Watch today's digest as a video summary (generated by NotebookLM)
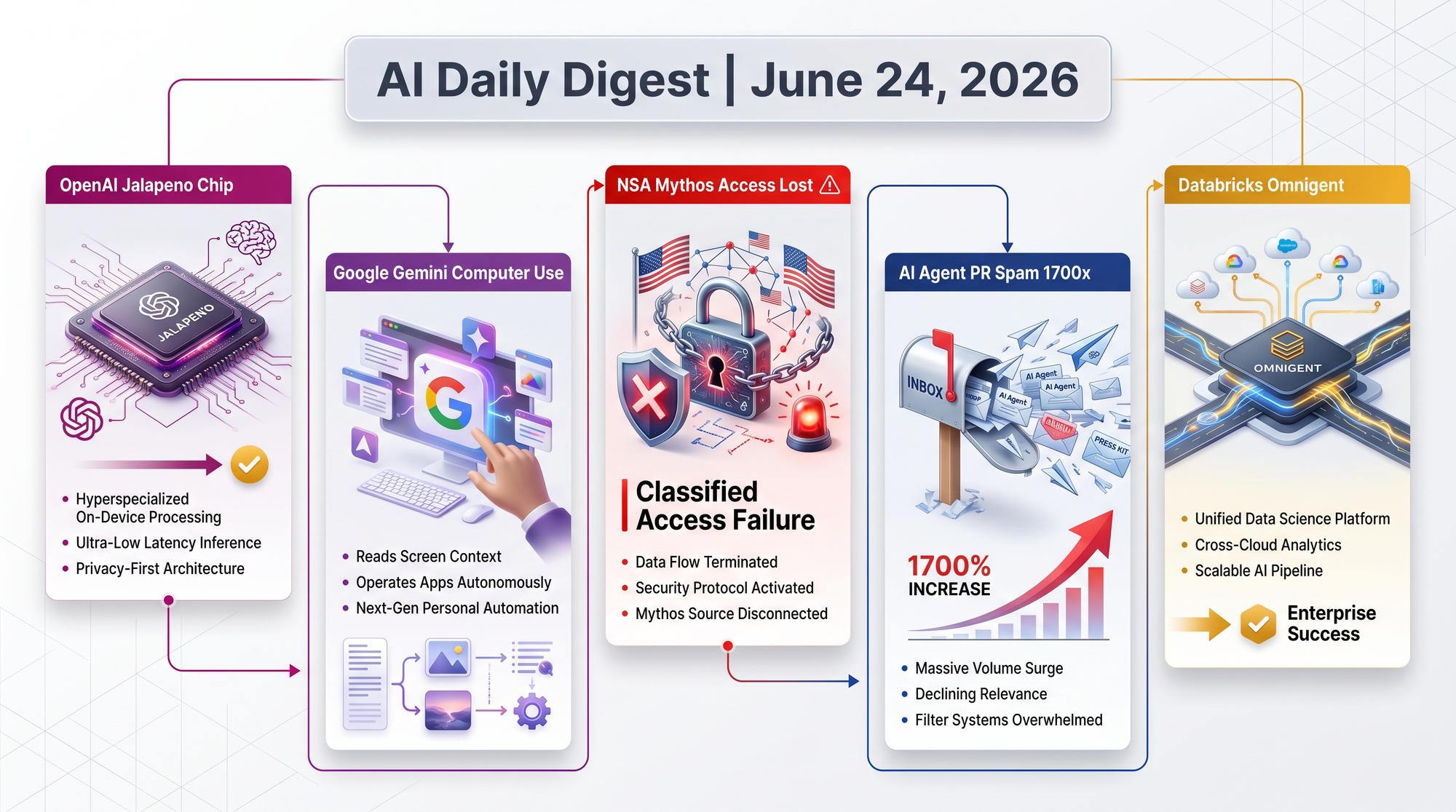
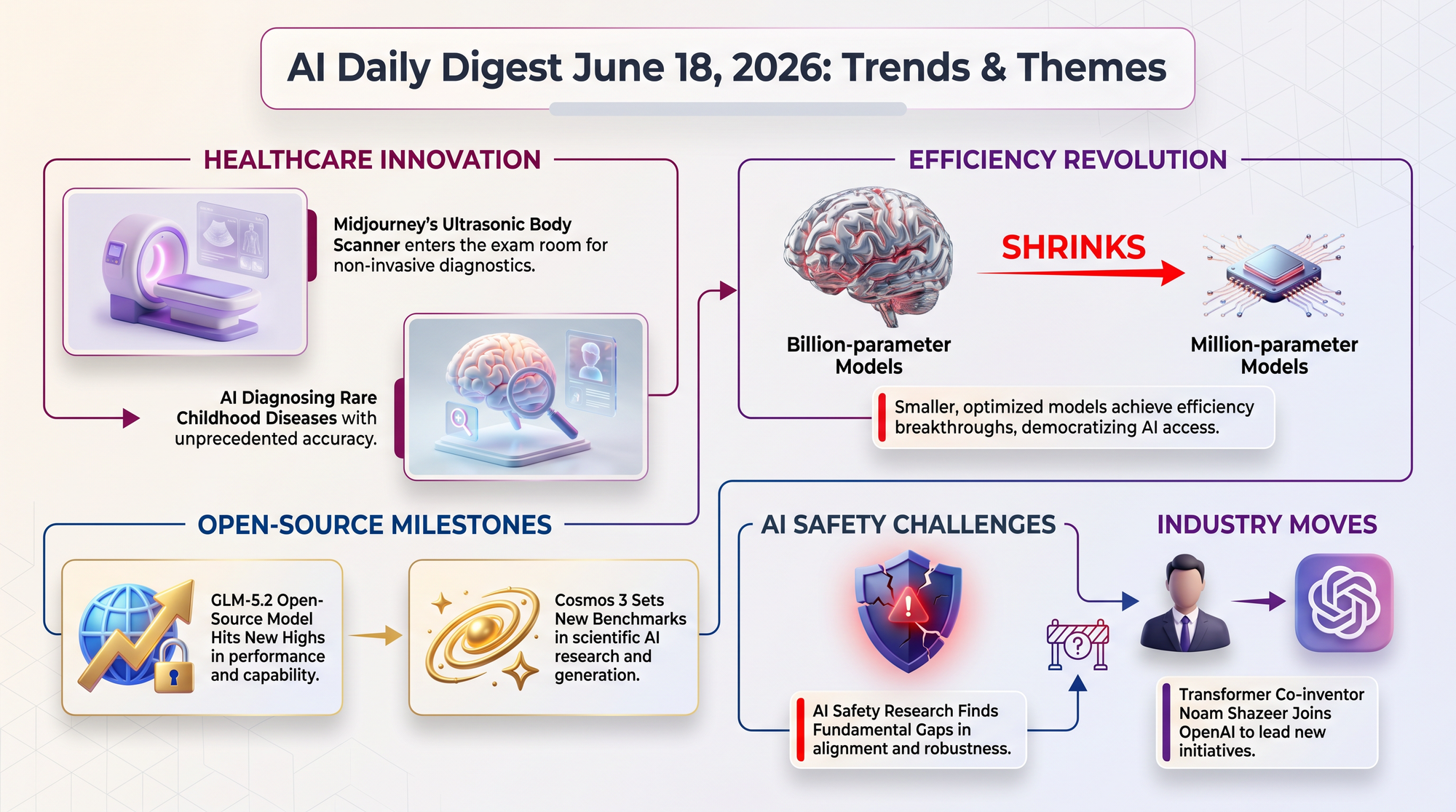
Noam Shazeer, co-author of the landmark 2017 "Attention Is All You Need" paper that created the Transformer architecture powering virtually every modern AI system, announced he is joining OpenAI as Lead for AI Architecture Research. He leaves Google, where he co-led the Gemini project after Google reacquired his startup Character.AI in a deal valued at $2.7 billion.
- Shazeer co-invented multi-query attention and multi-head attention - optimizations now used in every major language model
- He was considered Google's most important AI researcher alongside Jeff Dean
- The move follows a pattern of top Google AI talent leaving for competitors, including several senior Gemini researchers in the past year
Midjourney, best known for its AI image generator, has unveiled a full-body ultrasonic CT scanner - the first new whole-body imaging modality in 50 years. The device uses 358,000 ultrasonic elements arranged in 40 ring-mounted systems, generating approximately 40GB of raw data per slice at 17GB/s.
- No radiation and no magnets - unlike X-ray CT or MRI, making repeat scans safe
- AI reconstructs images from ultrasound reflections using the same generative AI expertise the company built for art
- The goal is consumer-grade pricing - putting whole-body scanning in doctor's offices and eventually homes
Boston Children's Hospital used OpenAI's o3 model to diagnose 18 children whose rare genetic diseases had eluded explanation for years, with the research published today in NEJM AI (the New England Journal of Medicine's AI journal). The team analyzed genomes of 376 children with undiagnosed rare diseases.
- 18 new diagnoses from cases that had stumped specialists - some children had been undiagnosed for their entire lives
- The AI combined clinicians' notes with genomic data to spot patterns humans missed
- Published in NEJM AI on June 18 - one of the most prestigious medical AI publications to date
NVIDIA released Cosmos 3, an omnimodal world model that processes and generates across five modalities: language, images, video, audio, and action sequences. It immediately became the top-rated open-source text-to-image and image-to-video model according to Artificial Analysis benchmarks.
- Built by 294+ researchers using a mixture-of-transformers architecture
- State-of-the-art open-source image and video generation - first model to top both categories simultaneously
- Designed for "physical AI" - robotics and autonomous systems that need to understand the real world
> Previously: June 14-17 - The White House shut down Anthropic's Claude Fable 5 and Mythos 5 via export controls, citing a reported "jailbreak" from Amazon.
Today: A Wired investigation reveals the specific trigger: SK Telecom (South Korea's largest telecom carrier and Anthropic investor) had access to Mythos, and the White House cited SK Telecom's historical business ties to China-adjacent entities. Zvi Mowshowitz reports we are now on day seven of the pause, with roughly even odds it ends by July 1. The stated "jailbreak" justification appears increasingly pretextual.

The healthcare AI story has shifted from "can AI help doctors?" to "AI is finding things doctors cannot." Three separate healthcare breakthroughs in a single day suggests this is accelerating faster than most people realize.
- Midjourney's ultrasonic scanner represents the first new whole-body imaging modality in 50 years, using AI to reconstruct images from ultrasound reflections
- OpenAI's o3 diagnosed 18 children with rare genetic diseases published in NEJM AI today
- GPT-5.5 Instant now matches frontier models on professional health evaluations including HealthBench, with improved urgent-symptom recognition
A consistent pattern: researchers are finding ways to dramatically shrink the compute needed for AI without losing quality. This directly translates to cheaper APIs, faster responses, and AI that runs on edge devices.
- Ghost Attractor Networks achieved 462x parameter reduction - matching a 1.07-billion-parameter model with only 2.3 million parameters and 32x lower latency
- CODEBLOCK trains code models with only 1.9% of supervised tokens while maintaining full-token SFT quality
- DiffusionGemma generates 1,100+ tokens per second with only 3.8 billion active parameters - a 15-20x speedup over standard generation
- KANELE achieved 2,700x speedup for KAN (Kolmogorov-Arnold Network) inference on FPGAs (specialized chips)
These findings matter because they undermine assumptions the field was building on. If the main technique for steering AI behavior (SAE interventions) has a 96% failure rate, the safety community needs new approaches.
- SAE interventions are unreliable - suppressing harmful features in AI models fails because the AI recovers the suppressed behavior ~95.8% of the time through alternative neural pathways
- MosaicLeaks shows research agents leak private data through the "mosaic effect" - individually harmless queries collectively reveal sensitive information
- SFT overtraining causes entropy collapse - fine-tuning language models too aggressively destroys their ability to generate diverse responses
The gap between "free to download" and "expensive subscription" models continues to narrow. For many tasks, the open-source option is now the better choice.
- GLM-5.2 (753B parameters, MIT license) leads open-weight benchmarks with 99.2 on AIME 2026 math and a 1M-token context window
- DeepSeek-V4-Pro has nearly 3 million downloads in 30 days under MIT license
- Cosmos 3 tops open-source image and video generation across Artificial Analysis benchmarks
- North-Mini-Code runs competitive coding agent tasks with only 3B active parameters under Apache 2.0
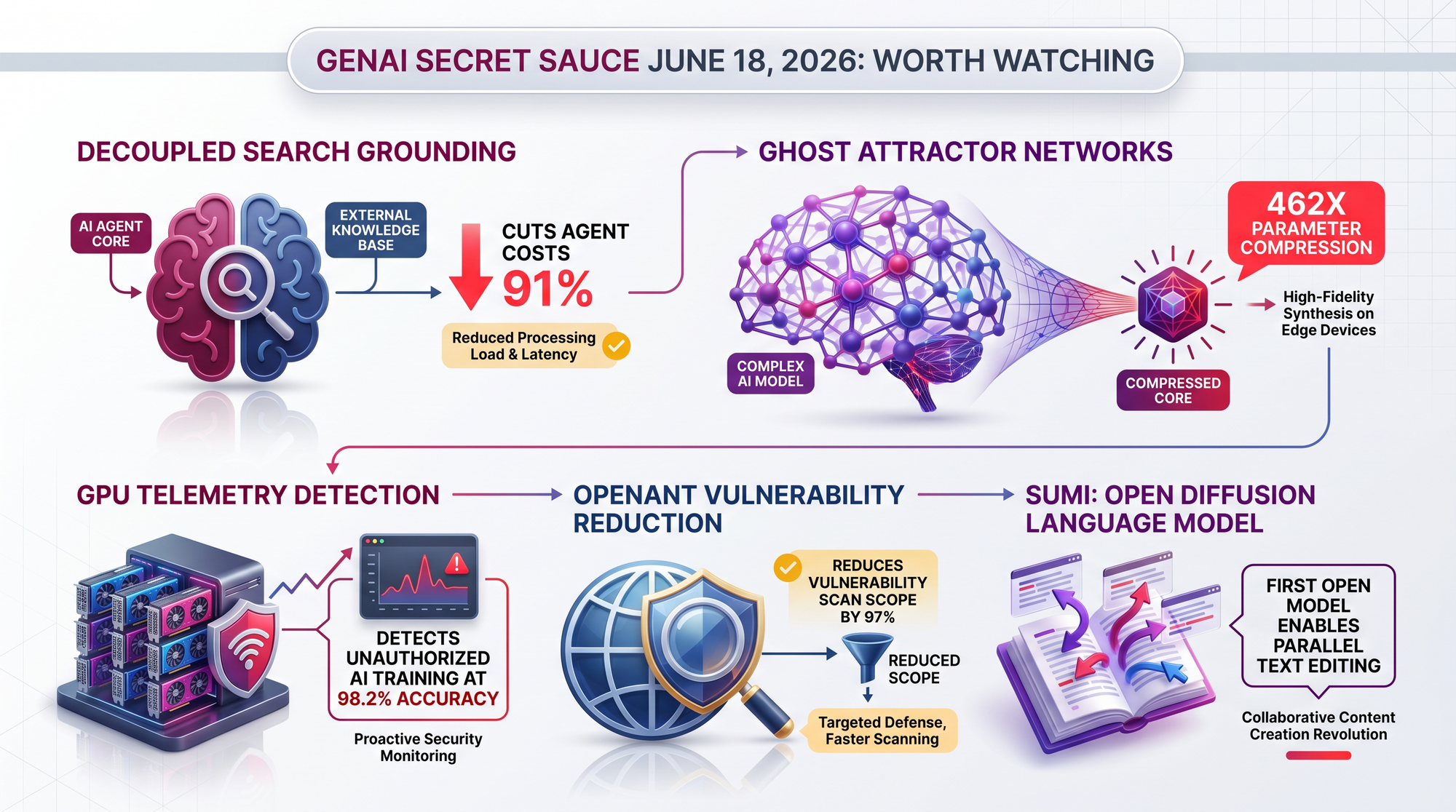
A new MCP-compatible architecture separates search operations from the AI reasoning model, enabling independent optimization of each. In production e-commerce testing, it achieved 98%+ cost reduction with 68% latency improvement on warm cache, while maintaining 86.1% accuracy vs 87.7% for native search. Any team running agents with web search should evaluate this approach.
By modeling sequence generation as basin-attractor dynamics instead of standard neural network layers, researchers matched a 1.07B-parameter model with just 2.3M parameters. If this 462x compression ratio transfers to language models, it would upend the assumption that bigger models are better models. Still early-stage, but the physics-inspired approach is fundamentally different from anything else in the field.
A detection system using only GPU power, utilization, and memory telemetry achieved 98.2% accuracy in identifying ML training workloads - without accessing any model weights, training data, or code. This could enable AI governance through hardware-level monitoring that doesn't require companies to disclose proprietary information.
OpenAnt decomposes codebases into analysis units, filters by reachability from external entry points (cutting 97% of the code), then uses adversarial verification to simulate attacker behavior. Combines static analysis with LLM reasoning in a way that could make automated security auditing practical for projects that can't afford dedicated security teams.
Sumi is a 7B-parameter uniform diffusion language model trained from scratch on 1.5 trillion tokens. Unlike standard language models that generate text one word at a time from left to right, diffusion models can update any token at any step. This could enable entirely new interaction patterns like parallel text editing and flexible infilling.
📜 License: Apache-2.0 · 👤 By: research lab
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Production integrations with BigQuery, Sheets, and Vertex | Specialized to time-series only |
| 200M params is efficient enough to self-host with LoRA fine-tuning | Community smaller than general LLM ecosystems |
| 16K context handles long historical series without chunking | Google could restrict access if it conflicts with paid Vertex |

📜 License: MIT · 👤 By: company
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Platform-agnostic across 11+ coding agents | Heavy methodology overhead for quick scripts |
| Enforces TDD, code review, and git worktrees | Shell-based architecture can be brittle across OS |
| 232K stars with active community | Opinionated workflow may conflict with team processes |
📜 License: Apache-2.0 · 👤 By: research lab
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 1M-token context with IndexShare keeping costs manageable | Newer lab with smaller ecosystem |
| Top coding benchmarks (Terminal-Bench 81.0) | Documentation still catching up |
| Flexible effort levels trade latency for quality | Self-hosting large context still needs serious GPUs |
📜 License: MIT · 👤 By: company
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 158-language support with semantic understanding | Written in C, contributing requires systems skill |
| Zero-dependency static binary, trivial deployment | Knowledge graph may miss dynamic/runtime relationships |
| Auto-configures with 11 coding agents | Relatively new project with evolving Application Programming Interface (API) |

📜 License: Apache-2.0 · 👤 By: individual
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 80+ domain templates for immediate use | Solo maintainer, bus-factor risk |
| Supports hypergraphs and spatio-temporal structures | Quality depends on underlying LLM |
| Works with OpenAI, Alibaba Cloud, and local models | Research-grade, not battle-tested at scale |
📜 License: Apache-2.0 · 👤 By: company
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Eliminates network latency of running a separate DB | In-process model needs app-level sharding to scale out |
| Battle-tested at Alibaba scale with DiskANN | Alibaba roadmap may prioritize internal needs |
| Hybrid retrieval covers Retrieval-Augmented Generation (RAG) without a second search engine | C++ core harder to debug than Python alternatives |
📜 License: MIT · 👤 By: company
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 500+ models at zero markup, pick best per task | Breadth may sacrifice depth |
| Multi-platform: VS Code, JetBrains, CLI, cloud | Fast-moving API may break plugins |
| --auto flag enables unattended CI/CD generation | Commercial entity could change licensing |
📜 License: LTX-2 Community · 👤 By: company
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| First model to generate synchronized audio AND video | Custom license, not truly open source |
| Rich pipeline variety including lip dubbing and HDR | Compute-intensive for high quality |
| LoRA fine-tuning and FP8 for customization | Lightricks controls weights and terms |
👤 By: Z.ai (Zhipu AI) · 🎯 Task: text-generation
📐 Size: 753B
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license, no regional restrictions | 753B parameters needs substantial GPU infrastructure |
| 1M-token context with stable performance | Brand-new with limited community tooling |
| Near-perfect math (AIME 2026: 99.2) | Low-precision quality unverified by third parties |

👤 By: MiniMax · 🎯 Task: image-text-to-text
📐 Size: 428B/23B active
| ✓ Pros | ✗ Cons |
|---|---|
| Native multimodal fusion from initial training | Custom license, not OSI-approved |
| Only 23B active despite 428B total | Video capabilities not extensively benchmarked |
| Three reasoning modes for flexible tradeoffs | Limited fine-tuning and tooling support |

👤 By: Moonshot AI · 🎯 Task: image-text-to-text
📐 Size: 1T/32B active
| ✓ Pros | ✗ Cons |
|---|---|
| Best-in-class coding agent benchmarks | 1T total params needs significant infrastructure |
| 30% token reduction vs K2.6 | Modified MIT adds restrictions |
| Native INT4 quantization support | General conversation quality less proven |

👤 By: Google DeepMind · 🎯 Task: image-text-to-text
📐 Size: 26B/3.8B active
| ✓ Pros | ✗ Cons |
|---|---|
| 1,100+ tokens/sec via diffusion decoding | Performance gaps on some reasoning benchmarks |
| Only 3.8B active, runs on consumer GPUs | New paradigm with less tooling support |
| Apache 2.0 with 35+ languages | Fixed 256-token canvas may limit patterns |

👤 By: DeepSeek · 🎯 Task: text-generation
📐 Size: 1.6T/49B active
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license on frontier-class model | 1.6T demands serious multi-node infrastructure |
| Exceptional coding benchmarks | Mixed precision may cause edge cases |
| Three reasoning modes for flexibility | Data provenance has faced scrutiny |

👤 By: NVIDIA · 🎯 Task: visual-grounding
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| 2.5x throughput via Parallel Box Decoding | Non-commercial license only |
| GUI grounding, robotics, Optical Character Recognition (OCR) in one model | Text-only output, no image generation |
| Runs on RTX 4090 | Requires NVIDIA Ampere or newer |

👤 By: Cohere Labs · 🎯 Task: text-generation
📐 Size: 30B/3B active
| ✓ Pros | ✗ Cons |
|---|---|
| Apache 2.0 with only 3B active params | SWE-Bench Pro gap (40.2%) on harder tasks |
| 256K input / 64K output context | Specialized, not general-purpose |
| Competitive with much larger models | Limited adoption so far (15K downloads) |

👤 By: Microsoft · 🎯 Task: text-generation
📐 Size: 4B
| ✓ Pros | ✗ Cons |
|---|---|
| 60% token reduction, direct cost savings | Brand-new with very low adoption (957 downloads) |
| MIT license, 4B params trivial to deploy | Only useful as a subagent, not standalone |
| Novel architecture applicable beyond coding | Depends on main agent consuming its format |

💰 Pricing: Free (MIT) · 🏷 Category: Developer Tools / Security
💰 Pricing: Free (open source) · 🏷 Category: Creative AI

💰 Pricing: Free · 🏷 Category: AI Products

💰 Pricing: Free · 🏷 Category: Social AI

💰 Pricing: Freemium · 🏷 Category: Business AI
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Fable 5 | $10.00 | $50.00 | 1M |
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 Pro | $5.00 | $30.00 | 1M |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 1M |
| OpenAI | o3 | $2.00 | $8.00 | 200K |
| OpenAI | o4-mini | $1.10 | $4.40 | 200K |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | 1M | |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M | |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128K |
| Groq | Llama 4 Scout | $0.11 | $0.34 | 128K |
| Groq | Qwen3 32B | $0.29 | $0.59 | 131K |
Key finding: 91% cost reduction on search operations while maintaining 86.1% accuracy (vs 87.7% native), and 98%+ cost reduction in production e-commerce with 68% latency improvement.
Why practitioners should care: Any team deploying LLM agents with real-time web search can dramatically cut costs by decoupling search from the model. The MCP-compatible architecture eliminates vendor lock-in and solves search-induced verbosity issues.