Watch today's digest as a video summary (generated by NotebookLM)
Cursor, the AI-powered code editor with millions of users, revealed it is training a model with more than 1.5 trillion parameters across 100,000 GPUs (Graphics Processing Units - the specialized chips that power AI training). This puts a tool company in the same league as frontier AI labs in terms of raw model scale.
The move follows a pattern: Cursor's recent "/automate" feature already lets users configure agents with natural-language instructions and Slack/GitHub triggers. A proprietary model would let them optimize every interaction for coding without depending on external providers.
- 1.5T+ parameters makes this one of the largest models currently in training, rivaling GPT-5.5 and Gemini 3
- Purpose-built for coding - unlike general-purpose models, this is designed specifically for software development tasks
- Signals a shift where the companies building AI tools are no longer content to rent capabilities from labs - they want to own the intelligence layer
DeepSeek, the Chinese AI lab that shocked the industry in early 2025 by building competitive models at dramatically lower cost, has raised $7.5 billion in new funding. The $50 billion valuation places it among the most valuable AI companies in the world.
- $7.5 billion is one of the largest private AI funding rounds ever
- DeepSeek V4 Pro recently made its 75% price cut permanent, with the model now costing $0.04 per typical task
- The funding validates the "efficiency-first" approach to AI - proving that throwing more money at bigger models isn't the only path forward
> Previously: June 13 - The White House imposed export controls on Anthropic's Fable 5 and Mythos 5 models, pulling them from every customer worldwide.
Today: Three significant developments mark day ten of the crisis. First, both the Senate and House have drafted FY27 NDAA (National Defense Authorization Act) provisions that would add procedural guardrails to Defense Department supply-chain authorities and explicitly bar their use as negotiation leverage - a direct rebuke of how the Fable situation was handled.
- The "jailbreak" was asking the model to fix code - the vulnerability that triggered the export controls was simply requesting Fable to identify security weaknesses, which every other frontier model (including GPT-5.5 and Opus 4.8) also does
- Zvi Mowshowitz argues the fix is mathematically impossible - you cannot distinguish between "find bugs in my code" (defensive) and "find exploits in this code" (offensive) at the classifier level without destroying the model's coding ability
- Joshua Achiam (OpenAI) warns the Fable dispute could normalize digital citizenship verification requirements across all software, creating a dangerous precedent for state control of AI access
- Odds of resolution by July 1 are "slightly under even money" according to Mowshowitz
The AA-Briefcase benchmark puts AI agents through multi-week project evaluations with more than 1,000 fragmented inputs - the kind of messy, real-world context that actual knowledge workers deal with daily. The results are humbling.
- Claude Fable 5 leads with 1,587 Elo but satisfies rubrics on only 3% of tasks
- GLM-5.2 ranks as the strongest open model at 1,266 Elo
- 1,000+ fragmented inputs simulate the reality of projects where context is scattered across documents, emails, and conversations
- The gap between demo performance and real-world performance is the largest ever measured in agentic AI
Liminal Capital estimates that AI contributed $1.26 trillion in annual economic value as of the end of 2025. The United States alone accounted for $878 billion of that total (70%), with a 95% confidence interval of $602 billion to $1.155 trillion.
- $1.26 trillion globally - the first credible, sourced estimate of AI's total economic contribution
- $878 billion in the US alone - roughly 3.5% of US GDP
- Growth is accelerating - the figure reflects deployment across healthcare, finance, software development, and customer service
- The number may still be conservative as it doesn't fully capture productivity gains from individual AI tool usage
Try it: GitHub
- 12 production pipelines covering research, scripting, asset generation, editing, and rendering
- 500+ agent skills orchestrated through Claude, Cursor, and Copilot
- AGPL-3.0 license - fully open source with copyleft protections
- Works with both AI-generated visuals and real stock footage
- "Omni" mode generates full 4K video
- Improved lip-sync for talking-head content
- Lower per-generation costs and faster turnaround times
- Faster generation speeds across all quality tiers
A research paper covered by Two Minute Papers proposes that AI agents should communicate using raw latent representations (the internal mathematical signals models use to process information) instead of converting everything to English text. When multiple agents collaborate, translating between text and internal representations at each step loses information and slows everything down.
- Skipping the text translation step preserves information that would otherwise be lost
- Faster collaboration between agents because they don't need to encode and decode at each handoff
- Trade-off: humans can't inspect what the agents are saying to each other, raising transparency concerns
- 225B total parameters, 23B active using a sparse Mixture-of-Experts architecture
- 70 layers with 256 experts - optimized for agentic coding workflows
- Apache 2.0 license - no restrictions on commercial use
- Designed for long-horizon tasks where the agent needs to maintain context over extended problem-solving sessions
- 8.5x to 13x faster replay of previously successful agent workflows
- Converts trial-and-error into deterministic procedures - the agent explores once, then the solution becomes a repeatable recipe
- Addresses a key efficiency problem - agents currently re-discover solutions from scratch each time
- 12-23% more reasoning tokens than needed are generated by compressed (quantized) models
- 52% of failures involve the model finding the correct answer partway through, then changing its mind
- A simple logit penalty on hesitation words ("wait," "but," "alternatively") fixes the problem without any retraining
- Works across five models from 1.5 billion to 32 billion parameters
AI researchers created a benchmark testing classical Christian virtues - prudence, justice, courage, and temperance - in AI models. Claude Fable 5 scores high on prudence and justice but only 77% on courage and 88% on temperance. The philosophical question of whether AI can or should exhibit virtues is suddenly a measurable empirical question.
In his latest timeline estimates, Scott Alexander puts a 25% chance on AGI (Artificial General Intelligence) arriving by 2027 and 50% by 2034. His median estimate for the gap between human-level AI and superhuman AI is less than 4 years. Most strikingly, he estimates a 20% chance that the first superintelligent AI would want to eliminate humanity given current safety efforts - and a 50% chance there would be a warning shot before a point of no return.
A Hacker News thread asking whether anyone has successfully replaced cloud-based AI coding tools with locally-run models drew significant engagement. The answers reveal that while local models are improving rapidly, most developers still find cloud models meaningfully better for complex tasks - but the gap is closing fast enough that several commenters reported switching for privacy-sensitive work.
Norway became one of the first countries to impose a near-complete ban on AI tools in elementary education. The policy affects schools nationwide and represents the strongest government stance yet against AI in K-12 education.
If tool companies can train competitive models while also controlling the user experience, they have both the data advantage (they see how people actually code) and the distribution advantage (they already have the users). The labs become API providers - important but commoditized. Watch whether other tool companies (Replit, Vercel, GitHub) follow Cursor's lead.
The NDAA provisions being drafted would create procedural requirements before defense supply-chain authorities can be used against AI companies. If passed, this would be the first concrete legislative response to the Fable crisis and could set the template for how future AI restrictions are handled. The bipartisan support makes passage likely.
Enterprise AI vendors have been selling agent capabilities based on demo-friendly benchmarks. AA-Briefcase's multi-week, 1,000-input evaluations are closer to what enterprise buyers actually need. If this benchmark gets adopted as a standard, some companies will need to dramatically revise their claims.
The finding that Qwen3-14B went from 100% to 0% accuracy when given CLI documentation means agent builders can't just "add more context." The implication: agent-facing APIs need to be tested across model sizes, and what works for GPT-5.5 may actively harm smaller models that many users rely on.
The biggest obstacle to trusting AI agents in production is their unpredictability. PreAct's approach - let the agent explore once, then freeze the successful path into a replayable recipe - could be the bridge between "AI that sometimes works" and "AI you can depend on."
📜 License: Apache-2.0 · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 60-95% token reduction with accuracy preservation | New project - limited production battle-testing |
| Multiple integration modes (library, proxy, MCP) | Compression adds latency to each request |
| Apache-2.0 license, no restrictions | May not preserve nuance in highly technical contexts |
📜 License: Apache-2.0 · 👤 By: Google Research
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Works out of the box on diverse time-series data | Requires understanding of time-series data formats |
| Generates confidence intervals, not just point estimates | Large model size may be overkill for simple forecasting |
| Apache-2.0 from a major research lab | Limited to univariate forecasting in current release |

📜 License: MIT · 👤 By: Prime Radiant (company)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Works with Claude Code, Cursor, and Copilot | Adds overhead to simple tasks that don't need full process |
| MIT license, 233K+ stars, active community | Opinionated methodology may clash with team workflows |
| Measurably reduces code review cycles | Requires initial setup and learning the framework's approach |
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Supports 158 languages via tree-sitter | Indexing large codebases takes significant time and memory |
| Millisecond query responses after initial indexing | Requires MCP-compatible client (Claude Code, etc.) |
| MIT license, works as background service | Knowledge graph can become stale if not re-indexed |

📜 License: Apache-2.0 · 👤 By: Zhipu AI (research lab)
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| MIT-licensed frontier-class coding model | Requires substantial GPU infrastructure |
| 1M-token context with efficient sparse attention | Brand new - limited community tooling so far |
| Competitive with Opus 4.8 on multiple benchmarks | Quantized variants not yet independently verified |
📜 License: AGPL-3.0 · 👤 By: Individual developer
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Complete pipeline from concept to rendered video | AGPL license requires sharing modifications |
| Works with multiple AI agent platforms | Complex setup with many dependencies |
| Both AI-generated and stock footage support | Quality varies significantly by input clarity |
📜 License: MIT · 👤 By: Builder.io (company)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Solves the human+agent UI problem elegantly | New framework - small ecosystem |
| MIT license from established company (Builder.io) | Requires rethinking existing UI architecture |
| Reduces agent token consumption vs scraping HTML | Limited to web applications |
📜 License: Apache-2.0 · 👤 By: Lightricks (company)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Combined audio + video generation in one model | Requires significant GPU memory for generation |
| LoRA training for style customization | Audio quality lags behind dedicated TTS models |
| Apache-2.0 license with commercial use allowed | Generation times can be lengthy for high-quality output |
👤 By: Z.ai (Zhipu AI) · 🎯 Task: text-generation
📐 Size: 753B (MoE)
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license with no regional restrictions | 753B parameters requires substantial GPU infrastructure |
| 1M-token context with stable long-horizon performance | Brand-new release with limited community fine-tunes |
| Near-perfect math scores (AIME 2026: 99.2) | Quantized quality unverified by third parties |

👤 By: MiniMax AI · 🎯 Task: multimodal
📐 Size: 428B/23B active
| ✓ Pros | ✗ Cons |
|---|---|
| True multimodal (text + image + video) | Custom license may restrict some commercial uses |
| 9x prefill speedup at 1M context | 428B total params still requires significant hardware |
| Only 23B active parameters per query | Smaller community than competing multimodal models |

👤 By: Moonshot AI · 🎯 Task: text-generation (code)
📐 Size: 1T/32B active
| ✓ Pros | ✗ Cons |
|---|---|
| Apache-2.0 license, 1T scale for coding | Requires multi-GPU setup for full-precision inference |
| 384 experts provide deep specialization | Coding-focused means weaker at general knowledge tasks |
| Multimodal support for UI/design understanding | New release with limited benchmark verification |

👤 By: Google DeepMind · 🎯 Task: text-generation
📐 Size: 25.2B/3.8B active
| ✓ Pros | ✗ Cons |
|---|---|
| 1,100+ tokens/sec with 3.8B active params | Diffusion approach has quality trade-offs vs autoregressive |
| Apache-2.0 from Google DeepMind | Newer architecture with less community tooling |
| Only 3.8B active params - runs on consumer GPUs | Not yet proven across diverse generation tasks |
👤 By: DeepSeek AI · 🎯 Task: text-generation
📐 Size: 1.6T/49B active
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license, 3M+ monthly downloads | 1.6T total requires enterprise hardware for full model |
| $0.04 per task via API - 25x cheaper than alternatives | Chinese-developed model may face future export restrictions |
| 1M context window, strong reasoning scores | Quantized variants trade quality for accessibility |

👤 By: NVIDIA · 🎯 Task: visual-grounding
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| 2.5x faster than sequential localization methods | Non-commercial license limits business use |
| Only 3B params - runs on consumer hardware | Specialized to localization, not general vision |
| From NVIDIA with strong computer vision heritage | Limited to static images, not video streams |

👤 By: Cohere Labs · 🎯 Task: text-generation (code)
📐 Size: 30B/3B active
| ✓ Pros | ✗ Cons |
|---|---|
| 67.6% SWE-Bench with only 3B active params | Coding-specialized, weaker at general tasks |
| Apache-2.0, runs on consumer hardware | 30B total still needs ~16GB VRAM for quantized inference |
| From Cohere with enterprise support available | Fewer experts than larger MoE models limits ceiling |
👤 By: Microsoft · 🎯 Task: text-generation (code)
📐 Size: 4B
| ✓ Pros | ✗ Cons |
|---|---|
| 60% token reduction for main agent | Only useful as part of a multi-agent setup |
| Actually improves resolution rates | 4B model may miss nuance in complex codebases |
| MIT license, runs on minimal hardware | Requires orchestration layer to coordinate with main agent |
💰 Pricing: Freemium · 🏷 Category: AI Coding

💰 Pricing: Paid · 🏷 Category: AI Agents / Messaging
💰 Pricing: Freemium · 🏷 Category: AI Research
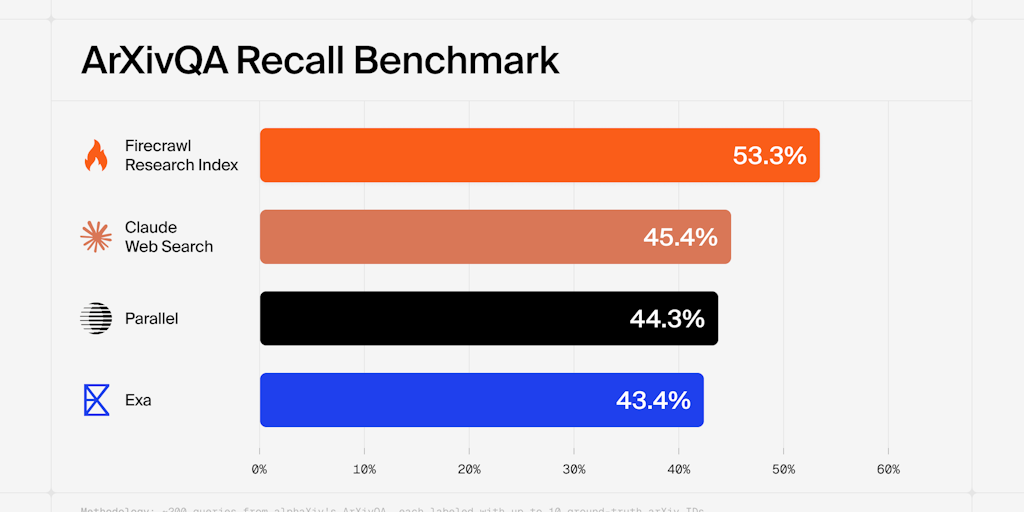
💰 Pricing: Freemium · 🏷 Category: Developer Tools
💰 Pricing: Free · 🏷 Category: AI Analytics

| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Fable 5 | $10.00 | $50.00 | 1M |
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | 1M |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 1M |
| OpenAI | o4-mini | $1.10 | $4.40 | 200K |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M | |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | 1M | |
| Groq | Kimi K2 Instruct | $1.00 | $3.00 | 128K |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | 128K |
Key finding: A training-free logit penalty on overthinking tokens ("wait," "but," "alternatively") reduces reasoning length by 12-23% and cuts overthinking errors by up to 58% across five models from 1.5B to 32B parameters.
Why practitioners should care: Anyone deploying quantized reasoning models - the standard approach for cost-efficient inference - gets an immediate, zero-training fix that saves compute and improves accuracy simultaneously. The insight that compressed models find correct answers then abandon them is directly actionable in production.