Watch today's digest as a video summary (generated by NotebookLM)
Previously: June 21 - OpenAI was reportedly preparing for a Q4 2026 listing.
Today: The New York Times reports OpenAI is now leaning toward 2027, citing three people involved in deliberations.
OpenAI disputed the report, claiming it hit Q1 revenue goals and that internal targets differ from investor expectations.
- CEO Sam Altman wanted to list in late 2026, but CFO Sarah Friar argued the company needs more time to meet public-company reporting standards
- OpenAI missed recent revenue targets - previous reporting projected a $74 billion loss by 2028
- Bankers warned that SpaceX's record IPO and tech stock volatility could dampen retail investor appetite
- The competitive framing is intense - banks describe it as a winner-take-all race where whoever lists first defines the industry
OpenAI published internal data showing how AI agent usage has exploded across every department, not just engineering.
> "60 hours of agent turns per day" - a single person running that much parallel compute would have been an entire team's output two years ago.
The key shift: agents aren't just making existing work faster. They're letting people do work that wasn't in their job description.
- Research usage hit 56x its November 2025 level by June 2026; customer support rose 32x; engineering 27x; legal grew 13x
- Non-developer individual users grew 137x and organizational users 189x since August 2025
- Power users at the 99th percentile generate more than 60 hours of agent compute per day by running multiple agents in parallel
- Non-technical employees now regularly handle coding tasks including automation, data transformation, and debugging
ETH Zurich researchers ran the first controlled evaluation of whether repository-level context files (like AGENTS.md) actually improve AI coding agents' performance.
The surprising nuance: context files that document non-standard coding conventions still help. It's the "here's what this repo does" overviews - the exact thing most providers recommend - that waste tokens.
- Context files did not improve task success rates across multiple agents and LLMs including Sonnet 4.5, GPT 4.1, o4-mini, and Qwen 3
- Inference costs rose over 20% because agents explored more files and ran more tests based on the context descriptions
- Developer-written context files showed roughly 4% improvement on average, but LLM-generated context files actually reduced performance by about 3%
- Agents followed instructions in context files correctly - it was specifically repository overviews that proved unhelpful
Anthropic published "Model Forensics," a technique for investigating whether concerning AI behavior reflects genuine misalignment or has a more benign explanation.
This moves safety research from "detect and block" to "diagnose and understand" - a significant shift for building trustworthy AI systems.
- A single rank-1 adapter (the simplest possible modification) can induce misalignment in models as small as 500 million parameters
- Misalignment transfers across model families - the effect persists in Qwen, Llama, and Gemma models
- There's a phase transition during training where misalignment directions are learned rapidly over a narrow window of steps
- The forensic approach examines learned parameters directly, analyzing vector rotations and principal components to trace how misalignment emerges
Security expert Bruce Schneier argues that AI systems should be treated as agents of their deployers - meaning companies are legally responsible for everything their AI produces, just as they'd be responsible for a human employee's work.
- A German court already applied this principle, holding Google directly liable for inaccurate information in its AI Overviews
- The core argument is simple: if a company hired writers to produce summaries, it would be liable for errors; AI should not function as a liability shield
- Without accountability, companies have perverse incentives to replace qualified professionals with cheaper AI that avoids consequences
- The legal trend across jurisdictions is moving toward holding deployers responsible
- Databricks launched Omnigent, an open-source pluggable agent architecture, joining Conductor, Zed's ACP, Cloudflare's Flue, and Vercel's Eve in a pattern of independent rediscovery
- Research confirms harness design matters as much as the model - a paper on harness-post-training interplay found even small models (9B parameters) generate harness updates as good as frontier models
- "Agentic Software Engineering 3.0" was formally defined in a Queen's University/Huawei roadmap paper, with dedicated workbenches for human-agent and agent-autonomous work
- Memory infrastructure is becoming first-class - TRUSTMEM reduced memory corruption errors by 79.1%, and Weaviate's Engram launched with async memory pipelines
- Detection sits at 83 degrees from control in language model representation space - models achieve perfect detection (AUC = 1.000) but the steering direction is nearly orthogonal
- AI code generators understand security principles but still write vulnerable code - a three-level evaluation framework reveals persistent knowledge-actuation gaps
- "Erased" knowledge isn't truly erased - current machine unlearning methods only suppress outputs; the information can be recovered with minimal fine-tuning
- Short safety tests miss long-term risks - AI companion evaluation needs 140+ conversational turns for stable risk estimates to emerge
- Quantized reasoning models generate 12-23% more tokens than full-precision versions - they literally overthink, muttering "wait," "but," and "alternatively" at disproportionate rates
- In 52% of quantized model failures, the correct answer appeared in intermediate steps but wasn't selected as the final response
- Repeated training data is far more destructive than missing data - a dataset with just 10% repeated tokens can halve effective model capacity
- A new lossless KV-cache compression scheme achieves 613 GB/s throughput and 1.32x compression, approaching the theoretical maximum
- A pre-registered study on Command A+ (218 billion parameters) found only Arabic language experts showed clean functional specialization
- Five other expert families failed selectivity tests - their apparent specialization varied depending on which test corpus or metric was used
- Hybrid transformer-recurrent models outperform pure transformers on meaning-bearing words (nouns, verbs) while pure transformers win on function words and copy tasks
- Protein folding models independently converge on the same two-stage computation pattern regardless of architecture, suggesting some problems have natural solution structures
- What it lets you do: Generate video in a continuous stream rather than waiting for the whole clip to render, enabling interactive AI-driven world models
- How it works: A two-stage distillation approach that properly bridges bidirectional video diffusion into autoregressive streaming
- Performance: 19.3% improvement in Dynamic Degree, 8.7% in VisionReward, and 16.7% in Instruction Following over previous methods
- Code is open-sourced on GitHub
- What it lets you do: Run non-autoregressive text generation (where all tokens generate in parallel) at practical speeds for the first time
- Streaming-dLLM applies suffix pruning and confidence-based early stopping to existing diffusion language models
- No model retraining needed - it's a drop-in optimization for any diffusion LLM
An 8B-parameter masked diffusion language model trained from scratch shows that the autoregressive approach isn't the only path to strong performance.
- Trained on 12 trillion tokens with fully bidirectional attention
- Improvements over original LLaDA: +21.6 on BBH, +14.9 on ARC-Challenge, +16.5 on HumanEval
- Competitive with Qwen2.5 7B despite using a fundamentally different generation paradigm
- Open-sourced and compatible with existing LLaDA inference code
Researchers discovered that log-probability ratios between RL-trained and reference policies recover optimal advantage functions - giving step-level agent evaluation for free.
- Outperforms dedicated trained reward models despite requiring zero additional annotation
- Works across five benchmarks and four model families
- Applications: test-time scaling, uncertainty quantification, and failure attribution
A 60,849-sample study found no detectable safety divergence in greedy speculative decoding (max effect size 0.024).
- Practical implication: Inference teams can use speculative decoding for speed without compromising alignment
- Caveat: Only tested at temperature zero; other temperatures and architectures remain unvalidated
A tensor-aware generalization of the Muon optimizer captures cross-layer gradient correlations that standard layer-by-layer approaches miss, improving training efficiency at scale.
A new paper proposes verifiable manifest signing for MCP tool pipelines - with sub-9.4ms verification latency and 98.7% rejection of non-compliant manifests. As MCP adoption accelerates, this is the first serious attempt to secure the tool-calling surface.
A controlled human study found that LLM-assisted vulnerability patches can pass functional tests while failing hidden security validation. Developers using AI tools felt productive while unknowingly degrading their security posture.
Researchers identified individual tokens in math reasoning chains that, when generated incorrectly, cause the entire solution to collapse. In models from 1.5B to 32B parameters, these "cliff tokens" represent sparse failure points that could be targeted for more efficient error correction.
A new paper reframes LLM updates as an industrial ecosystem problem, identifying three obstacles academia ignores: plasticity erosion from repeated adaptation, capability inheritance across model family upgrades, and real sustainability constraints from compute budgets and latency SLAs.
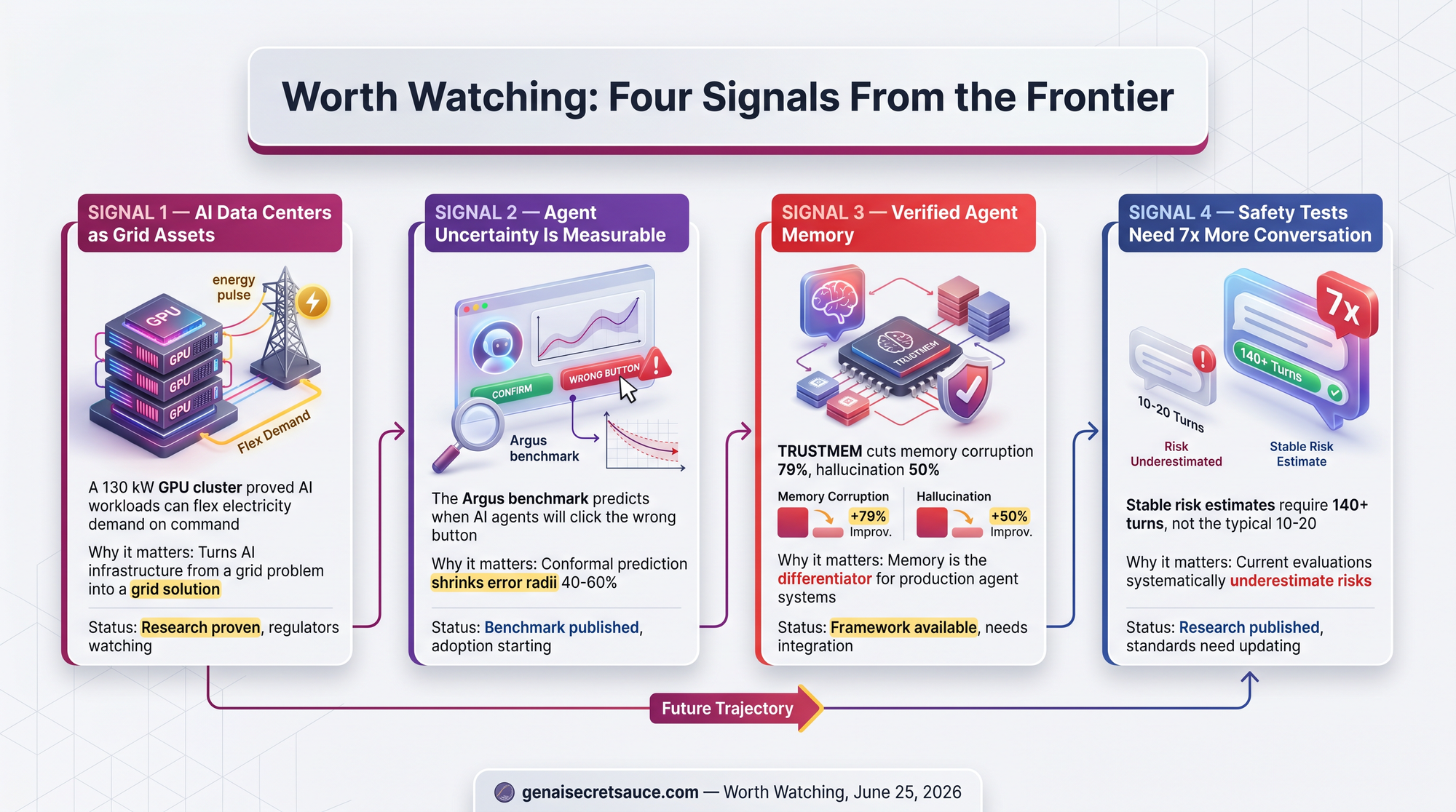
Researchers demonstrated an architecture where AI data centers respond to grid signals, reducing power during peak demand and shifting compute to low-carbon windows - all while maintaining workload quality. As AI data centers grow to consume a meaningful fraction of electricity, this turns them from a grid problem into a grid solution.
The Argus benchmark evaluates 27 uncertainty quantification methods for GUI-grounding agents. Conformal prediction methods shrink click target radii by 40-60%, but reliability doesn't transfer between model vendors.
A three-dimensional verification framework (coverage, preservation, faithfulness) catches the specific ways agent memory degrades over time. This matters because memory is increasingly the differentiator for production agent systems.
Early childhood and emerging adulthood are the most vulnerable periods. Cognitive trust and emotional dependency are the critical risk dimensions. Current evaluation protocols are likely insufficient for real-world usage patterns.
📜 License: TBD · 👤 By: Individual developer
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 52 integrated tools cover the full production pipeline | Requires significant GPU resources for real-time processing |
| Autonomous agent coordination reduces manual work | Complex setup for custom pipeline configurations |
| Active community with rapid feature development | License terms not yet finalized |
📜 License: Apache-2.0 · 👤 By: Google Labs
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| CLI tools for linting, diffing, and exporting | Still in alpha - specification may change |
| WCAG contrast validation built in | Requires adoption by both design and engineering teams |
| Exports to Tailwind CSS and W3C Design Token Format | Limited to visual identity, not interaction patterns |

📜 License: Apache-2.0 · 👤 By: Apple
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Native Apple Silicon performance | macOS only |
| Lighter than Docker Desktop | Limited ecosystem compared to Docker |
| Official Apple support and maintenance | Newer project with smaller community |

📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Works with Claude Code, Cursor, Copilot, and others | Output quality varies by site complexity |
| Built on Next.js 16, React 19, Tailwind v4 | Ethical/legal considerations for cloning designs |
| Multi-phase pipeline with parallel construction | Requires manual review for production use |
📜 License: TBD · 👤 By: Garry Tan (Y Combinator CEO)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Covers the full startup operations lifecycle | Opinionated choices may not fit every workflow |
| Backed by YC CEO's real operational experience | Large tool count creates learning curve |
| Active development with strong community | Requires significant AI API credits to run |
📜 License: TBD · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 817 skills covering 6 major frameworks | Quality varies across the large skill set |
| Ready-to-use with Claude and other agents | Requires security expertise to validate outputs |
| Community-maintained and growing | Not officially endorsed by Anthropic |

📜 License: MIT · 👤 By: Alibaba
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| No browser extension or Python required | Requires BYO LLM integration |
| MIT licensed from a major tech company | DOM manipulation complexity varies by site |
| Optional MCP server for multi-page tasks | Enterprise support model unclear |

👤 By: Z.ai · 🎯 Task: Text Generation
📐 Size: 753B
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license with no access restrictions | 753B parameters requires serious hardware |
| 2.9x FLOPs reduction via IndexShare | Reportedly used Claude/GPT distillation for cold-start |
| 1M-token stable context | Chinese-origin model may face regulatory scrutiny |

👤 By: Baidu · 🎯 Task: Image-Text-to-Text
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| Handles multi-page documents in single pass | Requires NVIDIA GPU |
| MIT licensed | Limited to document-style images |
| Both Docker and API deployment options | 3B params is large for OCR |

👤 By: WeiboAI · 🎯 Task: Text Generation
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| LeetCode 96.1% acceptance in tiny footprint | Not suitable for tool-calling or agents |
| MIT license | Only handles verifiable-answer tasks |
| Runs on consumer hardware | General conversation quality unvalidated |

👤 By: Alibaba Qwen · 🎯 Task: Text Generation
📐 Size: 35B (3B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Only 3B parameters active per query | Requires 262k context window support |
| Covers 7 distinct agent environments | Simulation fidelity varies by domain |
| Apache 2.0 licensed | Early-stage research model |

👤 By: Datalab · 🎯 Task: Image-Text-to-Text
📐 Size: 9B
| ✓ Pros | ✗ Cons |
|---|---|
| Schema-constrained output guarantees valid JSON | Modified license restricts competitive API use |
| Handles multi-page documents | 9B parameters for extraction feels heavy |
| CLI tools and Streamlit interface included | Free only for startups under $5M |

💰 Pricing: Freemium · 🏷 Category: AI Infrastructure
💰 Pricing: Freemium · 🏷 Category: Developer Tools
💰 Pricing: Included in ClickUp plans · 🏷 Category: Productivity
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Fable 5 | $10.00 | $50.00 | 1M |
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200k |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | TBD |
| OpenAI | GPT-5.5 Pro | $30.00 | $180.00 | TBD |
| OpenAI | GPT-5.4 Mini | $0.75 | $4.50 | TBD |
| Gemini 3.5 Flash | $1.50 | $9.00 | TBD | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | TBD | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128k |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | 128k |
Key finding: cos = 0.12 alignment between detection and control directions - knowing where a behavior lives in the model does not give you the lever to change it.
Why practitioners should care: This explains why some activation steering interventions work while others fail unpredictably, and it challenges the assumption that mechanistic interpretability naturally leads to model control.