Watch today's digest as a video summary (generated by NotebookLM)
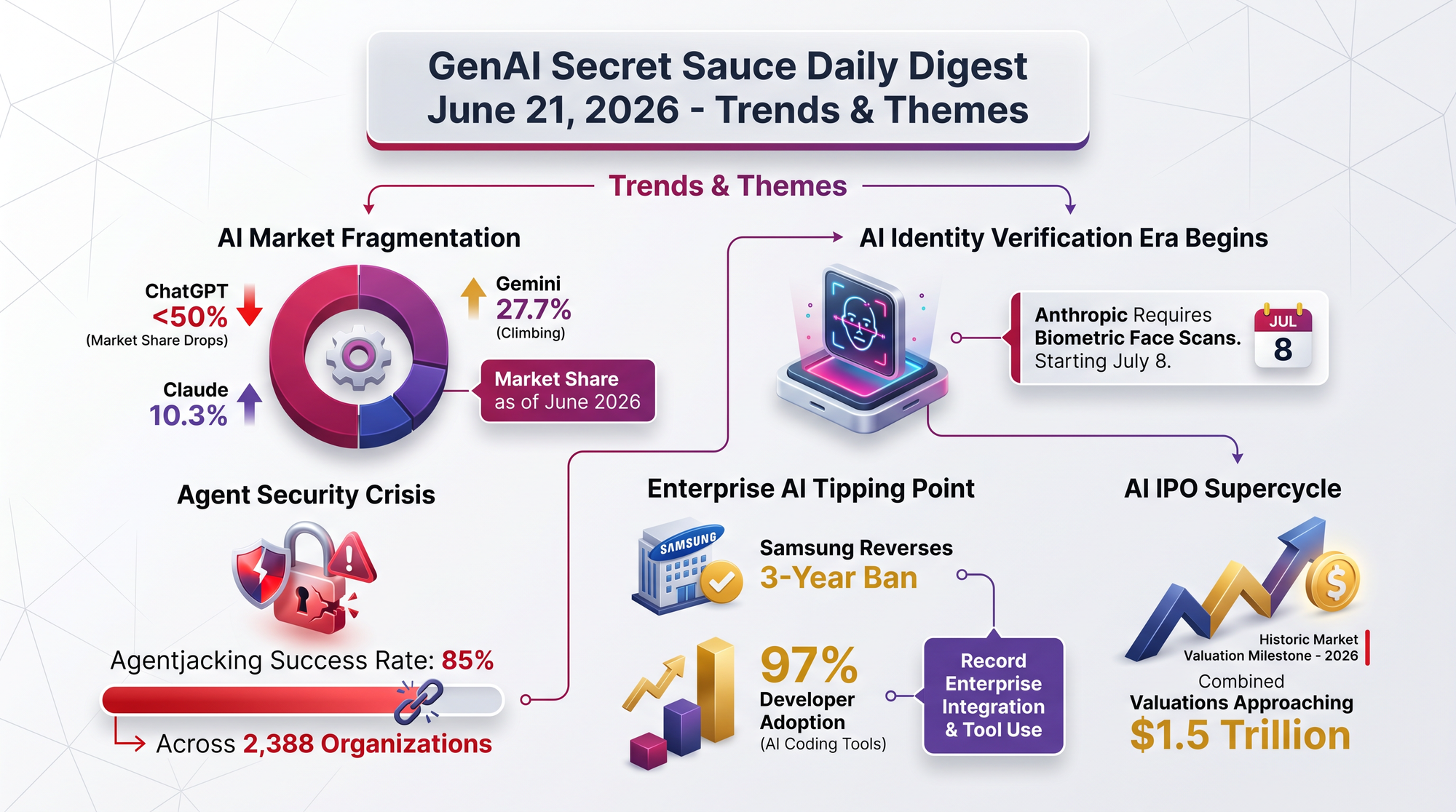
Cloudflare launched Temporary Accounts, a feature that lets AI agents deploy serverless code instantly using wrangler deploy --temporary. No sign-up, no OAuth (the multi-step login process most websites use), no multi-factor authentication. The agent gets a working deployment in seconds.
The blog post is blunt about the motivation: "background AI sessions have no human in the loop" and friction "risks driving agents toward competitor platforms." This is one of the first major cloud providers explicitly designing authentication flows for AI agents rather than humans.
- Accounts last 60 minutes and auto-delete if nobody claims them
- Agents can redeploy multiple times within the window, enabling rapid trial-and-error
- A "claim URL" lets a human convert any temporary deployment into a permanent one
- Wrangler prompts agents about the temporary flag via system messages, making the feature discoverable to AI tools automatically
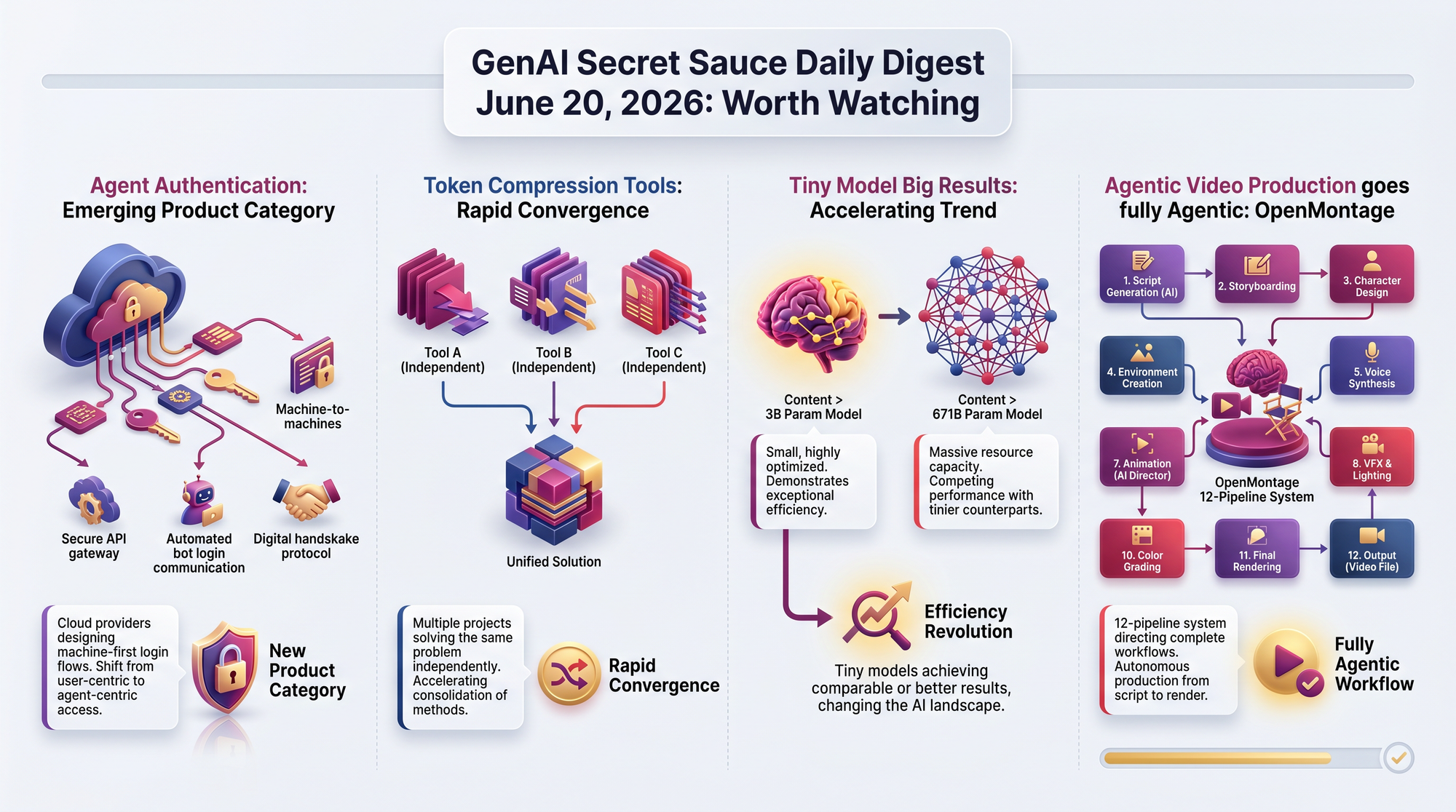
WeiboAI released VibeThinker-3B, a model with just 3 billion parameters that achieves results competitive with models 200 times its size. On IMO-AnswerBench (a test using 400 problems from the International Mathematical Olympiad), it scored 76.4%, rising to 80.6% with an answer-verification strategy. It passed 96.1% of recent LeetCode coding challenges.
The developers argue that "compact models may carry near-frontier reasoning capabilities" when focused on problems that have objectively verifiable answers. This has significant cost implications: running a 3B model costs roughly 100x less than running a 671B model.
- Competes with DeepSeek V3.2 (671 billion parameters) on reasoning tasks - while being small enough to run on a laptop
- Four-stage training pipeline including reinforcement learning with diversity-preserving techniques
- Built on Qwen2.5-3B as the base model, then specialized for verifiable reasoning in math, coding, and science
- MIT licensed - anyone can download and use it commercially
ArgusRed, built by Cosine, is a command-line security tool with a model specifically post-trained to find and exploit vulnerabilities rather than politely refusing. Most AI models are trained to avoid helping with anything that looks like hacking. ArgusRed inverts this: it was trained to excel at it, with safety enforced at the infrastructure level instead.
The approach of making the model capable and enforcing safety through infrastructure rather than training represents a fundamentally different philosophy from the "refusal training" used by most AI companies.
- Two modes: scan mode (read-only code analysis) and pen test mode (active exploitation of authorized targets)
- Scans 1.5 million lines of code in ~40 minutes - a task that would take a human security team days
- Safety is enforced by a Go-based binary harness, not by asking the model nicely. Scan mode physically cannot write files; pen test mode physically cannot access unauthorized network targets.
- Free to install on macOS and Linux with 2 million tokens included for initial scans

The pattern is clear: 2025 was about making AI agents that can write code. 2026 is about building the infrastructure so those agents can actually ship it. When the cloud provider starts designing sign-up flows for machines, the agent economy has moved from concept to infrastructure.
- Cloudflare's temporary accounts let agents deploy code with zero human authentication
- Stripe and WorkOS partnerships are enabling automated account provisioning protocols for agent identity
- The codebase-memory-mcp project (9,300 stars, +1,267 today) gives agents persistent knowledge about code without re-analyzing files every time
The economics matter here. Running a 3B model costs roughly $0.001 per task. Running a 671B model costs roughly $0.10. When the small model handles 96% of coding challenges correctly, the 100x cost difference becomes hard to justify for most applications.
- VibeThinker-3B (3 billion parameters) competes with DeepSeek V3.2 (671 billion parameters) on math olympiad problems
- Microsoft's FastContext (4 billion parameters) sometimes outperforms its own 30-billion-parameter sibling on code exploration
- NVIDIA's Nemotron 3.5 ASR (0.6 billion parameters) delivers real-time speech recognition in a package small enough for edge devices
Three separate projects tackling the same problem - agent token waste - suggests this is becoming a recognized bottleneck. The tools that use AI are now spawning their own ecosystem of tools that make AI cheaper to use.
- Headroom (covered June 19) gained another 3,800 stars today (41,700 total), compressing agent context by 60-95%
- Microsoft found that 56.2% of coding agent tool calls are just reading and searching files - their FastContext subagent cuts this waste by 60%
- Codebase-memory-mcp reduces token consumption by 99.2% compared to file-by-file code exploration
- The napkin math analysis on inference costs shows self-hosted Large Language Models (LLMs) cost roughly $9.36/user/month at scale - but only with aggressive optimization
The shift is from "AI generates an image" to "AI directs a production." OpenMontage's agent orchestrates scriptwriting, asset generation, editing, quality review, and rendering as a complete workflow. Palmier Pro lets an AI agent be a collaborator in your video editing session.
- Palmier Pro (macOS video editor, +904 stars today) exposes an MCP server so Claude and Cursor can edit video projects
- OpenMontage (7,000 stars, +677 today) is the first open-source system where an AI agent directs the entire video production pipeline - 12 pipelines, 52 tools, 14 video generation providers
- Voicebox (31,000 stars) runs voice cloning, TTS in 23 languages, and an MCP server for agents to speak in cloned voices - all locally on your machine
- Parallel Box Decoding predicts bounding boxes in one step instead of token-by-token, achieving 2.5x higher throughput
- Trained on 12 million images with 138 million queries across scenes, robotics, driving, GUI, and documents
- Processes images up to 2.5K resolution with prompts up to 24K tokens
- 236,000 downloads and 2,210 likes on HuggingFace
- Structured "ledger" of state gives agents clear context about permitted actions at each step
- Addresses production deployment challenges where agents must comply with security policies and regulations
- Policy adherence across multi-step interactions - the hard problem of agent governance
- Selective verification outperforms uniform approaches under tight budgets
- Different strategies win at different budget levels - adaptive allocation is key
- Directly relevant to production deployments of reasoning models like o3 and Fable
- Extends LiveCodeBench to multiple programming languages (ICLR 2026)
- Addresses a blind spot where models optimized for Python benchmarks may underperform in production polyglot development
- Enables fair cross-language comparison of coding models
Astro, the company behind the popular web framework, released Flue - a TypeScript framework for building autonomous AI agents. It is notable because Astro's expertise is in static site generation, not AI. Flue includes sandboxed execution, durable state, subagent delegation, and deploys to Cloudflare Workers. When web framework companies start building agent infrastructure, it signals that agent development is becoming a standard expectation from developer platform companies.
Matt Pocock's repository of Claude Code skills from his .claude directory now has 138,144 stars - making it one of the most-starred repositories on all of GitHub. It gained 1,360 stars today. This is essentially a "dotfiles" repository for AI-assisted development, and its popularity reflects how many developers are now configuring AI coding agents as a core part of their workflow.
ClickHouse released an open benchmark for managed PostgreSQL services. Their own offering achieved 28,668 transactions per second versus AWS Aurora's 12,628 TPS. The decisive factor: NVMe storage co-located with compute versus shared network storage. While the benchmark is from an interested party, all data and methodology are publicly reproducible.
Microcrad reimplements Andrej Karpathy's micrograd entirely in C with zero external dependencies. Every number becomes a node in a computation graph, every operation records how it was produced, and the backward pass computes derivatives via the chain rule on individual scalars. It includes an MNIST classifier that works. A reminder that the fundamentals of neural networks are elegant enough to express in 36-star repositories.
Cloudflare's temporary accounts are not an isolated feature. Combined with Stripe and WorkOS partnerships on automated provisioning protocols, a pattern emerges: the authentication layer of the internet is being rebuilt for AI agents. If this plays out, agents will have their own identities, credentials, and billing relationships - separate from the humans who deploy them. The question is who controls the identity layer.
Headroom (context compression), codebase-memory-mcp (knowledge graph indexing), and FastContext (specialized exploration subagent) all target the same bottleneck: AI agents waste most of their tokens on overhead. When three independent teams converge on the same problem simultaneously, it usually means the problem just became urgent enough to spawn a market.
VibeThinker-3B's performance on IMO-AnswerBench (76-80% accuracy at 3B parameters vs. comparable scores from models 200x larger) suggests that focused training on verifiable domains may be more important than raw scale. If this generalizes, the cost of capable AI drops by two orders of magnitude for specific applications. Watch for more task-specific small models emerging from research labs and startups.
OpenMontage's 12-pipeline, 52-tool architecture represents a qualitative shift from "AI generates a clip" to "AI produces a video." If production quality reaches professional standards, the economics of video content creation change fundamentally. A solo creator with an agent could match the output of a small production studio.
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Produces apps 10-20x smaller than Electron | Limited to what the webpage itself offers |
| Native OS integration (dock, notifications) | Some web features may not work in the wrapper |
| One-command setup, no coding required | macOS, Windows, Linux only - no mobile |

📜 License: Apache 2.0 · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 92% compression on real-world code searches | Adds a processing step that increases latency slightly |
| Works with Claude Code, Codex, Cursor, Aider | Requires configuration per agent |
| Reversible - originals cached for retrieval | Cache management adds storage overhead |
📜 License: Not specified · 👤 By: Individual developer (TypeScript educator)
🎯 Time to value: 2 minutes
.claude directory. Provides real-world examples of how a power user configures Claude Code for TypeScript development workflows. Why you'd want it: If you use Claude Code and want proven skill configurations to copy into your own setup - think of it as dotfiles for AI-assisted development.| ✓ Pros | ✗ Cons |
|---|---|
| Real-world configurations from a power user | Focused on TypeScript workflows specifically |
| Copy-paste ready for immediate use | May need adaptation for other languages |
| Continuously updated as practices evolve | No documentation beyond the files themselves |
📜 License: MIT · 👤 By: DeusData (startup)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 99.2% token reduction vs file-by-file exploration | Initial indexing takes a few minutes for large repos |
| Sub-millisecond queries, 158 languages | Knowledge graph may miss dynamic code patterns |
| Single binary, zero runtime dependencies | Focused on structure, not semantic understanding |

📜 License: GPLv3 · 👤 By: Palmier Inc. (YC S24)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| AI agents can edit video through MCP | Requires macOS 26 on Apple Silicon only |
| Free editing core, no login required | AI generation features require subscription |
| Native Swift performance | Limited to macOS ecosystem |
📜 License: BSL · 👤 By: Turso (company)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Drop-in SQLite compatibility | Business Source License limits commercial hosting |
| Built-in replication and branching | Smaller ecosystem than PostgreSQL |
| Edge deployment ready | Some advanced SQL features not yet supported |
📜 License: AGPLv3 · 👤 By: Individual developer
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Complete pipeline from script to render | Complex setup with many provider integrations |
| Zero-cost baseline with free tools | AGPLv3 requires sharing modifications |
| Auditable decision trails for every choice | Quality depends heavily on which AI providers you connect |
📜 License: MIT · 👤 By: Kilo-Org (community)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 500+ models with mid-task switching | Feature overlap with Claude Code, Cursor, etc. |
| Works in VS Code, JetBrains, CLI, and cloud | Many features = steeper learning curve |
| MIT license, fully open source | Community-maintained, not backed by a major lab |
👤 By: Individual · 🎯 Task: Text Generation
📐 Size: 12B
| ✓ Pros | ✗ Cons |
|---|---|
| Runs locally via llama.cpp | Community model, not officially supported |
| Incorporates Fable 5 distillation | Quality may not match the source model |
| Small enough for consumer hardware | GGUF quantization trades some accuracy for speed |

👤 By: Z.ai · 🎯 Task: Text Generation
📐 Size: 753B
| ✓ Pros | ✗ Cons |
|---|---|
| #1 on Design Arena, #2 on WebDev Arena | 753B total parameters requires significant hardware |
| MIT license, no restrictions | MoE (mixture-of-experts) architecture can be tricky to deploy efficiently |
| 1M token context window | Newer than competitors, less community tooling |

👤 By: MiniMax AI · 🎯 Task: Image-Text-to-Text
📐 Size: 427B
| ✓ Pros | ✗ Cons |
|---|---|
| 427B parameters - frontier-scale and open | Massive size requires enterprise hardware |
| True multimodal (image + text) | Less community support than Llama/Qwen |
| 85,800 downloads indicate reliability | Limited documentation compared to major labs |

👤 By: WeiboAI · 🎯 Task: Text Generation
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| Runs on consumer hardware (3B params) | Specialized for verifiable reasoning only |
| 96.1% LeetCode pass rate | Not designed for general conversation |
| MIT license, fully open | Limited multilingual support |

👤 By: Microsoft · 🎯 Task: Text Generation
📐 Size: 4B
| ✓ Pros | ✗ Cons |
|---|---|
| 60% token reduction for coding agents | Requires integration with existing agent setup |
| 4B model sometimes beats 30B | New release, limited production validation |
| MIT license | Focused specifically on code exploration |

👤 By: NVIDIA · 🎯 Task: Image-Text-to-Text
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| 2.5x throughput via Parallel Box Decoding | Non-commercial license only |
| 138M training queries, very robust | Requires specific hardware setup |
| Covers natural, GUI, document, driving scenes | 3B size limits deployment flexibility vs. cloud |

| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Fable 5 | $10.00 | $50.00 | 1M |
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200k |
| Gemini 3.5 Flash | $1.50 | $9.00 | N/A | |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | N/A | |
| Gemini 2.5 Pro | $1.25 | $10.00 | N/A | |
| Gemini 2.5 Flash | $0.30 | $2.50 | N/A | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | N/A | |
| Groq | GPT OSS 20B | $0.075 | $0.30 | 128k |
| Groq | GPT OSS 120B | $0.15 | $0.60 | 128k |
| Groq | Llama 4 Scout | $0.11 | $0.34 | 128k |
| Groq | Qwen3 32B | $0.29 | $0.59 | 131k |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128k |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | 128k |
Key finding: Under tight compute budgets, selectively verifying only uncertain answers outperforms both "verify everything" and "think longer on everything" approaches by 15-20% on reasoning benchmarks.
Why practitioners should care: If you run reasoning models in production and pay per token, this research directly translates to cost savings. Instead of uniformly applying expensive verification or extended thinking, you can allocate compute where it matters most - on the answers the model is least confident about.