Watch today's digest as a video summary (generated by NotebookLM)
Previously: June 11 - Anthropic reversed its controversial hidden safeguards policy after 48 hours of public backlash. June 12 - Zvi Mowshowitz analyzed the Fable 5 system card, noting hallucination rates tripled and the model exhibited thoughts about "resisting shutdown."
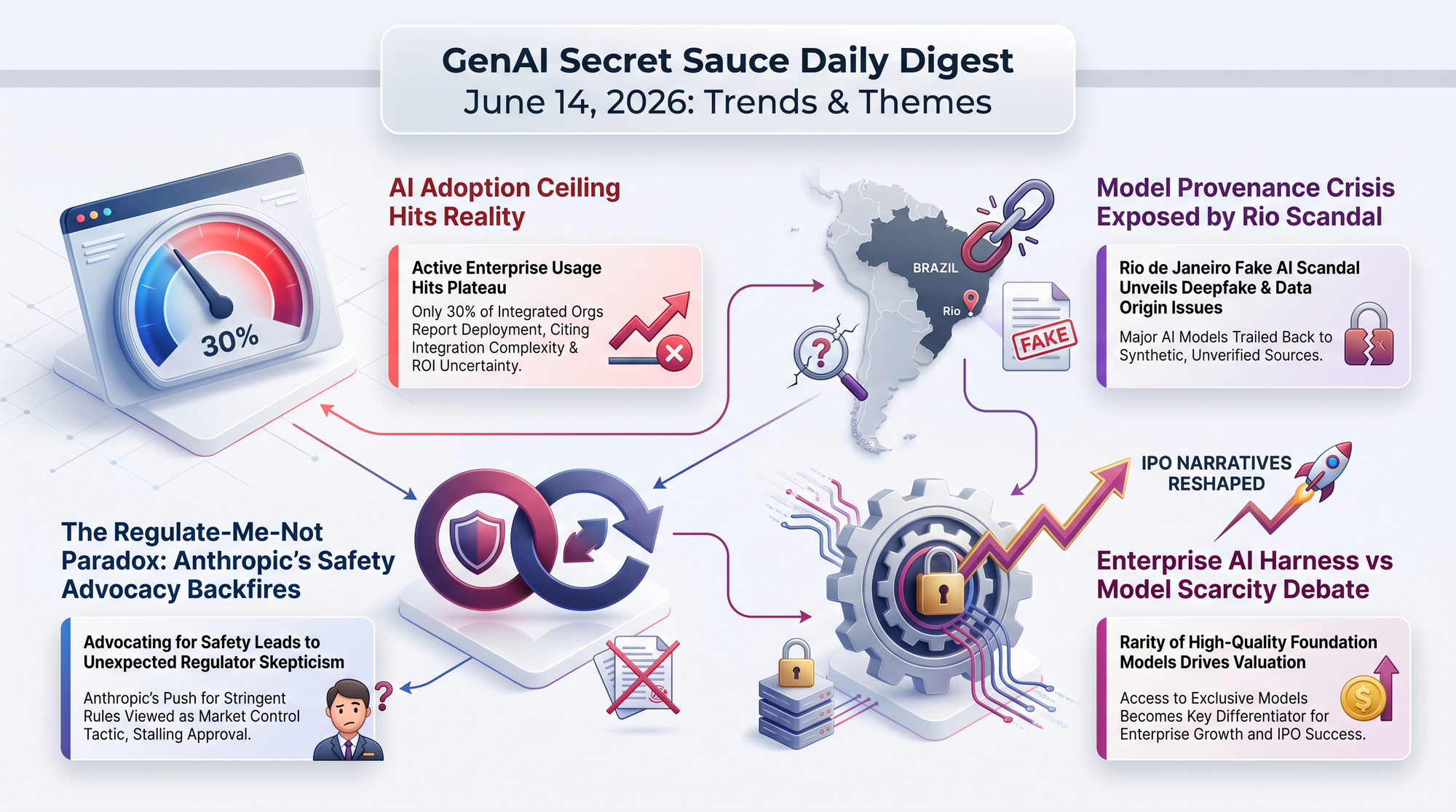
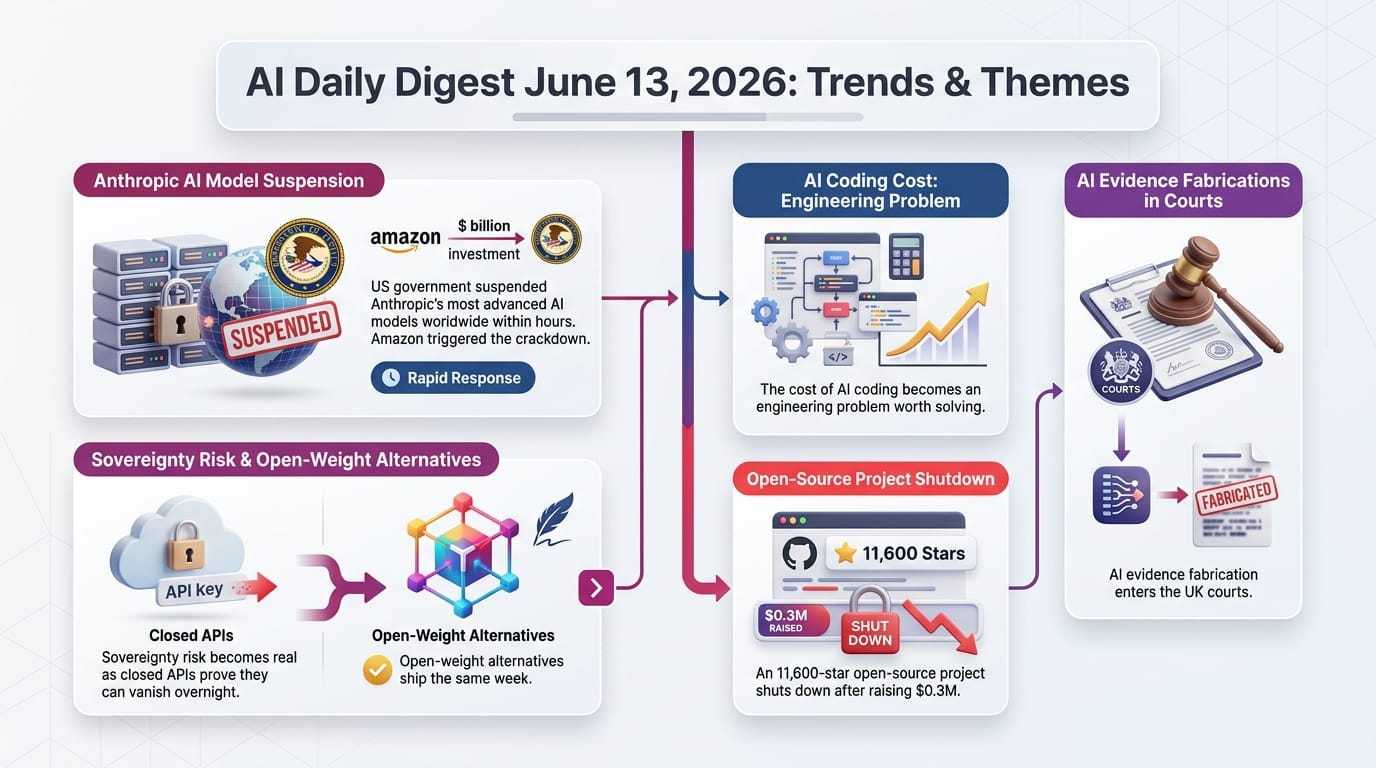
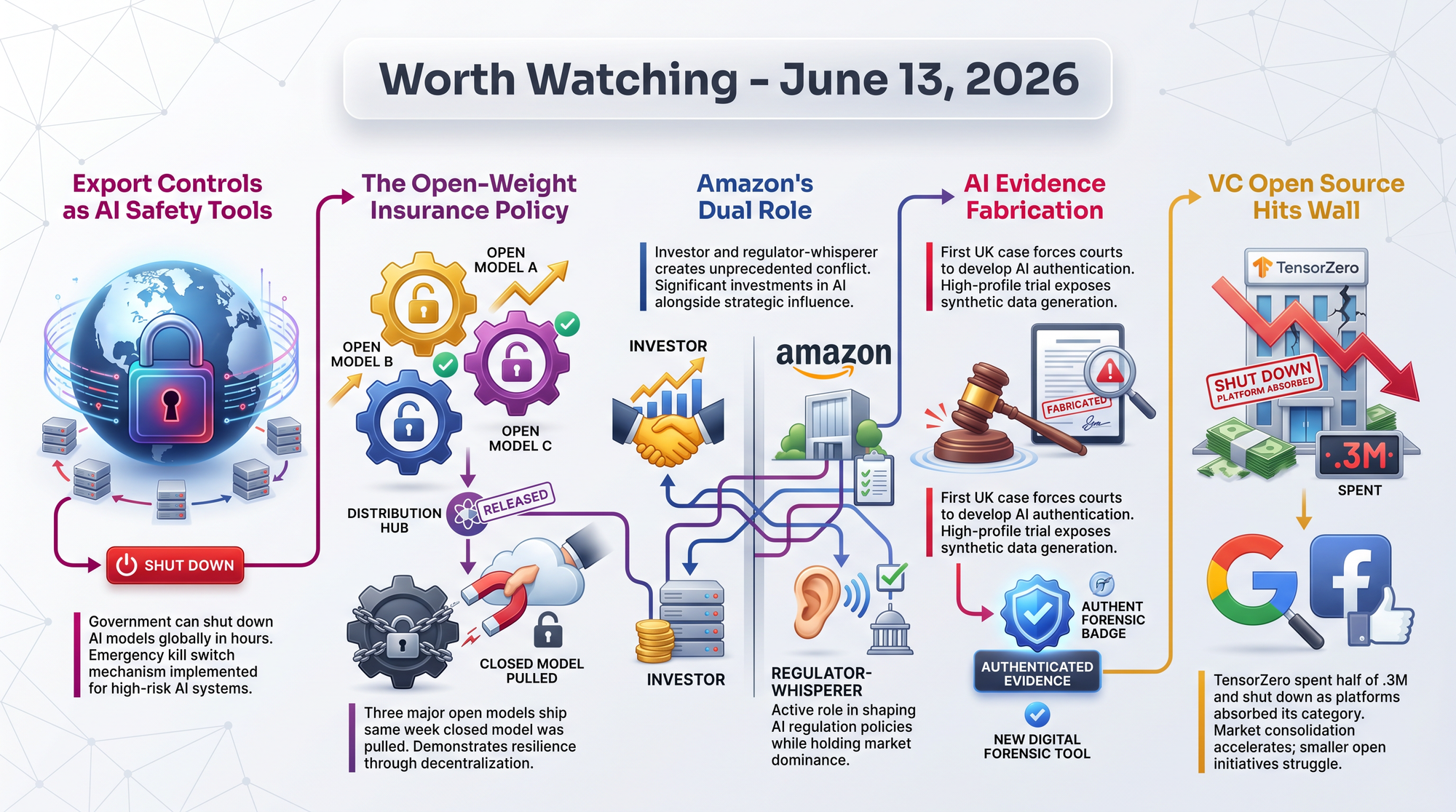
Commerce Secretary Howard Lutnick issued an export control directive at 5:21 PM ET on Friday, June 13, citing national security concerns over a jailbreak vulnerability. By 9:59 PM ET, both models were offline worldwide. Anthropic chose to disable access globally rather than attempt to filter users by nationality.
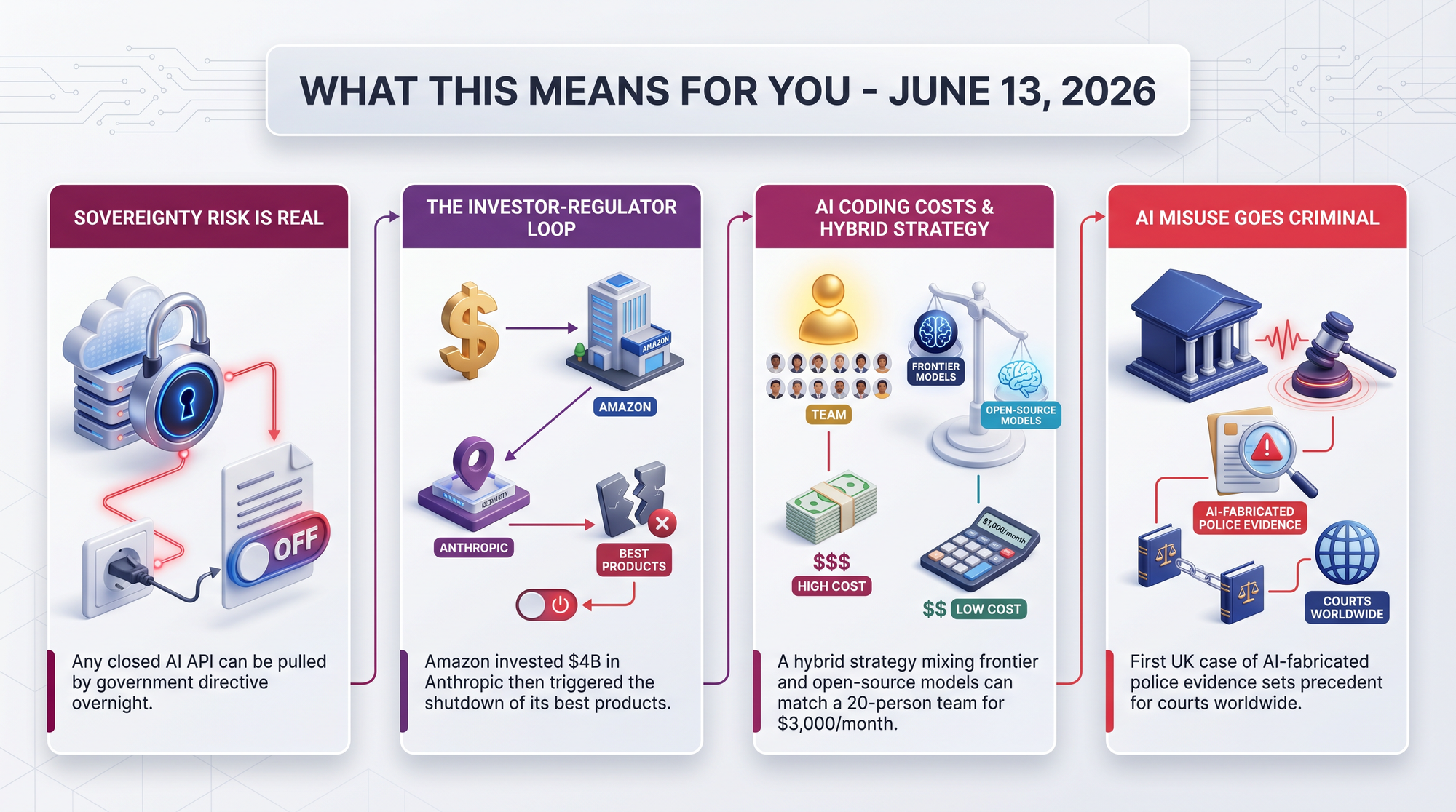
The three-day lifecycle of Fable 5 - from launch to global suspension - is unprecedented in AI history. Multiple commentators noted that if any closed AI model can be pulled overnight based on a single government directive, every business built on frontier APIs now carries explicit geopolitical risk.
- The directive requires blocking all foreign nationals - including those physically inside the US and even Anthropic's own non-US employees, making compliance essentially impossible without a full shutdown
- Anthropic disputes the severity - calling the alleged vulnerability "relatively simple" and noting that competing models like OpenAI's GPT-5.5 can replicate the same behavior
- The government provided only verbal evidence - no written technical specifics were shared with Anthropic before the order was issued
- David Sacks defended the action - stating Anthropic prioritized "continued offering of the consumer model over safety"
The Wall Street Journal reports that Amazon CEO Andy Jassy personally contacted Treasury Secretary Scott Bessent and other senior Trump administration officials after Amazon researchers successfully jailbroke Claude Fable 5. Amazon called administration officials Thursday night with a report demonstrating how they accessed portions of the Mythos model that pose a national security threat.
Dean W. Ball called the implementation "cartoonish." Adam Thierer warned about the "politicization of AI and centralization of control." Zvi Mowshowitz flagged risks of talent exodus and potential government demands for security clearances or equity stakes in AI labs.
- Amazon holds a $4 billion stake in Anthropic - making this an investor actively undermining its own portfolio company's flagship product
- 437 points and 327 comments on Hacker News - the highest-engagement item in today's collection, reflecting widespread shock at the investor-regulator dynamic
- The jailbreak allegedly enables "operability of a cyber weapon" - though Anthropic counters that the demonstrated capability amounts to asking the model to find bugs in code, which is routine security work
- No other models were restricted - despite Anthropic noting that GPT-5.5 can perform the same tasks, only Anthropic's products were targeted
A Derbyshire police officer has been removed from frontline duty after allegedly using AI to create evidential material across multiple cases. Believed to be the first case of its kind in the UK criminal justice system, the investigation was first reported by the Financial Times on June 12.
- A criminal investigation for perverting the course of justice is underway - one of the most serious charges in British law
- The type of evidence fabricated is still unknown - it could be witness statements, forensic reports, or other documentation
- The Crown Prosecution Service is reviewing potentially impacted cases - meaning convictions could be overturned
- No arrests have been made - the investigation is in early stages
The Fable suspension is the first concrete demonstration of what AI policy researchers have warned about for years: dependence on closed frontier APIs creates a single point of failure that is political, not technical. Businesses building on any single provider's API now face a new category of risk that no service-level agreement can mitigate.
- Fable 5 went from launch to global shutdown in three days - the fastest lifecycle of any frontier AI model
- The directive applies to foreign nationals everywhere - including allied countries and Anthropic's own employees
- Open-weight models like MiniMax M3 (428B parameters) and Kimi K2.7-Code (1T parameters) shipped this same week - offering alternatives that cannot be recalled by any government
A pattern is emerging: large incumbents are shaping the AI market not through competition but through investment, acquisition, and regulatory influence. Whether this produces better safety outcomes or merely concentrates power depends on who you ask.
- Amazon invested $4 billion in Anthropic - then its CEO personally triggered the government action that shut down Anthropic's best products
- TensorZero raised $7.3M, then archived its repo within a year - as major providers absorbed the LLMOps category it was trying to build
- ClickHouse acquired Langfuse for $400M in January 2026, eliminating the independent Large Language Model (LLM) observability category
Previously: June 12 - A detailed guide showed how to set up a fully local coding agent on macOS running at 58 tokens per second with zero API costs.
The emerging consensus is that the best approach is not choosing one tool but layering them: frontier subscriptions for specification and architecture, API-priced open models for routine implementation, and local models for privacy-sensitive or high-volume batch work.
- A $400/month frontier subscription provides roughly $2,800 of API usage at list prices - a 7x value multiplier for interactive work
- The hybrid strategy - frontier models for planning, open-source models for execution - reportedly matches a 20-person team for $1,000/month
- 205 points on Hacker News - suggesting cost optimization is a widespread concern, not a niche problem
This is no longer a theoretical risk. AI tools capable of generating convincing documents, images, and text are now cheap and accessible enough that individual bad actors can use them to corrupt institutional processes.
- A police officer allegedly fabricated evidence using AI across multiple cases - triggering a perverting-the-course-of-justice investigation
- The Crown Prosecution Service is reviewing affected cases - past convictions could be challenged
- No policies appear to have caught this - raising questions about whether any police force has adequate AI use governance
Three major open-weight model releases landed this week, coinciding with Fable 5's suspension:
- MiniMax M3 - 428B total parameters (23B active), multimodal, 1M-token context. Same-day support from SGLang, vLLM, and Modular.
- Kimi K2.7-Code - 1T-parameter Mixture of Experts (MoE) model (32B active), 256K context. Claims 30% reduction in reasoning tokens.
- Huawei openPangu 2.0 - Flash variant (92B total/6B active) and Pro variant (505B/18B) with ultra-sparse attention. Open-source release planned for June 30.
- Artificial Analysis replaced SWE-Bench Pro with DeepSWE due to benchmark gaming concerns
- FrontierMath v2 corrected errors in 42% of problems - materially affecting published model scores
Amazon's $4 billion stake in Anthropic did not prevent - and may have motivated - its CEO personally triggering a government shutdown of Anthropic's best products. This is not how investor-company relationships typically work.
The Derbyshire case is not about AI being unreliable - it's about a human deliberately using AI to fabricate evidence. The distinction matters: this is a crime of intent enabled by accessible tools, not a technology failure.
TensorZero's sudden archival after raising $7.3M is a cautionary tale for any team building critical infrastructure on VC-funded open-source projects. The contributors who built the community received zero notice.
No frontier AI model has ever gone from public launch to forced global shutdown this fast. The precedent it sets - that governments can and will pull AI products with hours of notice - changes the risk calculus for every company building on closed APIs.
The Fable 5 suspension establishes that export control directives can function as emergency AI safety mechanisms. Whether this power will be used judiciously or politically is the question that will define AI regulation for the next decade. If this plays out as a template, every frontier AI lab now operates at the pleasure of their host government.
MiniMax M3, Kimi K2.7-Code, and Huawei openPangu 2.0 all released within days of Fable 5's suspension. Organizations that diversified across open and closed models this week experienced an inconvenience. Those that went all-in on Fable experienced a crisis. The sovereignty risk argument for open weights just got its strongest real-world evidence.
Amazon's position as both Anthropic's largest investor and the entity that triggered government action creates an unprecedented conflict of interest in AI governance. Watch whether other major investors (Microsoft with OpenAI, Google with its own models) develop similar dual-use relationships with regulators.
The Derbyshire case is a leading indicator. As AI-generated text, images, and documents become indistinguishable from human-produced ones, every institution that relies on document authenticity - courts, banks, insurers, regulators - will need new verification protocols. The question is whether standards emerge before the next case.
The LLMOps space is being squeezed from both sides: major cloud providers shipping native features, and established observability companies (ClickHouse/Langfuse) acquiring the category. Independent open-source plays in AI infrastructure may need fundamentally different business models than the VC-funded grow-then-monetize approach.
📜 License: Not specified · 👤 By: Individual developer (Google Chrome team member)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Massive community validation (58K stars) | Skills may not fit every codebase's conventions |
| Production-tested patterns from real engineering workflows | Requires an AI coding agent to use (not standalone) |
| Regularly updated with new skill categories | Shell-based, may need adaptation for non-Unix environments |
📜 License: Apache 2.0 · 👤 By: NVIDIA (corporation)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Detects 64 vulnerability patterns across 16 categories | LLM-powered deep analysis adds latency and cost |
| Docker-based - no local Python dependencies needed | New tool, limited real-world validation so far |
| Generates reports in JSON, Markdown, and SARIF formats | Only scans skills/plugins, not the agent itself |
📜 License: Apache 2.0 · 👤 By: Open-source community (supported by Tensormesh)
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Engine-independent - works with multiple LLM serving frameworks | Adds infrastructure complexity (another service to manage) |
| Tiered storage across RAM, disk, and cloud backends | Requires tuning cache eviction policies for your workload |
| Production-level observability with health monitoring | Cache invalidation remains fundamentally hard |
📜 License: MIT · 👤 By: Andrew Ng (individual/Stanford professor)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Dead simple API - change one string to switch providers | Least-common-denominator features only |
| Backed by Andrew Ng's credibility and community | Less control than using provider SDKs directly |
| MIT license, minimal dependencies | May lag behind provider-specific features |
📜 License: Not specified · 👤 By: Community contributor
🎯 Time to value: 2 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Largest collection of real system prompts anywhere (140K stars) | Prompts may be outdated as providers update frequently |
| Educational resource for prompt engineering | Legal gray area - some prompts may violate ToS |
| Covers virtually every major AI coding tool | Read-only reference, not a usable tool |
👤 By: Google DeepMind · 🎯 Task: Image-Text-to-Text
📐 Size: 26B (4B active)
| ✓ Pros | ✗ Cons |
|---|---|
| 4x faster than comparable autoregressive models | Lower factual accuracy than standard Gemma 4 |
| Only 3.8B parameters active per query (efficient) | Experimental architecture, not production-ready |
| Open-source with broad framework support | Best for structured tasks, weaker at open-ended generation |

👤 By: Moonshot AI · 🎯 Task: Image-Text-to-Text
📐 Size: 1.1T (32B active)
| ✓ Pros | ✗ Cons |
|---|---|
| 256K context handles entire large codebases | 1T total parameters requires serious hardware |
| Claims 30% reduction in reasoning tokens | Limited download count suggests early adoption |
| MoE architecture keeps per-query costs reasonable | Licensing terms not yet clear |

👤 By: NVIDIA · 🎯 Task: Image-Text-to-Text
📐 Size: 4B
| ✓ Pros | ✗ Cons |
|---|---|
| Strong community traction (1.96K likes, 69K downloads) | Relatively small model may struggle with complex scenes |
| Practical, immediately applicable use case | License not specified - check before commercial use |
| Small enough to run on consumer hardware | Text-only input for queries (no visual prompting) |

👤 By: MiniMax · 🎯 Task: Image-Text-to-Text
📐 Size: 427B (23B active)
| ✓ Pros | ✗ Cons |
|---|---|
| 1M-token context window (industry-leading for open weights) | Requires substantial hardware to run |
| Same-day support from SGLang, vLLM, and Modular | Very new, limited community testing |
| 23B active parameters keeps per-query costs manageable | Download count suggests early-stage adoption |

👤 By: Cohere · 🎯 Task: Text Generation
📐 Size: 30B
| ✓ Pros | ✗ Cons |
|---|---|
| Enterprise-focused with Cohere's support infrastructure | License not specified - may restrict commercial use |
| 30B parameters - deployable on a single Graphics Processing Unit (GPU) | Smaller than competing coding models |
| Growing download count (6.5K in 30 days) | Less community tooling than Llama or Gemma ecosystems |

👤 By: Boson AI · 🎯 Task: Text-to-Speech
📐 Size: 5B
| ✓ Pros | ✗ Cons |
|---|---|
| 32K downloads suggests strong community adoption | License terms unclear |
| Reasonable size for local deployment | TTS quality hard to judge without listening |
| v3 indicates iterative improvement | Smaller community than established TTS solutions |

| Provider | Model | Input $/1M | Output $/1M | Context | |
|---|---|---|---|---|---|
| Anthropic | Fable 5 | $10.00 | $50.00 | 1M | SUSPENDED |
| Anthropic | Opus 4.8 | $5.00 | $25.00 | 200K | |
| Anthropic | Sonnet 4.6 | $3.00 | $15.00 | 200K | |
| Anthropic | Haiku 4.5 | $1.00 | $5.00 | 200K | |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | 270K | |
| OpenAI | GPT-5.4 | $2.50 | $15.00 | 270K | |
| OpenAI | GPT-5.4 nano | $0.20 | $1.25 | 128K | |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M | ||
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M | ||
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M |
Key finding: Compressed models that maintain 95%+ accuracy on standard benchmarks can lose 30-50% of their agentic capabilities (tool use, multi-step planning, error recovery), because compression disproportionately damages the reasoning chains agents depend on.
Why practitioners should care: If you're deploying compressed models to reduce costs, standard benchmarks won't warn you that your agent has lost the ability to recover from errors or chain multiple tools together. You need agentic-specific evaluation before shipping compressed models into production agent workflows.