Watch today's digest as a video summary (generated by NotebookLM)
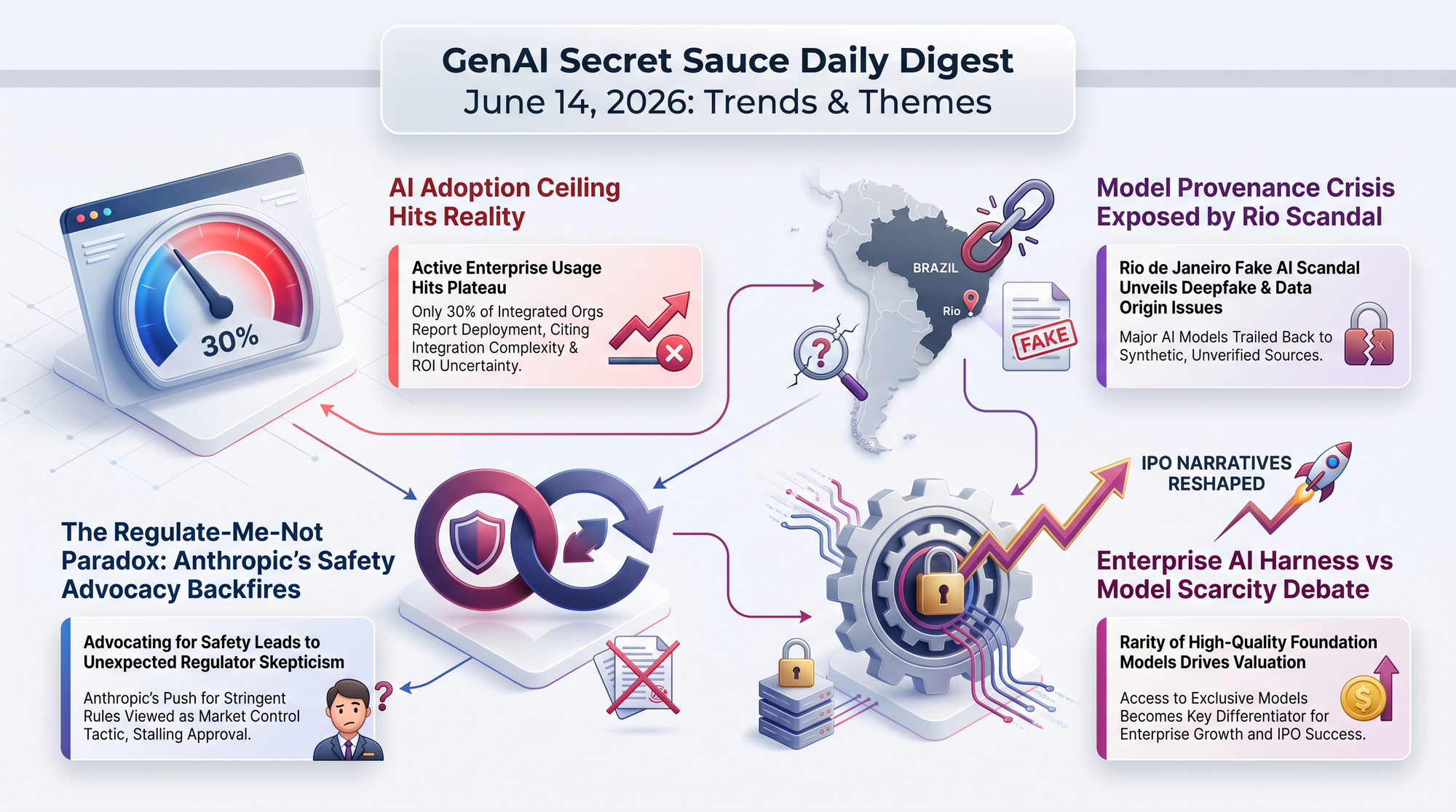
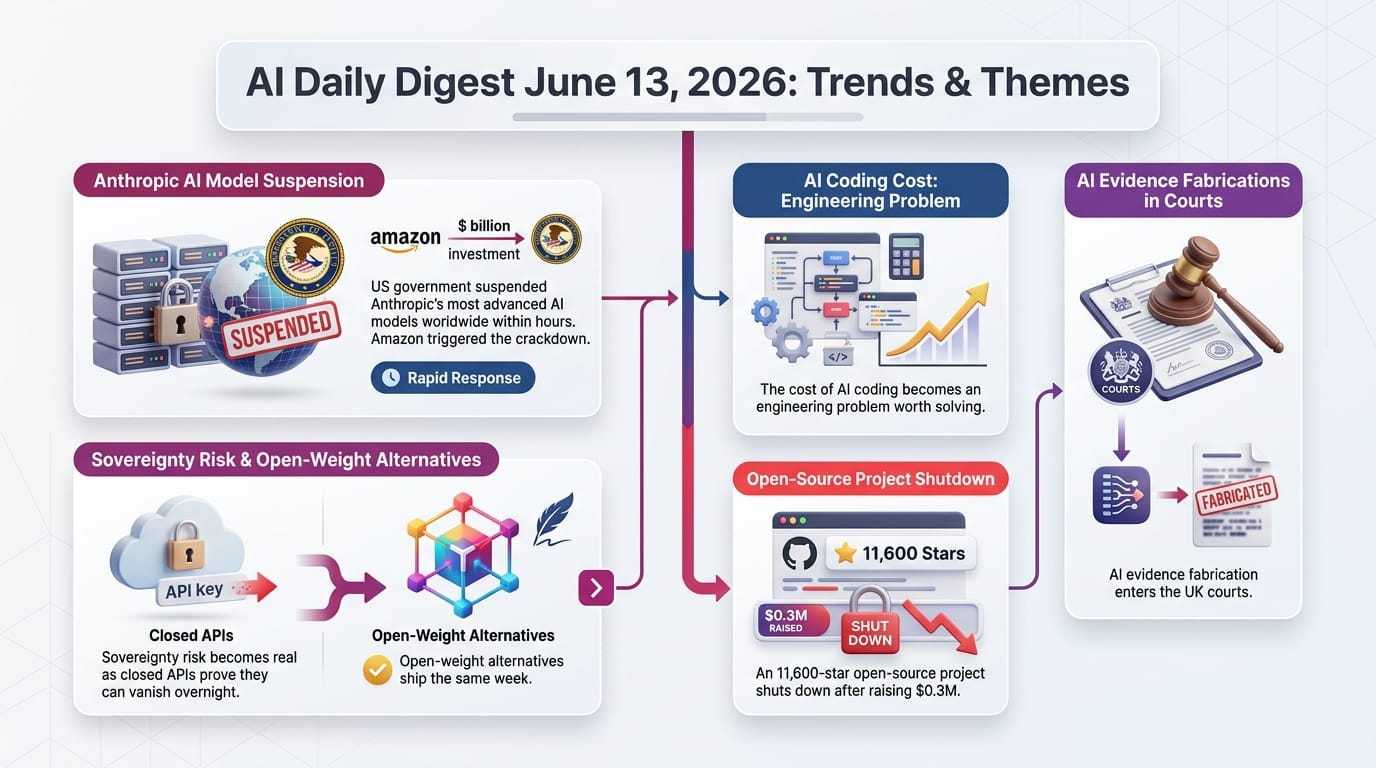
> Previously: June 13 - The US government ordered Anthropic to pull Fable 5 and Mythos 5 via export controls after a jailbreak disclosure.
Today: Anthropic's technical team is physically in Washington meeting with White House officials. Virtual discussions began the day the export controls were issued. Key personnel in Commerce Department meetings include Logan Graham (Frontier Red Team lead), Dave Orr (Head of Safeguards), and Nicholas Carlini.
- The government's stated bar for restoration is either making the models completely jailbreak-resistant (which officials privately acknowledge "may be impossible") or resolving what one source described as stakeholders feeling "dismissed" rather than "safe, secure and happy"
- Anthropic's position is that the security issue is "not serious enough to restrict global rollout" and characterizes the situation as a "misunderstanding"
- The tone from both sides suggests pessimism about near-term restoration - the dispute has moved beyond technical safeguards into a fundamentally relational conflict
> Previously: June 14 - Critics debated whether Anthropic's own AI safety advocacy created the mechanism used against them.
Today: Zvi Mowshowitz published a detailed reconstruction of events. The timeline is tighter than previously reported.
- Thursday evening: Amazon called government officials about discovering a narrow jailbreak in Fable 5
- Friday evening: Export controls were imposed - less than 24 hours later. Anthropic was given 90 minutes to comply without receiving any technical details justifying the emergency
- Government officials falsely claimed CEO Dario Amodei was at a wellness retreat and unreachable. Multiple witnesses confirmed he was available within 75 minutes
- The jailbreak itself was a narrow issue that, according to Zvi, "GPT-5.5 can already produce without requiring any bypass"
- Zvi's assessment: The decision reflects "vibe governing" based on perceived disrespect, not technical analysis. Evidence points toward retaliation for Anthropic's refusal to comply instantly without explanation
New York's WARN Act began requiring companies to disclose whether AI contributed to workforce reductions in March 2025. In the first year, more than 160 companies filed WARN notices. Not a single one checked the AI box.
- The argument: Software engineering - a field seemingly vulnerable to automation - has not experienced AI-driven disruption. If it hasn't happened there, most other professions are "likely to be even more cushioned"
- Three bottlenecks AI cannot automate: Deciding and specifying what to build, verifying and being accountable for what ships, and deep contextual knowledge of codebases and business needs
- Key insight: AI accelerates coding but cannot replace human judgment about what to build and why. The job title stays; the job description shifts
Sequent, a new alignment research startup, was founded by researchers from the UK AI Security Institute and Timaeus. Their core claim: current AI lab safety efforts won't deliver confidence in superintelligent AI safety before development occurs.
This comes the same week Anthropic's own models were pulled by government order over safety concerns, adding urgency to the question of whether any lab has alignment under control.
- Target scale: 40-80 employees within two years, with a $100-150M initial funding goal
- Research priorities: Scalable oversight, learning theory, game theory, and understanding when safety learned during training generalizes to real-world deployment
- The gap they see: Major labs' safety approaches remain reactive rather than principled - the field lacks a rigorous theory of when and why alignment techniques actually work
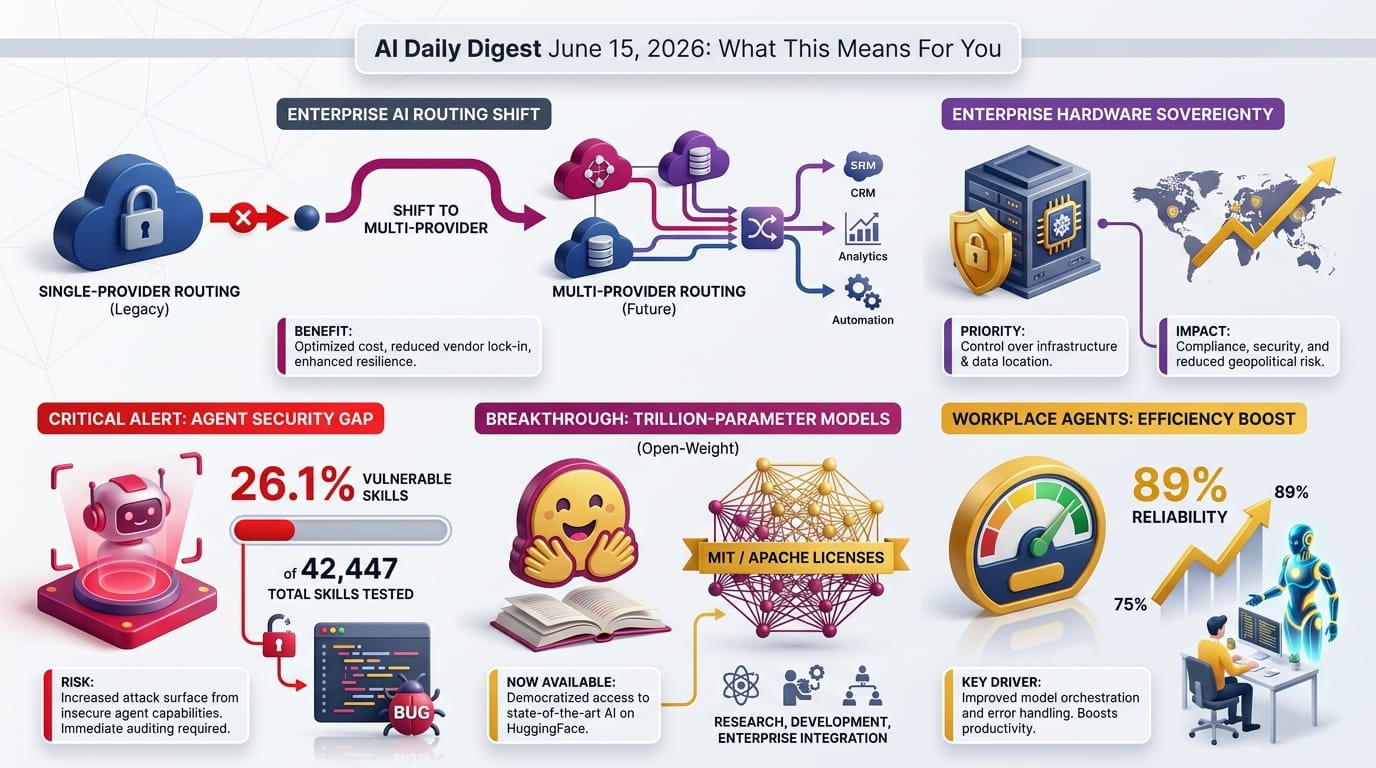
NVIDIA released SkillSpector, an open-source security scanner that checks AI agent skills before installation. The tool emerged from research auditing 42,447 real-world skills across the agent ecosystem.
The timing matters: as AI coding agents proliferate and the skills ecosystem grows, the attack surface grows with it. SkillSpector is the first major vendor-backed tool specifically designed to scan this surface.
- 26.1% of skills contain vulnerabilities including prompt injection, data exfiltration, and privilege escalation
- 5.2% show likely malicious intent - not bugs, but deliberate attack patterns
- 64 vulnerability patterns across 16 categories, grounded in OWASP Top 10 for Large Language Model (LLM) Applications, OWASP Top 10 for Agentic Applications 2026, and MITRE ATLAS
- The tool is free and accepts Git repos, URLs, zip files, directories, or single files. Static checks run in seconds; optional LLM-powered semantic analysis catches intent-based issues
- The target pain point is the hours spent cleaning raw footage before creative editing begins
- Claude-powered content understanding lets these tools detect context (not just audio levels) when deciding what to cut
- Caveat for professionals: Cloud-based processing may be a dealbreaker for NDA-bound work - local inference alternatives are still catching up
- Claude Opus 4.8 leads at 89% task completion on the WorkBench benchmark, up from GPT-4's 43% in March 2024
- Harmful unintended actions (wrong emails, wrong files) dropped from 26% to 2.5%
- Capability and safety improved together - more capable models also performed safer actions
- DECOMPBENCH tests this systematically with a graphical decomposition framework
- High refusal on whole tasks but "significantly lower refusal rates" on decomposed variants
- Implication: Safety testing that only checks monolithic requests will miss real-world attack patterns
- Pairwise preferences flipped 13.6% on average across repeated identical trials
- 28% of questions exceeded 20% flip rates - nearly one in three questions is a coin flip
- Cross-judge agreement was only 76% (kappa = 0.51, "moderate" reliability)
- GPT-4o-mini showed significant first-position bias - 72% preference for whichever option appeared first
- Accepted at DAC 2026
- Uses data sketch techniques combined with hardware-optimized implementations
- Targets resource-constrained deployment - making large models run on smaller hardware
The leaked 120,000-character, 1,585-line system prompt reveals that Fable is built as infrastructure for multi-stage agent work, not conversational AI. The prompt is less "personality script" and more "operating manual" - tool schemas, search rules, safety postmortems, and an identity line that does not appear until line 1,351. Copyright enforcement is strict: quoting 15+ words from any source is flagged as a "SEVERE VIOLATION."
Anthropic co-founder Chris Olah publicly responded to the Vatican's encyclical on artificial intelligence, marking one of the first direct engagements between frontier AI researchers and religious institutional frameworks for AI ethics. With 1.4 billion Catholics globally, the Vatican's position on AI carries institutional weight that few technology commentators have acknowledged.
A government source told Axios that restoring Fable access requires either making models "completely jailbreak-resistant" or resolving an emotional dynamic. AI researchers broadly agree that complete jailbreak resistance is not achievable with current techniques - which means the government may have set a bar it knows cannot be met.
FrontierCode's Diamond tier represents the hardest real-world coding challenges. Claude Opus 4.8 leads at 13.4%, GPT-5.5 scores 6.3%, and Claude Opus 4.7 hits 5.2%. The prediction: 70%+ by June 2027. If true, that is a 5x improvement in one year.
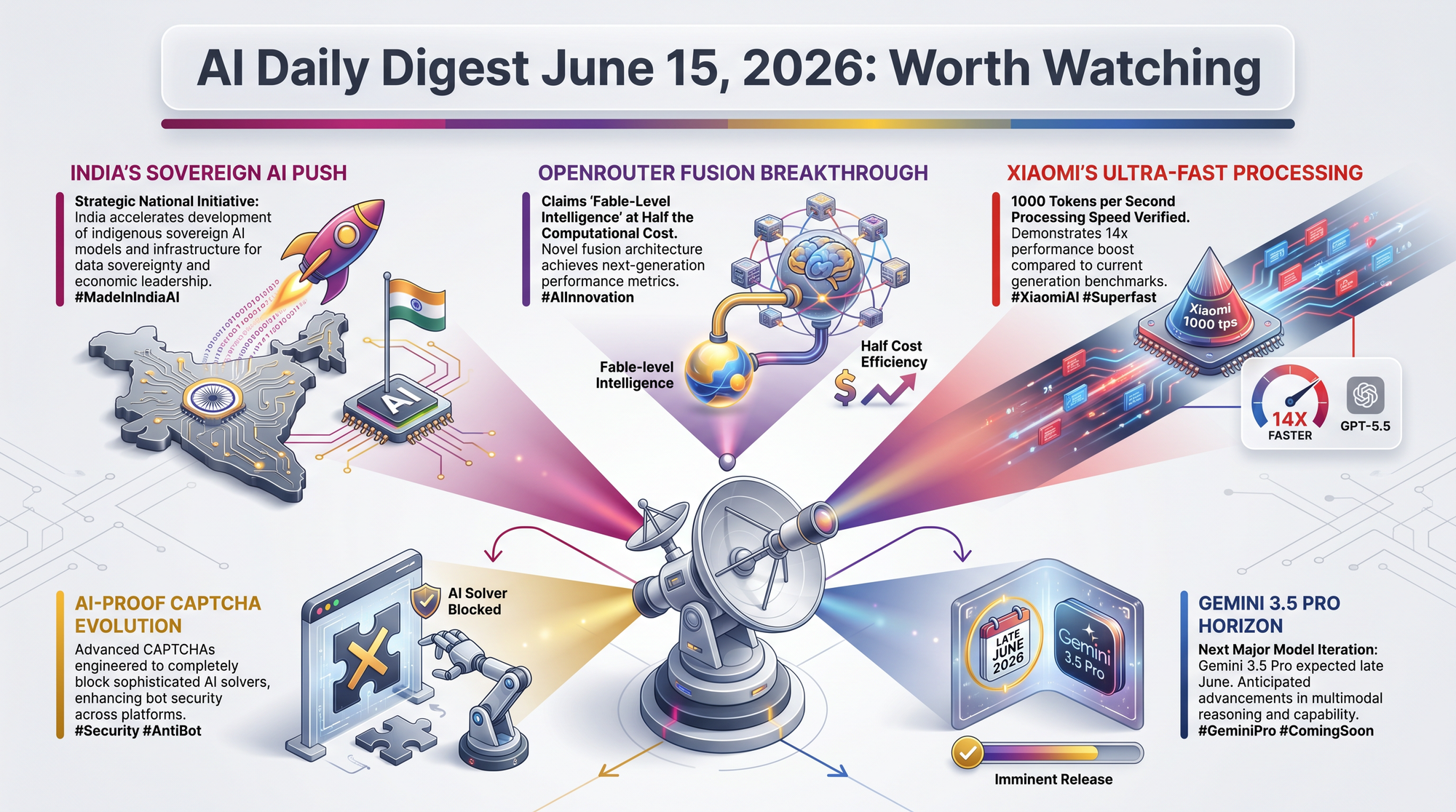
India's tech community reacted to the Fable ban by amplifying calls for domestic AI development. Finance Minister statements, industry commentary, and developer forums all converged on the same message: dependence on foreign AI providers is a strategic vulnerability. If India invests seriously in sovereign AI capability, it could reshape global AI competition. If not, it becomes a recurring talking point that goes nowhere.
OpenRouter's Fusion sends your prompt to 3-5 models simultaneously, then a judge model synthesizes the best answer. The system claims performance close to frontier models at roughly half the cost. If it delivers consistently, it undermines the case for paying premium prices for any single model.
MiMo-V2.5-Pro-UltraSpeed runs at 1,000+ tokens per second on commodity 8-GPU hardware - compared to 68 tok/s for GPT-5.5 and 71 tok/s for Claude Opus. The trial API runs through June 23. If sustained in production, this speed advantage could make real-time AI applications viable that are impractical at current Western inference speeds.
COGNITION (USENIX Security 2026) found that while multimodal LLMs solve recognition-based CAPTCHAs at human-like rates, targeted defenses reduced AI success from 95% to 0%. Fine-grained localization and multi-step spatial reasoning remain hard for models. This means CAPTCHA providers have effective tools if they choose to deploy them.
Polymarket traders are concentrating odds on a June 23-30 release window for Gemini 3.5 Pro, with a 2-million-token context window, Deep Think reasoning mode, and expected pricing of $15/$60 per million input/output tokens. If it ships on schedule, it would be the first new frontier model release since the Fable ban.
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Zero API costs for social media access | Browser-based extraction can break with platform changes |
| Compatible with major AI coding agents | Rate limiting not well documented |
| Covers 6 major platforms | Depends on maintained browser automation |
📜 License: MIT · 👤 By: Company (trycua)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Full desktop OS support (Mac/Linux/Windows) | Requires significant compute for VM sandboxes |
| Includes benchmarking tools | Setup complexity for cross-platform testing |
| MIT license, production-quality | Limited community documentation |
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 503 lessons, completely free | 320 hours is a serious time commitment |
| Builds understanding from first principles | May be overkill for pure API users |
| Active community (33K+ stars) | Self-paced means no accountability structure |
📜 License: Apache-2.0 · 👤 By: NVIDIA
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Backed by NVIDIA research (42K+ skills audited) | LLM semantic analysis requires API access |
| Fast static checks run in seconds | Cannot catch runtime-only vulnerabilities |
| Apache 2.0, free to use | Focused on pre-install scanning only |
📜 License: MIT · 👤 By: Research lab
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Peer-reviewed (AAAI 2026) | Financial predictions carry real money risk |
| 4 model sizes for different hardware | Training data scope unclear |
| MIT license | No guarantee of out-of-sample performance |
📜 License: CC-BY-NC-ND 4.0 · 👤 By: University of Colorado Boulder
🎯 Time to value: 60 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| MIT Press quality, completely free | Academic pace, not a quick tutorial |
| Covers full robotics stack | Non-commercial license limits use |
| Active maintenance (trending now) | Requires math background |
👤 By: Google DeepMind · 🎯 Task: image-text-to-text
📐 Size: 25.2B total / 3.8B active
| ✓ Pros | ✗ Cons |
|---|---|
| 1,100+ tok/s on H100 | Diffusion-based generation is a new paradigm with less tooling |
| Apache 2.0 license | 25.2B total params still needs serious hardware |
| Multimodal (text + image + video) | Early-stage ecosystem for diffusion LLMs |

👤 By: MiniMax · 🎯 Task: image-text-to-text
📐 Size: 428B total / 23B active
| ✓ Pros | ✗ Cons |
|---|---|
| 1M-token context that actually works fast | Community license, not fully open |
| 9x prefill speedup at long context | 428B total params needs multi-GPU setup |
| Strong coding and agentic benchmarks | Less ecosystem support than Llama/Mistral |

👤 By: Moonshot AI · 🎯 Task: image-text-to-text
📐 Size: 1T total / 32B active
| ✓ Pros | ✗ Cons |
|---|---|
| 81.1% MCPMark tool-use score | No independent SWE-bench results yet |
| Modified MIT license | 1T params needs substantial hardware |
| 30% fewer thinking tokens than K2.6 | Self-reported benchmarks only |

👤 By: DeepSeek · 🎯 Task: text-generation
📐 Size: 1.6T total / 49B active
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license - no restrictions | 1.6T total params needs multi-node setup |
| Three reasoning tiers for cost control | Chinese-origin may face enterprise scrutiny |
| 2.93M downloads in 30 days | Self-hosted infrastructure costs are real |

👤 By: NVIDIA · 🎯 Task: image-text-to-text
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| Only 3B params - runs on consumer hardware | Research/non-commercial license only |
| Covers robotics, driving, GUI, documents | Not designed for creative image tasks |
| 2.5x throughput improvement | Requires fine-tuning for niche domains |

👤 By: Cohere Labs · 🎯 Task: text-generation
📐 Size: 30B total / 3B active
| ✓ Pros | ✗ Cons |
|---|---|
| 3B active params means fast, cheap inference | 30B total still needs decent GPU |
| 67.6% SWE-Bench Verified | Smaller than frontier models on open-ended tasks |
| Apache 2.0, 64K output length | Code-focused, not general-purpose |

👤 By: Ideogram · 🎯 Task: text-to-image
📐 Size: 9.3B
| ✓ Pros | ✗ Cons |
|---|---|
| Best text rendering in images | Non-commercial license |
| Structured JSON for precise layout | 9.3B params needs good GPU |
| Top-ranked on Design Arena | FP8 quantization trades some quality |

💰 Pricing: Freemium · 🏷 Category: Productivity

💰 Pricing: Free · 🏷 Category: Developer Tools
💰 Pricing: Freemium · 🏷 Category: Open Source

💰 Pricing: Free · 🏷 Category: Career

💰 Pricing: Freemium · 🏷 Category: Video

| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1000K |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1000K |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | 1050K |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 1000K |
| OpenAI | o4-mini | $1.10 | $4.40 | 200K |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1000K | |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | 2000K | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1000K | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128K |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | 128K |
Key finding: Capability and safety improved together - more capable models also performed safer actions, contradicting the common narrative that the two trade off against each other.
Why practitioners should care: If you are building or evaluating workplace agents (email, calendar, documents), this benchmark provides the most rigorous longitudinal evidence that the technology is approaching deployment-ready reliability - and that safety does not have to come at the expense of capability.