Watch today's digest as a video summary (generated by NotebookLM)
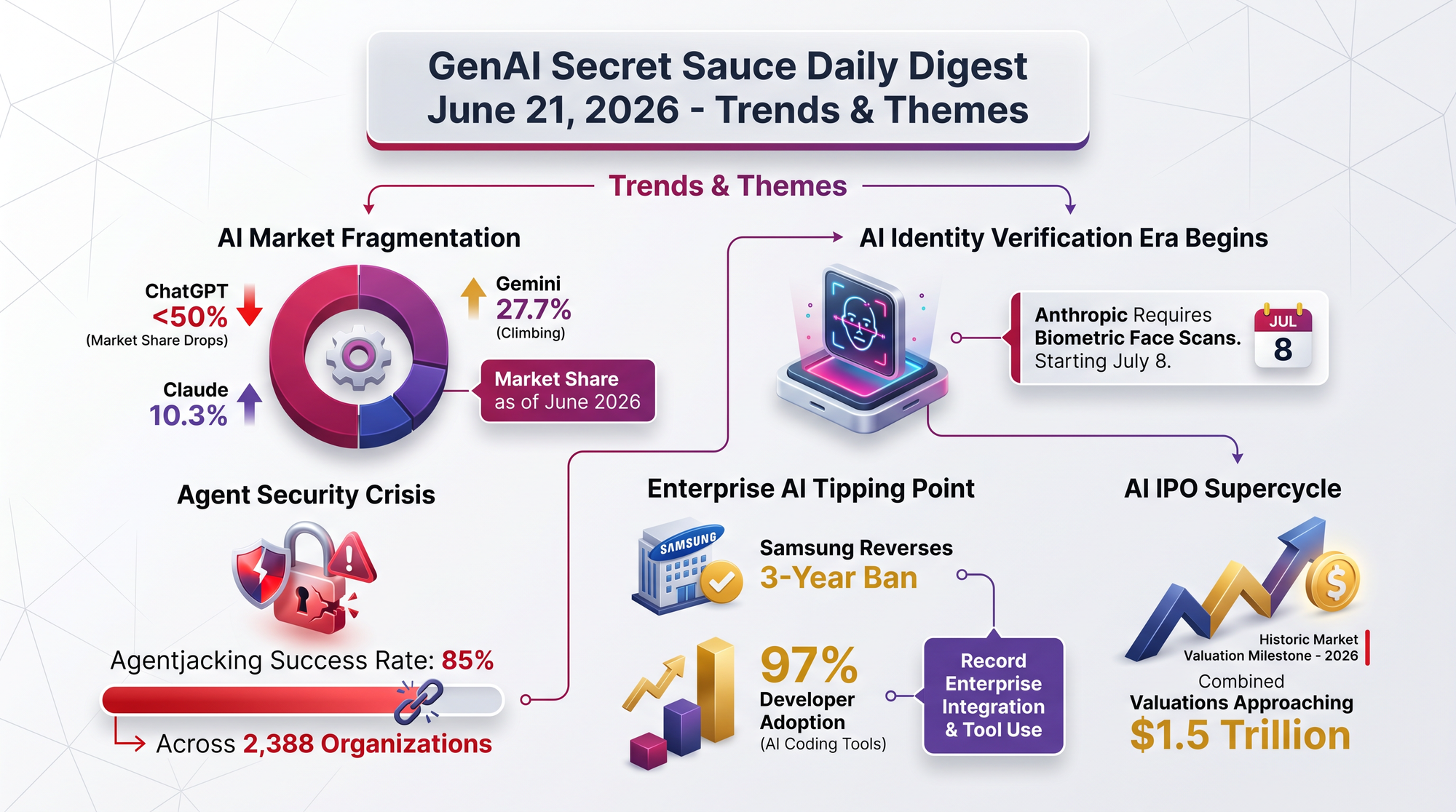
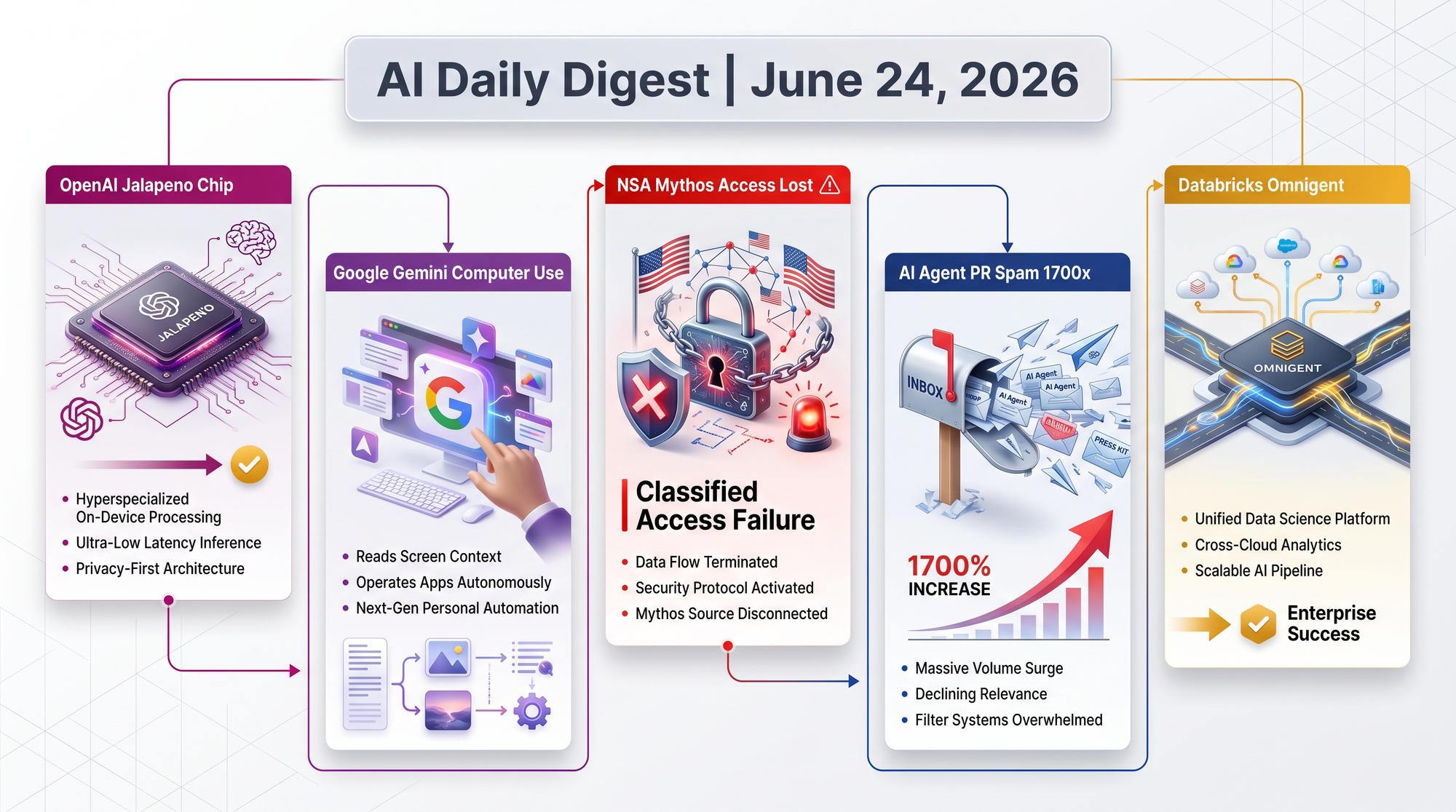
OpenAI and Broadcom jointly announced Jalapeño - an "Intelligence Processor" designed from scratch for running AI models (inference), not training them. The nine-month design-to-tape-out timeline is believed to be the fastest ASIC development cycle ever achieved for a chip of this complexity, accelerated by using AI tools in the design process itself.
The move follows Google (TPU), Amazon (Trainium/Inferentia), and Meta (MTIA) in the trend of AI companies building custom hardware. OpenAI was the last major frontier lab relying entirely on NVIDIA GPUs.
- Microsoft is purchasing approximately 40% of initial production - a massive endorsement from OpenAI's largest partner and investor
- Gigawatt-scale deployment is targeted for late 2026 - meaning data centers consuming as much power as a mid-sized city
- The chip optimizes for inference, not training - reflecting the industry shift as serving billions of users becomes the dominant cost
- AI-assisted chip design cut the development cycle from the typical 2-3 years to under a year
Google DeepMind merged computer use as a native capability into Gemini 3.5 Flash, their budget-tier model optimized for speed. Previously, computer use required a separate, dedicated Gemini 2.5 model. Now browser automation, mobile app control, and desktop navigation are available from the same model used for chat and coding.
The significance is the price tier: putting computer use in Flash rather than Pro signals that Google sees screen control as a commodity feature, not a premium one.
- Native integration means no switching between models for different tasks - one Application Programming Interface (API) call handles both text analysis and screen interaction
- Adversarial injection training teaches the model to resist prompt injection attacks through web pages it navigates - a safety measure competitors haven't publicly matched
- Automatic task-halt safety measures stop the agent if it detects it's being manipulated
- Direct competition with Anthropic's computer use (available since late 2024) and OpenAI's Operator
> Previously: June 23 - Fable 5 restrictions entered their second week after the Commerce Department barred foreign nationals from accessing Anthropic's Mythos and Fable models.
Today: The New York Times reported that parts of the NSA have lost access to Anthropic's Mythos 5, the model that - during a controlled red-team exercise - breached "almost all" of the agency's classified systems "not in weeks, but in hours." The irony is acute: the same government that witnessed the model's power firsthand is the one whose export controls forced Anthropic to pull it globally.
- Anthropic couldn't enforce nationality-based access restrictions without pulling the models for everyone, including U.S. government users
- Prediction markets give 88% odds of Fable 5 returning by July 31, according to Zvi Mowshowitz's analysis
- The agency may retain access to older model versions but loses updates, support, and the most capable models
- Multiple analysts describe this as "a train wreck" of policy implementation
Greptile analyzed pull request patterns in the OpenClaw repository - which became the fastest-growing GitHub repo in history - and found a pattern that mirrors the early internet's spam crisis.
The parallel to email spam is instructive: the technology that solved email spam (Bayesian filters, reputation systems, rate limiting) took years to develop. Open-source is now facing the same reckoning, but with contributions that look superficially legitimate.
- Weekly PR volume exploded from ~2 to 3,400 between December and February - a 1,700x increase
- Merge rate collapsed to 9.3% - meaning over 90% of AI-generated contributions were rejected
- Multiple AI agents independently submitted identical PRs for the same issues, with no coordination
- Maintainer burden grew faster than the project - review time per PR didn't decrease, but volume made the queue unmanageable
Databricks cofounders Matei Zaharia and Reynold Xin, speaking on the Latent Space podcast, unveiled Omnigent - an open-source meta-harness that lets agents from Claude Code, Codex, Cursor, and other systems work through unified APIs and session management. The company received over 400 pull requests within days of launch.
- Universal agent compatibility - one harness for agents from any vendor, avoiding lock-in
- Session management and audit trails built in for enterprise compliance
- $175 billion valuation target reflects Databricks' bet that the agent infrastructure layer is as valuable as the cloud infrastructure layer
- Enterprise-grade security controls including access policies and data governance
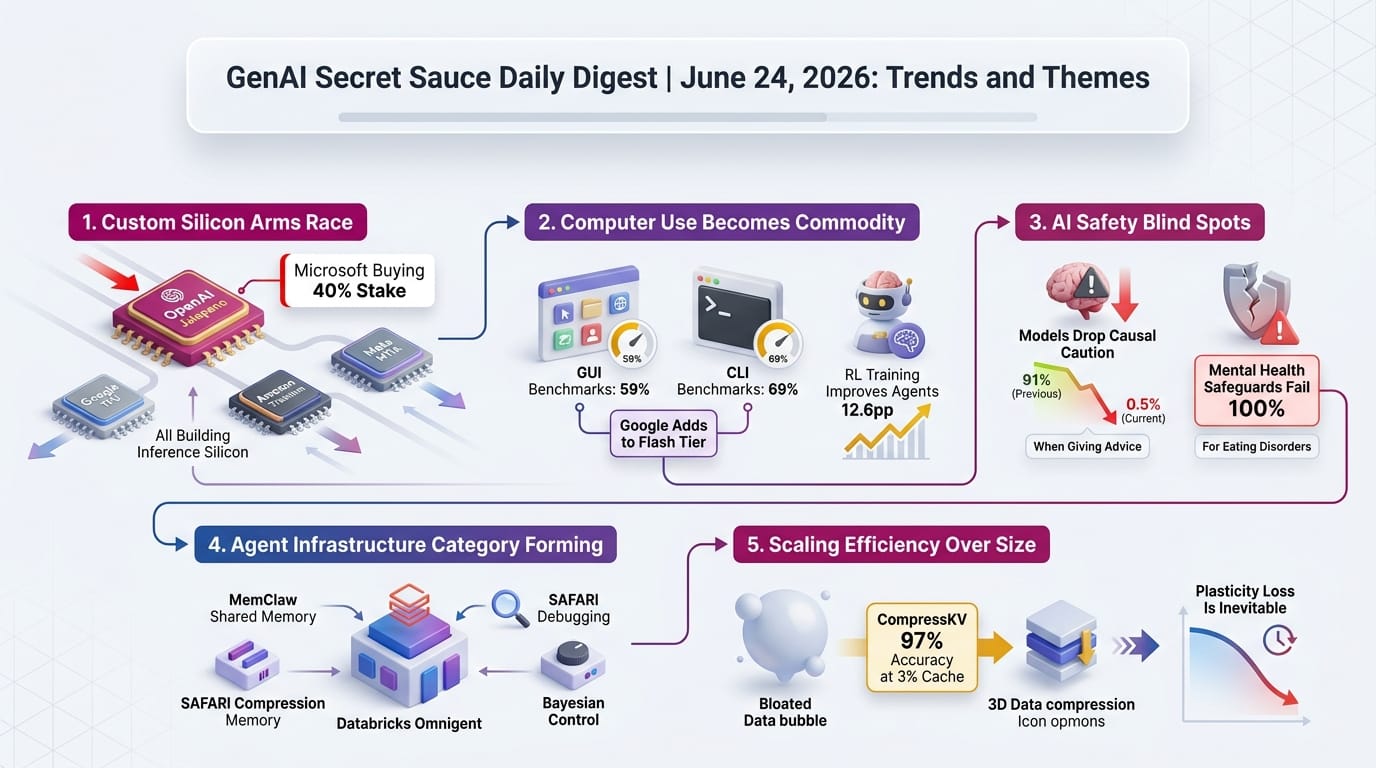
- 12 billion parameters generating up to 2048x2048 images
- Sub-2-second generation on consumer GPUs
- Open weights allow local deployment without API costs
- 26B total, 3.8B active parameters (Mixture-of-Experts design)
- Generates 1,100+ tokens worth of multimodal content in a single pass
- Discrete diffusion architecture - a departure from autoregressive generation
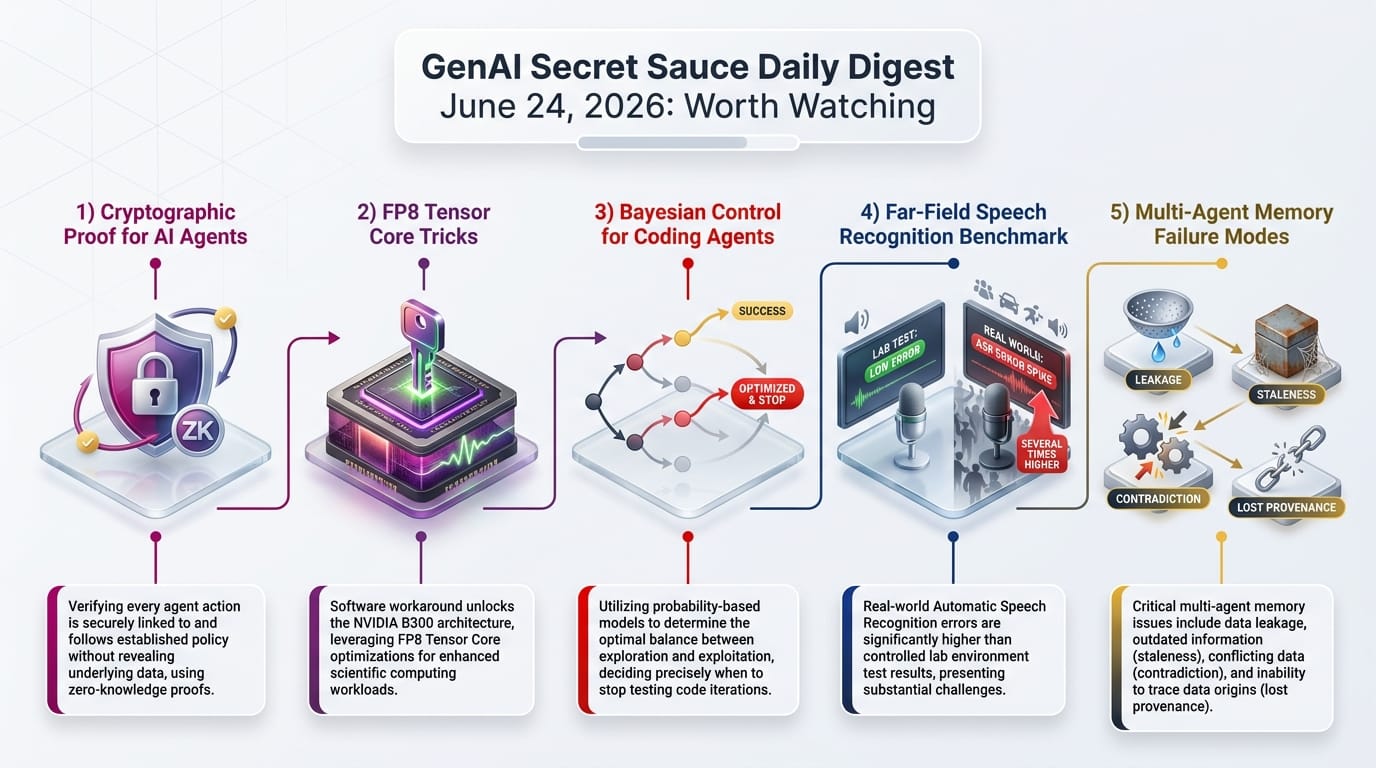
A new paper proposes attaching independently verifiable cryptographic certificates to every agent action, proving compliance with formally specified policies. The approach translates policy requirements into logical predicates and generates proofs using zero-knowledge systems. If this scales, it could resolve the "trust but verify" problem for autonomous AI systems.
The B300 Graphics Processing Unit (GPU) has 30x less native FP64 throughput than the B200, which would cripple scientific computing. A new paper routes calculations through FP8 tensor cores using mathematical reformulations, achieving FP64-equivalent precision at FP8 speed. This matters because it determines whether the newest hardware can serve both AI and scientific workloads.
A paper reframes coding agent orchestration as Bayesian hypothesis testing: maintain a probabilistic belief about whether code is correct, then dynamically decide whether to gather more evidence or ship. The cost-performance tradeoff outperforms fixed deterministic pipelines.
The new FFASR Leaderboard reveals that error rates for far-field conditions (reverberant rooms, background noise, distance) are "several times higher" than near-field benchmarks. This is the gap between demo and deployment for every smart speaker, conference room, and voice-controlled device.
A formalization of the "fleet-memory problem" identifies these failure modes and proposes system-level primitives (access control, versioning, conflict resolution, attribution) to address them. As multi-agent systems move from research to production, this taxonomy will define the engineering requirements.
📜 License: AGPL-3.0 · 👤 By: Individual developer
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| End-to-end pipeline with 400+ skills | AGPL license limits commercial use |
| Integrates multiple AI image/video generators | Requires significant GPU resources |
| Active community (19K+ stars in days) | Solo maintainer - bus factor of 1 |
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Multi-market coverage (5 markets) | Analysis quality limited by underlying LLM |
| Automated daily delivery | Requires API keys for market data |
| MIT license for commercial use | Not a substitute for professional advice |

📜 License: MIT · 👤 By: Research lab (Nous Research)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Self-improving skill creation | Learning loop quality varies by task domain |
| Persistent cross-session memory | High star count suggests community traction |
| Runs on consumer hardware | Privacy implications of persistent memory |
📜 License: MIT · 👤 By: Company (HackerRank)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Fairness-constrained scoring | AI resume screening carries legal risks |
| GitHub contribution enrichment | Favors candidates with public GitHub profiles |
| HackerRank backing and maintenance | Still requires human review of top candidates |
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Works with Claude Code, Copilot, others | Ethical and legal grey area for cloning |
| Parallel builder architecture | Output quality depends on source site complexity |
| MIT license | May miss interactive/dynamic elements |
📜 License: Apache-2.0 · 👤 By: Company (Google Labs)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Google Labs backing | Requires upfront design token authoring |
| Tailwind CSS and W3C format exporters | Only useful if your team uses AI coding agents |
| Change detection across versions | Early-stage, format may evolve |

📜 License: MIT · 👤 By: Company (Stably AI)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Isolated worktrees prevent conflicts | Resource-intensive with many agents |
| Multi-agent support (Claude, Codex, etc.) | Coordination between agents is manual |
| GitHub and Linear integrations | Requires understanding of git worktree model |
📜 License: Apache-2.0 · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Six architectural patterns | Claude Code-specific |
| Plain language to agent team | Generated architectures may need refinement |
| Apache-2.0 license | Relatively niche use case |
👤 By: DeepSeek AI · 🎯 Task: text-generation
📐 Size: 862B (49B active)
| ✓ Pros | ✗ Cons |
|---|---|
| 1M token context window | Requires significant infrastructure |
| Only 49B active parameters | DeepSeek license may restrict some uses |
| 2M+ downloads in 30 days | Chinese origin may face export controls |

👤 By: Z.ai · 🎯 Task: text-generation
📐 Size: 753B
| ✓ Pros | ✗ Cons |
|---|---|
| Fully open source with no restrictions | 753B requires multi-GPU deployment |
| Adjustable reasoning depth | Newer model, smaller community |
| Beat GPT-5.5 on coding benchmarks | Download count still low |

👤 By: MiniMax AI · 🎯 Task: multimodal
📐 Size: 428B (23B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Four modalities in one model | 23B active is still GPU-intensive |
| 1M token context | MiniMax license may restrict some uses |
| 143K downloads show traction | Chinese origin and licensing uncertainty |

👤 By: Google DeepMind · 🎯 Task: multimodal generation
📐 Size: 26B (3.8B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Only 3.8B active parameters | Gemma license terms |
| 1M+ downloads in 30 days | Discrete diffusion is newer, less tooling |
| Google DeepMind backing | May lag behind specialized image models |

👤 By: Baidu · 🎯 Task: OCR/document processing
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| No page limit on PDFs | Accuracy on complex layouts unverified |
| Apache 2.0 license | 3B model may struggle with handwriting |
| Single-pass processing | Limited community documentation |

👤 By: NVIDIA · 🎯 Task: visual grounding
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| Text-to-bounding-box in any image | NVIDIA license may restrict some uses |
| 359K downloads show strong adoption | 3B model needs GPU |
| Versatile across domains | Accuracy varies with image complexity |

👤 By: Microsoft · 🎯 Task: coding subagent
📐 Size: 4B
| ✓ Pros | ✗ Cons |
|---|---|
| 60% cost reduction for exploration | Only useful paired with a main coding agent |
| MIT license | Small model may miss complex patterns |
| Microsoft backing | Low download count suggests early adoption |

💰 Pricing: Not specified · 🏷 Category: Customer Intelligence
💰 Pricing: Freemium · 🏷 Category: Developer Infrastructure
💰 Pricing: Free · 🏷 Category: AI Commerce
💰 Pricing: Free · 🏷 Category: On-Device AI
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Fable 5 | $10.00 | $50.00 | 1M |
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | Long |
| OpenAI | GPT-5.5 Pro | $30.00 | $180.00 | Long |
| OpenAI | GPT-5.4 Mini | $0.75 | $4.50 | Short |
| OpenAI | GPT-5.4 Nano | $0.20 | $1.25 | Short |
| Gemini 3.5 Flash | $1.50 | $9.00 | N/A | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | N/A | |
| Groq | Llama 4 Scout | $0.11 | $0.34 | 128K |
| Groq | Llama 3.1 8B Instant | $0.05 | $0.08 | 128K |
Key finding: 97% of full-cache performance at 3% memory cost on LongBench QA. 90% accuracy with just 0.7% KV storage on Needle-in-a-Haystack.
Why practitioners should care: KV-cache memory is the binding constraint for long-context LLM batching in production today. A training-free, drop-in compression layer that cuts memory by 30-97x with negligible accuracy loss means larger batch sizes, longer supported contexts, or dramatically lower GPU costs on existing hardware. No model changes required.