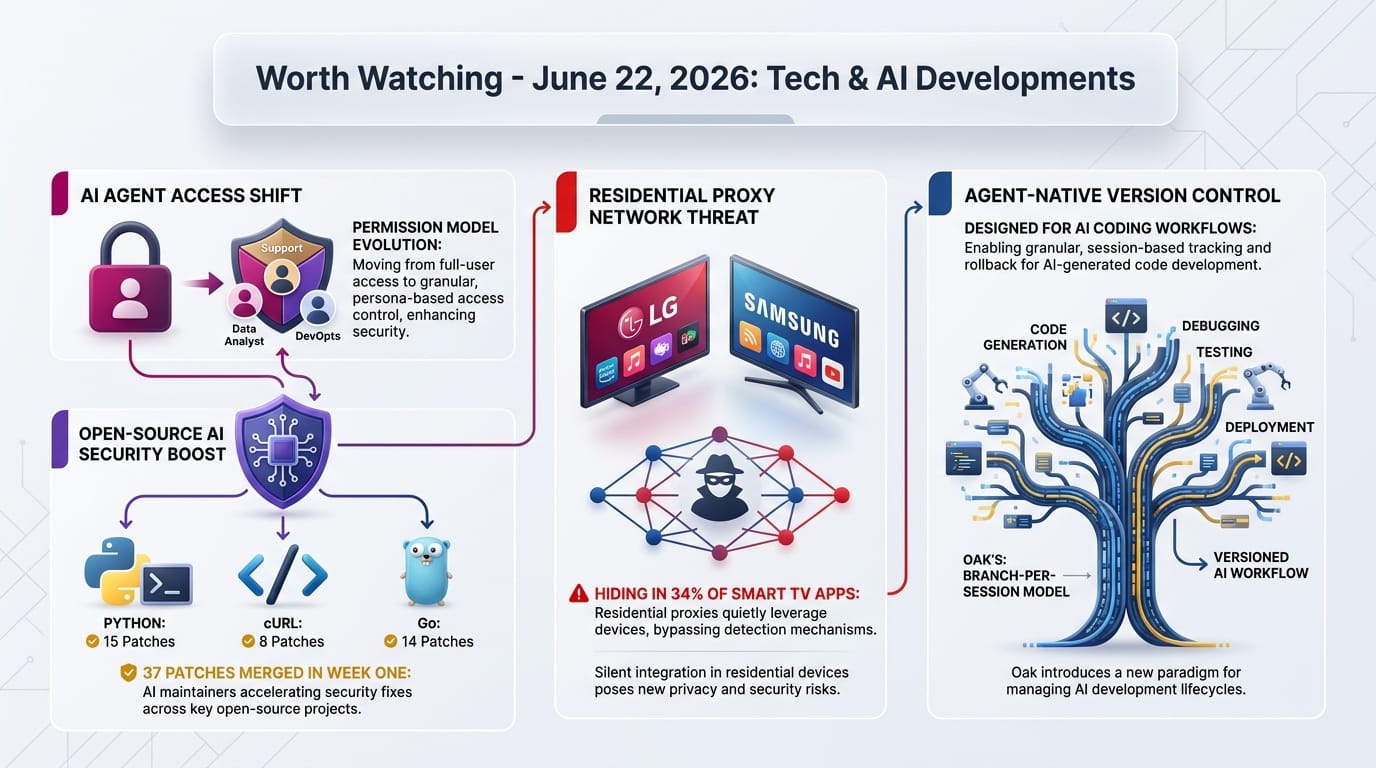
Gray Swan's Zico Kolter describes current default agent permissions as "a disaster." The field is shifting toward persona-based access control, where agents maintain separate profiles for different contexts. This will fundamentally change how AI coding assistants, email agents, and browser automation tools request and receive access. If adopted broadly, expect every AI tool to start asking for specific, limited permissions instead of blanket access.
Patch the Planet's first-week results (37 merged patches across 19 projects) suggest AI can meaningfully accelerate the patch cycle for underfunded open-source projects. If this scales, it could close the window attackers exploit between disclosure and fix. Watch for whether maintainer burden actually decreases or if AI-generated patches create new review overhead.
The Spur research reveals a business model where the app is secondary and your residential IP address is the product. LG and Samsung have no public policy against this. If regulators or platforms don't act, expect this model to spread to other always-on consumer devices - routers, smart speakers, security cameras.
Oak's approach - branch-per-session, lazy hydration, structured JSON output, stable exit codes - represents a ground-up rethink of version control for AI workflows. If coding agents become the primary authors of code (some estimates suggest 50%+ by 2027), the version control system they use may matter more than developer preferences.
📜 License: MIT · 👤 By: Garry Tan (Y Combinator CEO)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Battle-tested workflows from YC's engineering culture | Opinionated - may conflict with existing team processes |
| Covers full sprint cycle from planning to shipping | 23 tools is a lot to learn at once |
| MIT license, optional telemetry (off by default) | Primarily TypeScript - less useful for non-JS projects |
📜 License: Apache 2.0 · 👤 By: Mahipal Jangra (individual)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 754/754 ATT&CK techniques validated and mapped | "Anthropic" in name is misleading - community project |
| Compatible with 26+ AI coding platforms | Some skills may need customization for specific environments |
| Progressive disclosure (30 tokens to scan, 500-2K for full workflow) | Requires security domain knowledge to use effectively |

📜 License: MIT · 👤 By: DeusData (startup)
🎯 Time to value: 3 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Sub-millisecond query performance | Adds another service to manage alongside your IDE |
| Works with any MCP-compatible AI tool | Codebase indexing takes time on first run |
| Persistent across sessions | Still early-stage with limited documentation |

📜 License: Not specified · 👤 By: HeyGen (company)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Agents can produce video using only HTML skills | Limited to template-based video styles |
| Integrates into existing web development workflows | Quality depends on HTML/CSS design quality |
| Built by HeyGen (established AI video company) | Requires rendering infrastructure for production use |
📜 License: MIT · 👤 By: ZhuLinsen (individual)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Free to run via GitHub Actions | Stock analysis ≠ stock advice (no guarantee of returns) |
| Multi-market coverage (5 markets) | Advanced metrics limited for Japan/Korea markets |
| Supports 15+ built-in analysis strategies | Requires API keys for LLM and market data providers |

📜 License: Not specified · 👤 By: ByteDance (company)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Handles genuinely long-horizon, multi-step tasks | Complex setup for simple use cases |
| Backed by ByteDance's engineering resources | Potential data privacy concerns given ByteDance ownership |
| Open-source with active development | Resource-intensive for extended workflows |
📜 License: Not specified · 👤 By: lyogavin (individual)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Run 70B models on consumer GPUs (4GB VRAM) | Inference speed is significantly slower than full-VRAM setups |
| No cloud costs or data privacy concerns | Not suitable for real-time applications |
| Simple pip install and Python API | Quality may vary compared to proper quantization methods |
👤 By: Z.ai · 🎯 Task: Text Generation
📐 Size: 753B
| ✓ Pros | ✗ Cons |
|---|---|
| Strongest open model on multiple benchmarks | Evidence of Claude distillation limits novelty |
| MIT license, excellent long-context handling | No native vision capability |
| Competitive with frontier models on coding tasks | Excessive verbosity increases output costs |

👤 By: yuxinlu1 (community) · 🎯 Task: Text Generation
📐 Size: 12B
| ✓ Pros | ✗ Cons |
|---|---|
| Runs on consumer hardware (12B, GGUF quantized) | Community fine-tune, not officially supported |
| Combines Gemma 4 + Fable 5 training approaches | Narrowly focused on coding tasks |
| Free to download and use | Performance gap vs. full-size frontier models |

👤 By: yuxinlu1 (community) · 🎯 Task: Text Generation
📐 Size: 12B
| ✓ Pros | ✗ Cons |
|---|---|
| Optimized for agentic workflows (tool calling, multi-step) | Very new, limited community testing |
| Runs locally on consumer GPUs | Agentic capabilities unverified on hard benchmarks |
| Built on proven Gemma 4 architecture | May hallucinate tool calls more than larger models |

👤 By: MiniMax (company) · 🎯 Task: Image-Text-to-Text
📐 Size: 427B
| ✓ Pros | ✗ Cons |
|---|---|
| True multimodal (image + text) at 427B scale | Requires significant compute to run |
| Strong multilingual performance | Less community tooling than Llama/Gemma ecosystem |
| Open weights from established AI lab | Download size is substantial |

👤 By: NVIDIA · 🎯 Task: Automatic Speech Recognition
📐 Size: 0.6B
| ✓ Pros | ✗ Cons |
|---|---|
| Streaming-capable for real-time use | Limited to speech recognition (no TTS) |
| Small enough for edge deployment (0.6B) | NVIDIA ecosystem dependency for optimal performance |
| From NVIDIA's established Nemotron family | Newer model with limited community benchmarks |

💰 Pricing: Free · 🏷 Category: Developer Tools
wrangler deploy --temporary to create functional Workers with live URLs instantly, bypassing all authentication. Workers auto-expire after 60 minutes. Agents can loop during the window: deploy, test, redeploy, verify. Verdict: A genuinely novel approach to removing auth barriers for agent workflows - useful today for any team building AI-powered deployment pipelines. Previously: Covered June 20 as a Top Story. Still trending on Product Hunt.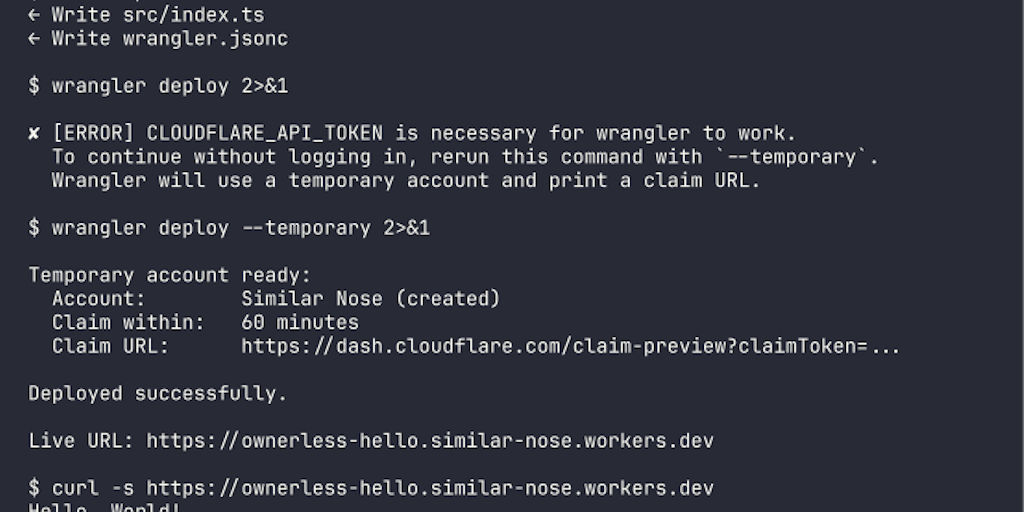
💰 Pricing: Free tier + 70% launch discount · 🏷 Category: Developer Tools
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | 1M |
| OpenAI | GPT-5.4 | $2.50 | $15.00 | 1M |
| OpenAI | GPT-5.4-nano | $0.20 | $1.25 | 128K |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M | |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | |
| Open-weight | GLM-5.2 (via API) | $1.40 | $4.40 | 1M |
Key finding: Retrieving trajectories from the shared repository improves downstream task performance and reduces interaction steps without requiring coordination or joint training between agents.
Why practitioners should care: For teams deploying multiple AI agents across diverse tasks, MATM offers a scalable pattern for institutional knowledge sharing. Instead of each new agent rediscovering solutions from scratch, it can learn from what previous agents already figured out - essentially giving AI agents organizational memory.