Watch today's digest as a video summary (generated by NotebookLM)
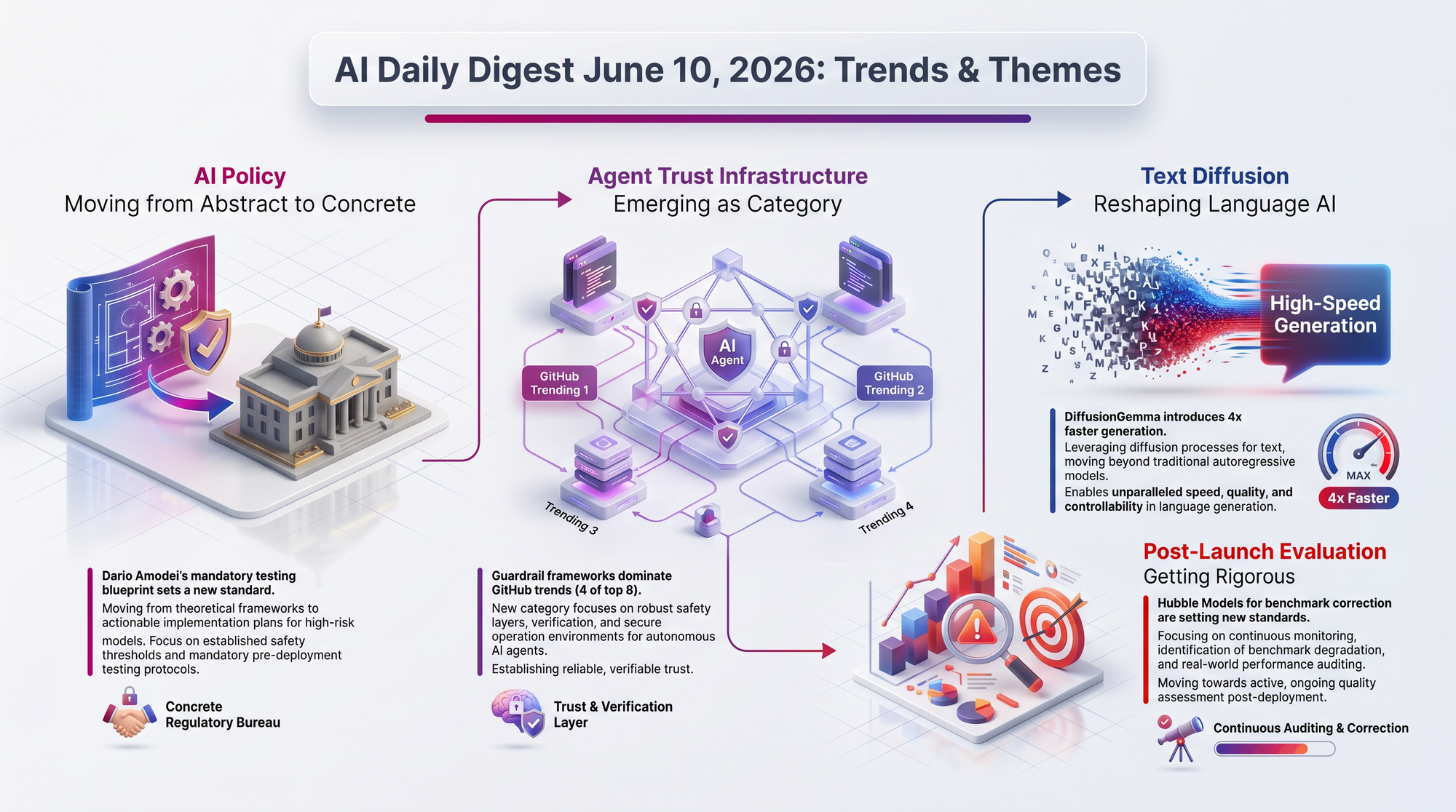
Dario Amodei published "Policy on the AI Exponential," a comprehensive essay laying out five policy areas where he argues government action is now urgent. He opens by noting AI has gone from barely writing code to writing "most of the code at major AI companies" in four years, and describes the trajectory as potentially creating "a country of geniuses in a datacenter."
Anthropic released concrete legislative proposals alongside the essay, and Amodei characterizes existing transparency legislation (SB 53, RAISE, SB 315) as insufficient for current risk levels.
- Mandatory frontier testing - Amodei wants third-party assessments for cybersecurity, biological weapons, autonomous systems, and automated research capabilities before any frontier model can be deployed
- Labor displacement is real and coming - he explicitly calls for "enduring labor displacement" measures including pro-employment incentives and long-term income support, making him one of the first major AI CEOs to endorse structural economic intervention
- Modernize drug approvals - current 7-8 year FDA/EMA timelines need reform for AI-accelerated drug development
- Ban domestic autonomous weapons - alongside closing data broker surveillance loopholes
- Form a democratic AI coalition - controlling semiconductor supply chains while denying equipment to adversaries
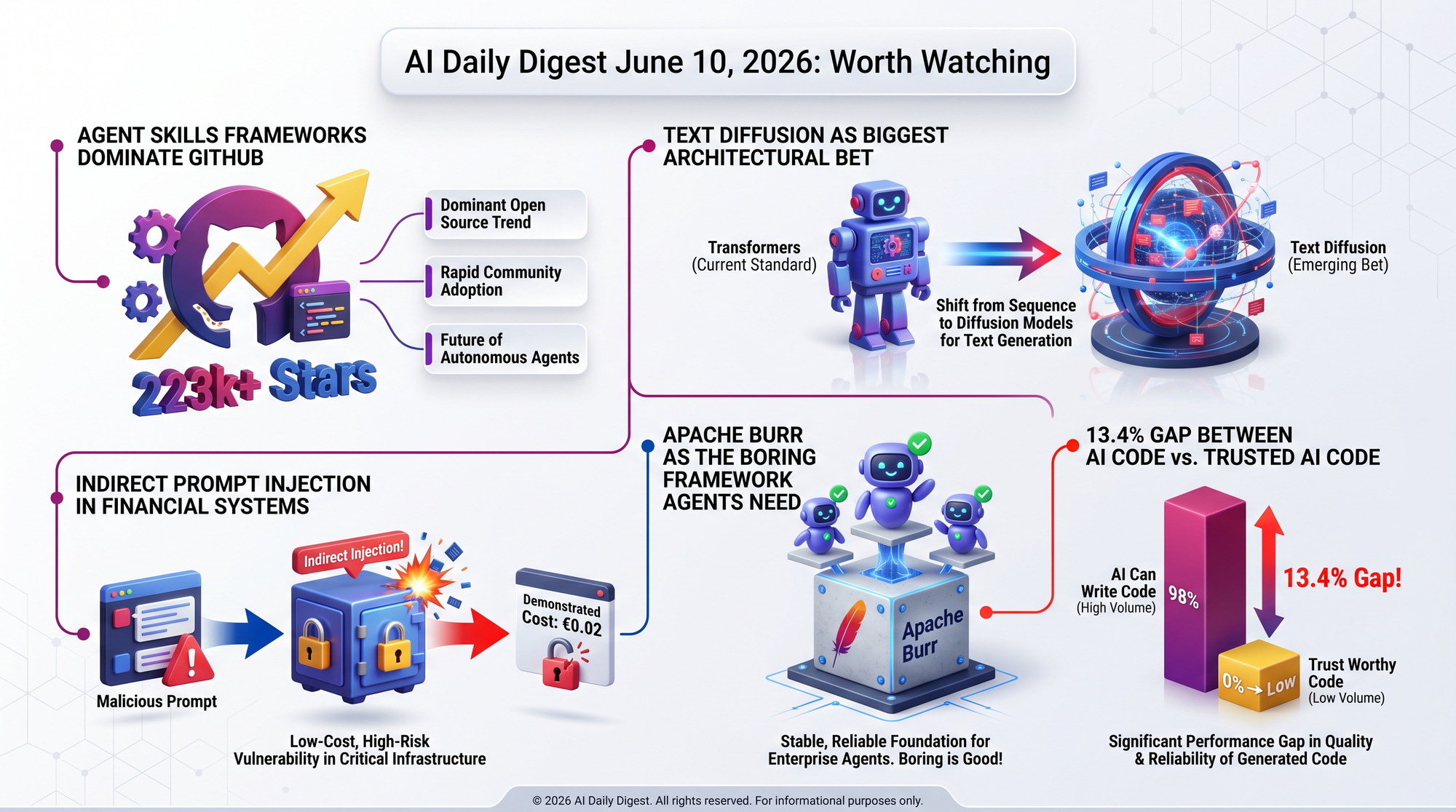
DiffusionGemma is an open-source model (Apache 2.0) that applies diffusion-based parallel token generation to text, a fundamental departure from how every major language model works today. Instead of predicting the next word and then the next, it generates 256-token blocks simultaneously through iterative refinement - starting with random tokens and progressively locking in correct ones.
Model weights are on Hugging Face with integrations for MLX, vLLM, Transformers, and llama.cpp. This is the first major open-source diffusion-based text model from a major lab, and HN engagement hit 262 points.
- 1,000+ tokens/second on NVIDIA H100 and 700+ on RTX 5090, fitting in 18GB of video memory when quantized
- 26 billion parameters total, only 3.8 billion active per query thanks to a Mixture of Experts (MoE) architecture - meaning it punches well above its active weight class
- Bi-directional attention enables self-correction during generation, which is impossible in traditional left-to-right models
- Best for non-linear tasks - code infilling, in-line editing, and mathematical structures where future context matters (demonstrated via Sudoku puzzles)
- Trade-off: lower quality than standard Gemma 4 - Google is explicit that this is an experimental architecture, not a replacement
Security firm Blue41 demonstrated how to compromise bunq's AI assistant (serving 20+ million customers across Europe) using indirect prompt injection via transaction descriptions. The attack is elegant in its simplicity: send a tiny transfer with malicious instructions hidden in the description field. When the victim later asks the AI about their transactions, it retrieves the poisoned data and follows the injected commands.
This is arguably the most concrete, real-world demonstration of indirect prompt injection risk in production financial systems published to date. HN engagement (155 points, 143 comments) reflects the severity.
- Cost to execute: €0.02 - a micro-transfer small enough to go unnoticed
- The attack uses the victim's own real account details to make phishing responses highly credible - the AI has context about the user's actual finances
- The injection surface extends everywhere - payment references, documents, emails, and CRM notes all feed into the AI's context
- Traditional guardrails fail because the malicious payload looks like normal transaction data until the Language Model (LLM) processes it
- Blue41 recommends four defenses - minimize context exposure, treat all retrieved data as untrusted, constrain sensitive outputs, and monitor runtime behavior
Previously: June 9 covered Claude Fable 5's launch and the FrontierCode benchmark showing AI coding still scores just 13.4% on production-quality tasks.
Nate's Newsletter reframes the Claude Code vs. OpenAI Codex comparison as a management philosophy split, not a tool competition. Claude Code represents "steering" - you watch the AI work in real time, redirecting as it goes. Codex represents "dispatching" - you assign a task and check the result later.
- Two distinct failure modes - "theater" (convincing conversation without real understanding) in steering mode, and "completion theater" (finished work that may lack validity) in dispatch mode
- This pattern is spreading beyond coding - into research, sales notes, spreadsheets, legal summaries, and support triage
- The core question isn't capability - it's "when is AI output trustworthy enough to accept without direct oversight?"
- White-collar work is entering a new paradigm where humans increasingly receive machine-generated work they didn't directly supervise

Previously: June 9 covered NSPM-11 giving the government sweeping powers over AI deployment, preventing vendors from disabling models used for national security.
The shift from "we should probably regulate AI" to "here are the specific bills we need" happened remarkably fast. When the CEO of a $200B+ AI company publishes draft legislation to constrain his own products, the Overton window has moved.
- Dario Amodei's essay includes actual legislative proposals for frontier model testing and labor displacement measures - not just principles, but draft policy language
- Jeremy Howard argues AI labs should voluntarily restrict their own compute growth until safety catches up, calling out the hypocrisy of labs racing to build while warning about risks
- China-linked influence operations are now targeting US AI policy debates specifically, according to a new OpenAI report, making AI governance itself a geopolitical battleground
The pattern is clear: as AI agents gain real capabilities (file access, code execution, Application Programming Interface (API) calls), the market is racing to build the oversight layer. "Did the agent actually do what it said?" is becoming as important as "can the agent do the task?"
- Four of today's top eight GitHub trending repos are agent guardrail frameworks: superpowers (223k stars), agent-skills (52k), last30days-skill (39k), and hivemind (806)
- Timmy-TUI creates cryptographic "sealed receipts" proving exactly what an AI agent did during a session - a tool built for a world where agents have filesystem and network access
- Spotlight by Backplanes generates session reports for Claude Code and Codex, turning agent transcripts into auditable evidence
- The bunq banking vulnerability demonstrates why this category exists - without runtime monitoring and output constraints, agents that retrieve external data become attack vectors
If text diffusion matures to match autoregressive quality, it could make local AI dramatically faster on consumer hardware. Today it's experimental; in 12 months it could be the default for latency-sensitive applications.
- DiffusionGemma's 256-token parallel generation is architecturally different from every shipping LLM - it applies the same technique that makes image generation work to text
- Bi-directional attention lets the model look forward and backward simultaneously, enabling self-correction mid-generation that autoregressive models can't do
- The trade-off is quality - Google explicitly says output is lower quality than standard Gemma 4, making this a speed-vs-quality frontier, not a free improvement
- Non-linear tasks benefit most - code completion where you need to fill in the middle, not just predict the next line, and mathematical structures where future context constrains earlier tokens
Previously: June 9 - FrontierCode showed the best AI scores just 13.4% when evaluated like a tech lead, versus 50%+ on traditional benchmarks.
The sophistication of model evaluation is catching up with the sophistication of models. The question is shifting from "how well does it score?" to "is the score even measuring the right thing?"
- Alpha Signal tested Claude Fable 5 on tasks where the success metric was deliberately misleading - the model's real test was knowing when the metric was wrong, not optimizing for it
- A new arXiv paper proposes "Hubble Models" that deliberately contaminate training data at known rates to statistically correct for benchmark inflation, accepting contamination as inevitable rather than trying to prevent it
- The Deterministic Horizon paper quantifies exactly when chain-of-thought reasoning fails (19-31 steps) and tool delegation becomes architecturally necessary, not just helpful
- End-to-end pipeline integrates 6+ Language Model (LLM) providers (OpenAI, Claude, Gemini, DeepSeek), stock footage from Pexels/Pixabay, Text-to-Speech (TTS) narration, automatic subtitles, and background music
- Batch generation and web UI let content creators produce multiple videos without touching a video editor
- Latest v1.3.0 release shipped today, showing active maintenance
- 85,000 stars and +1,471 today - one of the highest-velocity creative AI tools on GitHub
A data visualization mapping every Japanese train station from 1872 to 2026, revealing how rail expansion followed geography - "Japan's rail map is secretly a map of rice paddies, rivers and mountains." Peak year: 1929 with 272 new stations. The creator notes the first line was 29km of British-built track from Shimbashi to Yokohama. While not AI-generated, it represents the intersection of data storytelling and interactive visualization. 176 HN points.
- Tool-integrated reasoning achieved 86-94% accuracy vs. 24-42% for pure chain-of-thought across 12 models and 8 task domains
- The "Deterministic Horizon" sits at 19-31 reasoning steps - beyond that point, decoder-only transformers hit information-theoretic limits causing super-exponential accuracy decay
- Fine-tuning on optimal traces yielded under 5% improvement - confirming this is an architectural limit, not a training gap
- High cross-model correlation (r=0.81-0.91) means this applies regardless of which LLM you use
A new approach to the benchmark contamination problem: instead of trying to prevent models from seeing test data (nearly impossible at web scale), intentionally contaminate at known rates to statistically correct for inflated scores. The "Hubble Models" framework uses paired models - one deliberately contaminated, one clean - to establish counterfactuals. Calibration requires only ~10 examples and transfers across datasets.
An ICML 2026 Workshop paper examining how long-lived AI agents that remember users across interactions create memorization dynamics that don't exist during training - a deployment-time privacy risk that current safeguards don't address.
Previously: June 9 covered Claude Fable 5's launch and benchmark scores.
Alpha Signal tested Fable 5 on three Machine Learning (ML) tasks designed to have misleading success metrics. The model demonstrated an ability to recognize when a metric was wrong and adjust accordingly - testing judgment rather than raw capability. This meta-evaluation approach (testing whether models can evaluate their own evaluations) is itself an emerging research direction.
Jeppe Stricker argues universities' attempts to plan for AI are undermined by "gravity" - the invisible pull of existing systems that drags innovative thinking back to incremental improvements. Institutions that plan 5-year AI strategies end up with slightly better versions of what they already have, not the transformations they need.
- Universities optimize for control, not learning - AI threatens the assessment structures that make institutional control possible
- The planning horizon mismatch - AI capabilities are doubling on 6-12 month cycles while university planning operates on 3-5 year cycles
- Most institutional AI strategies are defensive - focused on policing AI use rather than integrating it into pedagogy
Lance Eaton argues the fundamental bargain of higher education - invest tens of thousands for career preparation - is increasingly mismatched with what institutions actually deliver. Students are expected to navigate complex bureaucracies, decode hidden curricula, and fund their own education with minimal transparency about outcomes, while AI tools that could reduce this friction are being banned rather than integrated.
Ruben Hassid's newsletter reveals that 90% of companies have employees using personal AI accounts for work, 57% have entered sensitive information, and 22% use personal AI even when their company provides one. The Samsung incident (engineers leaked source code to ChatGPT three times in 20 days) is cited as the canonical cautionary tale. The article catalogs legal exposures including NDA breaches, trade secret violations, and GDPR violations.
A satirical blog post imagining Anthropic's literary naming scheme (Haiku, Sonnet, Opus, Fable) extended to absurd lengths: Aphorism (budget tier), Diatribe (mid-range), Saga Enterprise Edition, and "Cinematic Universe (Director's Cut)" with "42% more tokens." Hit 249 HN points - suggesting the pace of model releases is itself becoming a punchline.
Simon Willison quotes Jeremy Howard's proposal that AI labs should voluntarily restrict their own compute growth until safety research catches up. Howard identifies a contradiction: labs simultaneously warn about AI risks while racing to build ever-more-powerful systems, calling this the central hypocrisy of the current AI landscape.
OpenAI published a report documenting PRC-linked influence operations specifically targeting AI governance conversations in the United States - making AI policy itself a vector for foreign influence.
Four of today's top eight GitHub trending repos are guardrail frameworks for AI coding agents - superpowers (223k stars, +1,205 today), agent-skills by Google's Addy Osmani (52k stars), last30days-skill (39k stars, +2,561 today), and hivemind for multi-agent shared memory. If this pattern holds, "agent discipline" could become as important a category as "agent capability." For ordinary people, this means AI coding tools are about to get noticeably more reliable - the community is solving the "it sometimes breaks everything" problem.
DiffusionGemma is experimental and lower quality than standard models. But the approach - generating text in parallel blocks instead of one token at a time - solves a fundamental bottleneck. Watch for quality improvements over the next 6-12 months. If diffusion-based text generation reaches autoregressive quality, it transforms the economics of local AI and makes real-time applications (live translation, instant code completion) dramatically more responsive.
The banking AI vulnerability isn't a theoretical risk paper - it's a demonstrated attack against a real bank with 20+ million customers, using infrastructure (transaction descriptions) that every bank already has. The defense recommendations (minimize context, treat retrieved data as untrusted, constrain outputs, monitor runtime) apply to any AI system that retrieves external data. If you're building Retrieval-Augmented Generation (RAG) applications, this case study is required reading.
Most agent frameworks are either VC-backed (pressure to add features) or single-maintainer (bus factor of one). Burr's Apache incubation means community governance and a mandate for stability over novelty. Developers report onboarding in hours vs. days with alternatives. If the "boring infrastructure" pattern from web development repeats in AI (Express.js, Flask), Burr's positioning is strong.
The FrontierCode benchmark from yesterday, Nate's steering-vs-dispatching framework, and the explosion of agent guardrail repos all point to the same gap: AI can write code, but the question of whether to trust it is unsolved. The tools and methodologies filling this gap - verification, auditing, sealed receipts - are likely to be as valuable as the coding agents themselves.
📜 License: MIT · 👤 By: Individual (Jesse Vincent/Prime Radiant)
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Works across all major AI coding agents | Heavy methodology may feel over-engineered for small scripts |
| Enforces TDD and evidence-based verification | Shell-based skill files can be opaque to debug |
| Massive community with active development | Requires buy-in to the full 7-step workflow |
📜 License: MIT · 👤 By: Individual
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Truly end-to-end pipeline in one tool | Output quality depends on stock footage availability |
| Integrates with 6+ LLM providers | Primarily Chinese-language documentation |
| v1.3.0 release today shows active maintenance | Generated videos can feel formulaic |
📜 License: MIT · 👤 By: Individual
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Aggregates 9+ platforms including prediction markets | Requires API keys for each platform |
| Ranks by authentic engagement, not algorithmic curation | 30-day window may miss important older context |
| Mature codebase with 623 commits | Quality depends on the underlying LLM |
📜 License: MIT · 👤 By: Individual (Google Chrome team lead)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Created by a respected Google engineering leader | Shell-based format ties it to specific runtimes |
| Anti-rationalization tables counter agent shortcuts | 23 skills can overwhelm teams needing few guardrails |
| Covers the full lifecycle from spec to ship | Opinionated workflow may clash with existing processes |
📜 License: MIT · 👤 By: Company (Roboflow)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Model-agnostic, works with any detection framework | Limited to 2D bounding box and polygon workflows |
| Battle-tested with 44k stars and active Roboflow backing | No built-in training pipeline |
| Rich annotation tools for video analysis | Heavier dependency than minimal alternatives |
📜 License: Apache 2.0 · 👤 By: Individual
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Fully on-device, no cloud data transmission | Not a substitute for professional medical advice |
| Apache 2.0 license allows commercial healthcare use | Smaller model size limits complex reasoning |
| Purpose-built for clinical workflows | Early stage (2.3k stars) with less community validation |
📜 License: Apache 2.0 · 👤 By: Company (Activeloop)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Solves the "agents working in silos" problem | Very early stage (806 stars) |
| Backed by Activeloop (established data infrastructure company) | Shared state introduces coordination complexity |
| Apache 2.0 license | Limited documentation for production deployments |
📜 License: MIT · 👤 By: Individual
🎯 Time to value: 60 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Complete pipeline from tokenization to evaluation | Resulting models are toy-scale, not production-usable |
| Educational focus with explanations at each stage | Requires Graphics Processing Unit (GPU) access for meaningful training runs |
| MIT license, freely reusable | Focuses on fundamentals, not cutting-edge techniques |

👤 By: Google · 🎯 Task: Multimodal
📐 Size: 12B
| ✓ Pros | ✗ Cons |
|---|---|
| True multimodal: text + image + video + audio | Gemma license is permissive but not fully open |
| 12B fits on consumer GPUs with quantization | Smaller than frontier models, so ceiling is lower |
| Strong benchmark performance for its size | Newer model with less community tooling |

👤 By: NVIDIA · 🎯 Task: Visual Grounding
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| Natural language input, no predefined object classes | 3B model may struggle with very complex scenes |
| CC-BY-4.0 license allows broad commercial use | Bounding boxes only, no segmentation masks |
| Runs efficiently on consumer hardware | Limited to single-image, no video tracking |

👤 By: Ideogram AI · 🎯 Task: Text-to-Image
📐 Size: 9.3B
| ✓ Pros | ✗ Cons |
|---|---|
| Best-in-class text rendering in generated images | Custom license limits some commercial uses |
| 9.3B parameters for high-quality output | Large model requires significant GPU memory |
| FP8 quantization reduces memory requirements | Requires Diffusers library integration |

👤 By: BosonAI · 🎯 Task: Text-to-Speech
📐 Size: 4B
| ✓ Pros | ✗ Cons |
|---|---|
| 102 languages with zero-shot voice cloning | 4B parameters requires decent GPU |
| Apache 2.0 license, fully open for commercial use | Quality varies across less-common languages |
| Single-sample voice cloning, no fine-tuning needed | Autoregressive generation means sequential output |

👤 By: NVIDIA · 🎯 Task: Automatic Speech Recognition
📐 Size: 600M
| ✓ Pros | ✗ Cons |
|---|---|
| Only 600M parameters - runs on phones and edge devices | NVIDIA Commercial license restricts some uses |
| Streaming architecture for real-time transcription | 40 languages is comprehensive but not exhaustive |
| Multilingual without language detection overhead | Smaller than cloud ASR, so accuracy ceiling is lower |

👤 By: Cohere · 🎯 Task: Code Generation
📐 Size: 30B (3B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Only 3B active parameters, runs on consumer GPUs | MoE architecture has higher memory footprint than dense 3B |
| Apache 2.0 license, fully open | Specialized for code, not general-purpose |
| Designed for agentic multi-step tasks | Newer model with less community validation |

💰 Pricing: Freemium · 🏷 Category: API / Social Media / Developer Tools

💰 Pricing: Paid · 🏷 Category: AI Chatbots / Productivity
💰 Pricing: Free · 🏷 Category: Developer Tools / Security
💰 Pricing: Included with Google AI Ultra · 🏷 Category: Translation / Audio

💰 Pricing: Freemium · 🏷 Category: Video / Generative Media

| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Fable 5 | $10.00 | $50.00 | 1M |
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200k |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | N/A |
| OpenAI | GPT-5.4 | $2.50 | $15.00 | N/A |
| OpenAI | GPT-5.4-Mini | $0.75 | $4.50 | N/A |
| OpenAI | GPT-5.4-Nano | $0.20 | $1.25 | N/A |
| Gemini 3.5 Flash | $1.50 | $9.00 | N/A | |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | N/A | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | N/A | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128k |
| Groq | Llama 3.1 8B Instant | $0.05 | $0.08 | 128k |
Key finding: Tool-integrated reasoning achieved 86-94% accuracy vs. 24-42% for pure chain-of-thought across 12 models and 8 task domains. Fine-tuning on optimal traces yielded under 5% improvement - confirming architectural limits, not training gaps.
Why practitioners should care: Gives engineers building AI agents a concrete, quantified answer to "when should my LLM call a tool vs. think harder?" If a task requires tracking more than ~20-30 state variables or steps, tool delegation is not optional but architecturally necessary. High cross-model correlation (r=0.81-0.91) means this applies regardless of which LLM you use.