Watch today's digest as a video summary (generated by NotebookLM)
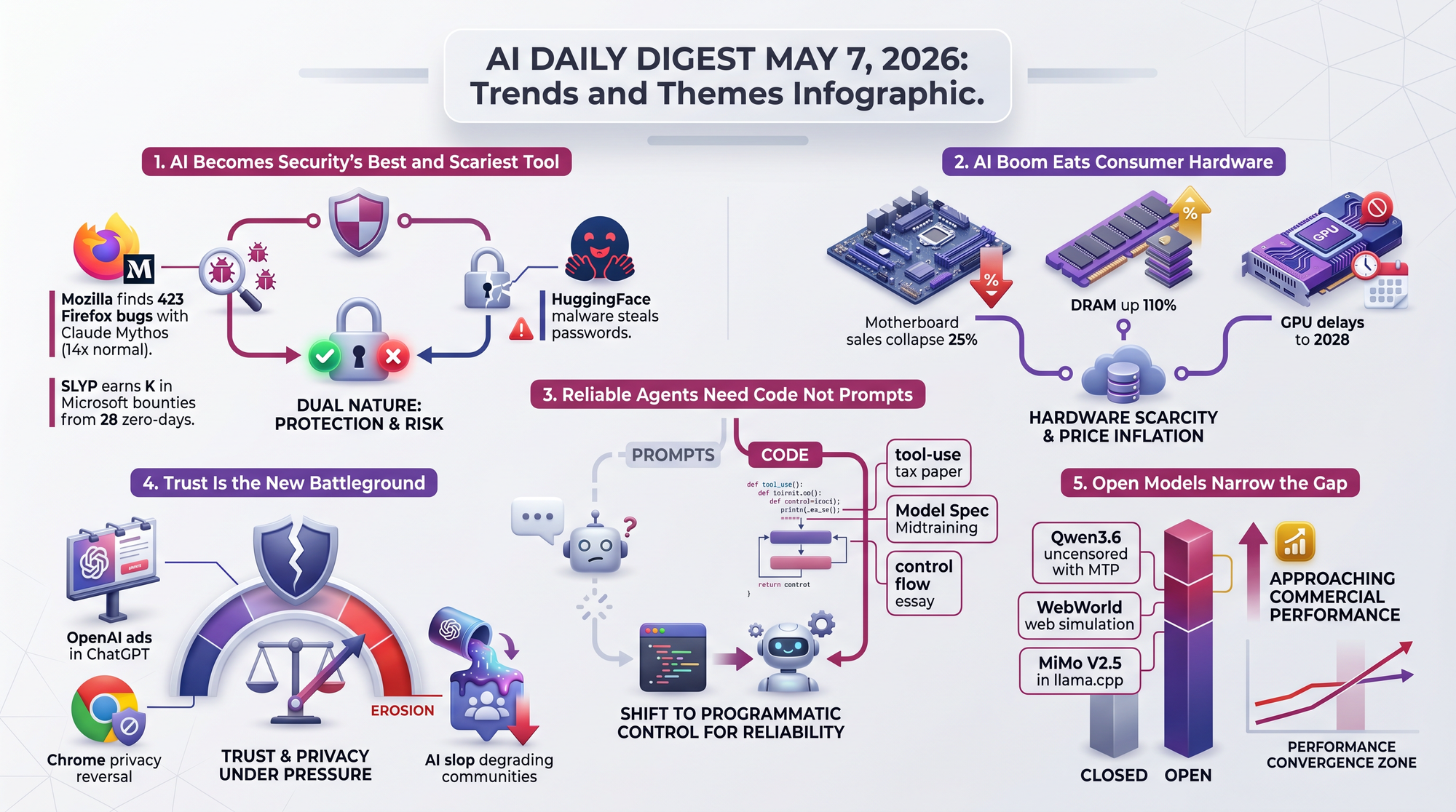
DeepSeek, the Chinese AI lab originally funded by quantitative hedge fund High-Flyer, is raising more than $7 billion while simultaneously launching revenue initiatives. The company plans to release its V4.1 model update next month.
> "$7.35 billion" - from a lab that spent an estimated $6 million training its breakout model
- $7.35 billion would rank among the largest AI funding rounds ever, putting DeepSeek alongside Anthropic and OpenAI in fundraising scale
- The shift from research lab to venture-backed company signals DeepSeek sees a path to monetization beyond releasing free models
- V4.1 arriving next month suggests continued rapid iteration on their architecture
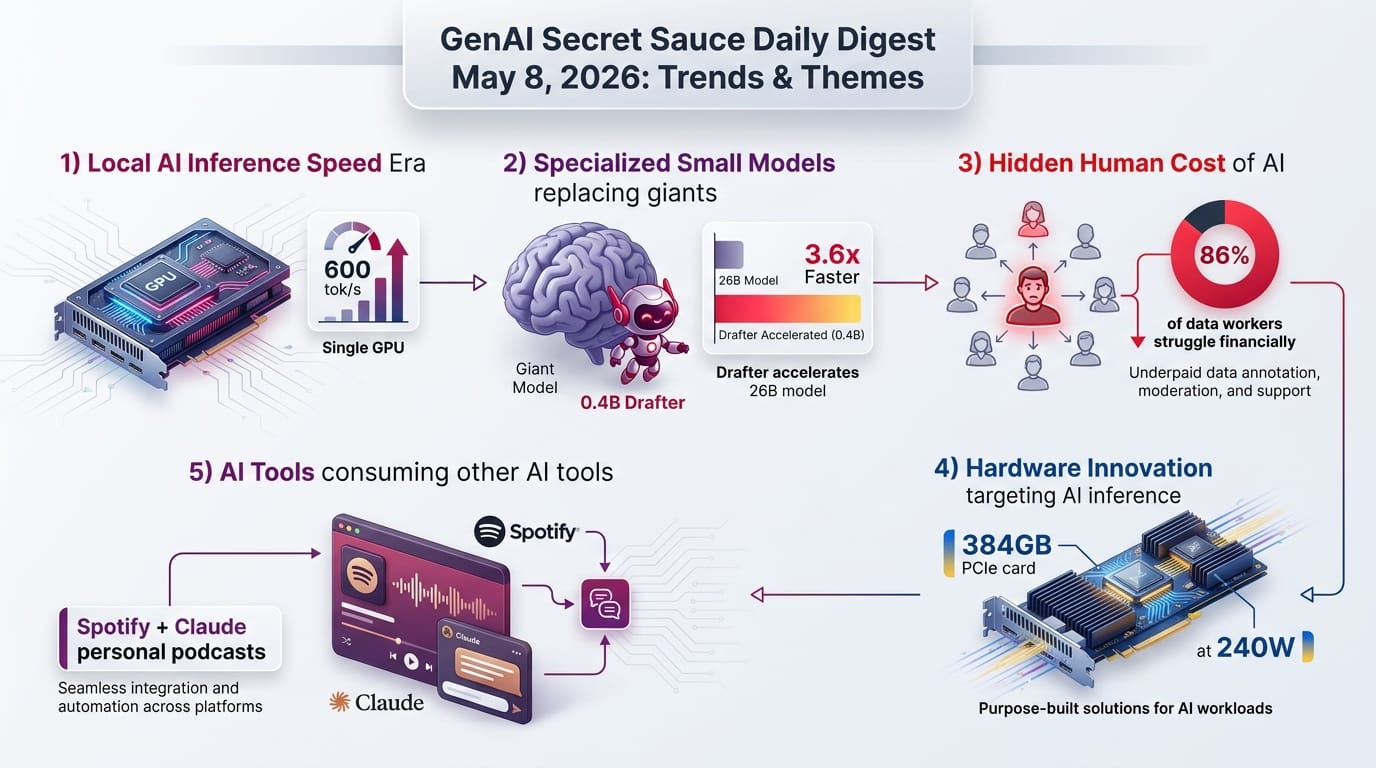
Taiwanese company Skymizer announced the HTX301, their first chip built on the HyperThought platform. Six chips deliver 384 gigabytes (GB) of memory on a single Peripheral Component Interconnect Express (PCIe) card at approximately 240 watts.
- Supports models from 4 billion to 700 billion parameters using decode-first silicon with LISA (Language Instruction Set Architecture) software orchestration
- Disaggregates prefill and decode workloads for higher utilization and lower latency - a design choice that mirrors how hyperscalers run inference but on a single card
- 240 watts for 384GB is remarkably power-efficient compared to GPU-based inference setups that consume thousands of watts for similar memory capacity
- On-premises deployment addresses the growing demand from companies that want AI capabilities without sending data to cloud providers
Spotify Chief Technology Officer (CTO) Gustav Soderstrom announced that AI agents can now generate personalized audio content and save it directly to users' Spotify libraries. The content remains private and plays across all Spotify platforms.
- Works with Claude Code, OpenClaw, and Codex via a command-line interface (CLI) tool on GitHub
- Use cases include morning briefings combining your calendar and inbox, academic deep dives before exams, and travel itineraries
- Content plays everywhere Spotify does - phone, car, smart speaker - making AI-generated audio a first-class citizen alongside music and traditional podcasts
- Represents one of the first major consumer platforms treating AI-generated content as equivalent to human-created content in its library system
Simon Willison, one of the most-read voices in AI development, wrote about Thariq Shihipar's (Anthropic, Claude Code team) argument that Hypertext Markup Language (HTML) output from AI models is dramatically more useful than Markdown. Willison had favored Markdown since GPT-4 when token limits made its efficiency valuable, but HTML unlocks capabilities Markdown cannot express.
- Scalable Vector Graphics (SVG) diagrams, interactive widgets, and in-page navigation all become possible when you ask for HTML
- Willison tested the approach by having a model explain a Linux privilege-escalation exploit, getting an interactive walkthrough rather than a flat document
- The insight is counterintuitive - Markdown feels simpler, but HTML's richer capabilities mean the AI does more useful work per prompt
Jeff Kaufman argues that AI is destabilizing both major vulnerability disclosure models. Coordinated disclosure gives maintainers 90 days to patch before public announcement. The Linux kernel community takes the opposite approach: deploying fixes quietly in high-volume commits to obscure which ones are security-critical.
- AI undermines the quiet-fix approach by making it practical to scan every commit for security-relevant changes, extracting signal from noise
- Coordinated disclosure faces pressure too as AI tools accelerate the window between patch release and exploit development
- Neither model was designed for a world where automated analysis can review thousands of commits in minutes
- 174 points on Hacker News signals this resonated deeply with the security community

- 262,000 token context window with $0 per million tokens for both input and output
- Built by InclusionAI for agent workflows including coding, tool use, and extended reasoning
- Available immediately on OpenRouter for testing and integration
- Exploits Multi-Head Latent Attention (MLA) architecture to separate position-dependent from position-independent key-value components
- Content-addressed caching replaces prefix matching, so identical content at different positions still hits the cache
- Time To First Token drops from 10-16 seconds to near-instant on unchanged content
- 63% energy savings in agentic workloads where the same context appears repeatedly
- Shifts reasoning and retrieval from text to continuous latent space - one forward pass of hidden states instead of generating intermediate text
- Parallel latent decoding maintains transparency while skipping token-by-token generation
- End-to-end joint optimization aligns the language model with the retrieval model
- 1 billion active / 14 billion total parameters with 8 of 128 experts active
- Document-level pooling routes all tokens in a document through the same expert subset
- At 25% of experts (32), performance drops only ~1% absolute
- Clusters correspond to semantic domains (health, news, science) enabling domain-specific pruning
- 155 tokens/second with eGPU versus 22 native on Qwen 3.6 inference
- Prompt processing for 4,000 tokens: 150 milliseconds versus 17 seconds
- Gaming results were less impressive - 27 frames per second in Cyberpunk 2077 at 4K versus 100+ natively
- Proves the concept that Apple Silicon machines can access NVIDIA's CUDA ecosystem when needed
DomLoRA discovers that gradient energy concentrates on a single shallow layer in most model architectures. Placing one adapter there achieves full fine-tuning quality at 0.7% of the usual parameter count. The dominant layer's position depends on architecture but stays consistent across tasks.
A discussion post on r/MachineLearning (45 upvotes) questioning the value of mechanistic interpretability research drew significant attention, linking to Anthropic's Transformer Circuits research. The debate centers on whether understanding individual neurons and circuits actually leads to safer or more controllable AI systems.
Conditional Field Subtraction solves a specific problem in conversational AI: when you ask for relevant memories, cosine similarity returns multiple rewordings of the same fact, wasting context slots. CFS scores candidates by both relevance and coverage gaps, ensuring each retrieved memory adds new information.
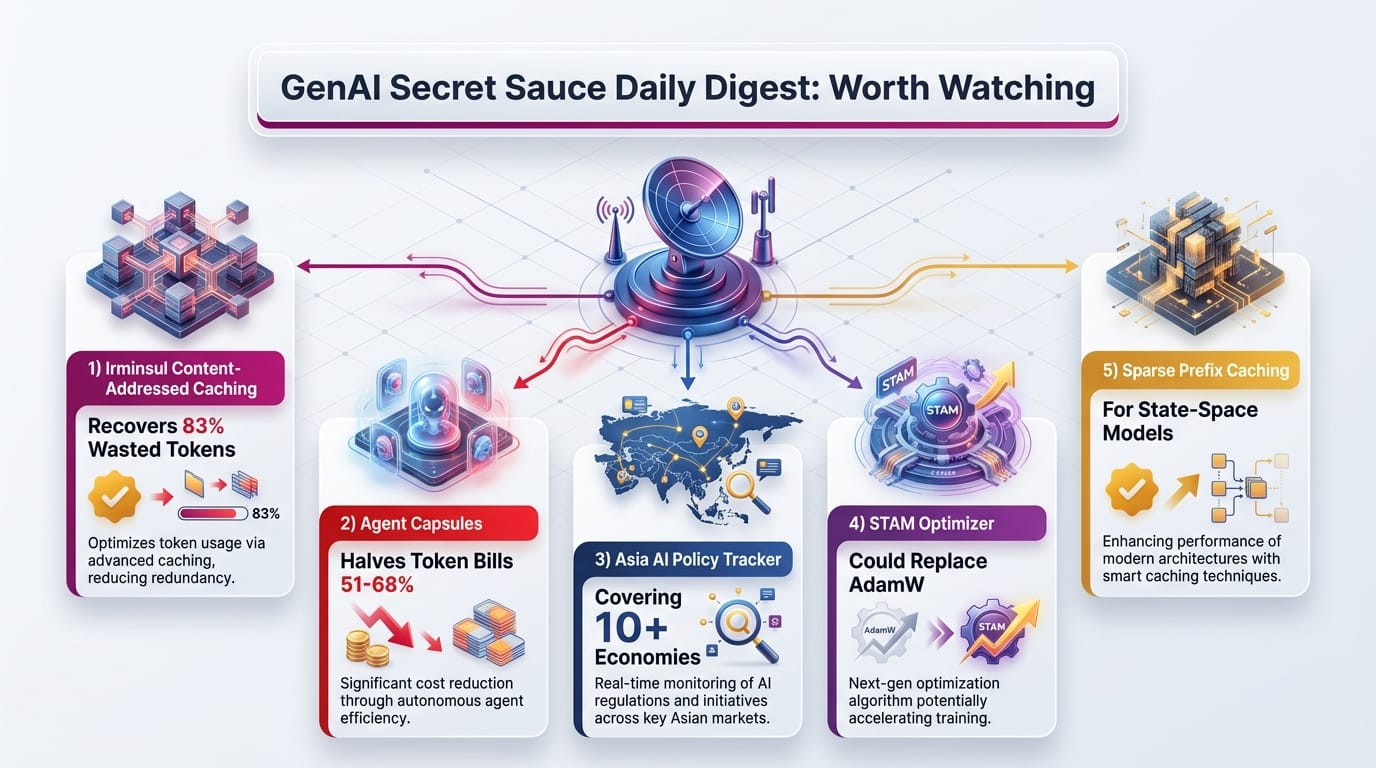
Content-addressed caching for Multi-Head Latent Attention means identical documents at different positions in a conversation still hit the cache. Current prefix-based systems void the entire cache when a single token shifts position. If widely adopted, this could cut the cost of running AI agents in production by more than half. For users, it means faster responses when an agent re-reads files it has seen before.
Most multi-agent systems issue one Language Model (LLM) call per agent, wasting tokens on redundant context. Agent Capsules monitors rolling quality scores and merges calls when quality won't suffer. On a 14-agent pipeline, it matched LangGraph quality at half the token cost. No per-pipeline tuning or training data required.
Vietnam has the most comprehensive standalone AI strategy. South Korea finalized a 99-task action plan. Japan's AI Promotion Act has no enforcement mechanism. India treats AI regulation as sector-by-sector rather than comprehensive. These policy differences will determine where AI companies can operate and what products they can build across the world's fastest-growing tech markets.
AdamW's fixed momentum coefficient causes overshooting when gradients are noisy and misses faster convergence when they stabilize. STAM adapts beta1 in real time using a gradient variance proxy. If validated at scale, this could reduce training costs and improve model quality without changing architectures.
State-space models and hybrid architectures can't use standard key-value caching because they don't have persistent key-value pairs. This paper stores exact recurrent states at sparse positions and recomputes the gaps, with an optimal placement algorithm that outperforms fixed-budget heuristics.
📜 License: Apache-2.0 · 👤 By: Anthropic (company)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Production-ready with real data connectors | Locked to Anthropic's ecosystem |
| 11 specialized agents cover most finance workflows | Bloomberg/FactSet connectors require existing licenses |
| Apache-2.0 means full customization rights | Enterprise setup requires Managed Agents API access |
📜 License: MIT · 👤 By: Addy Osmani (individual, Google Chrome team)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Battle-tested patterns from Google-scale engineering | Opinionated workflow may conflict with existing team practices |
| Works with multiple agent platforms (Claude Code, Cursor, Codex) | 20 skills is a lot to learn and configure |
| MIT license, fully customizable | Skills assume senior-level development context |
📜 License: MIT · 👤 By: Hmbown (individual)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Rust performance with native terminal UI | DeepSeek-specific - doesn't support other model families |
| 1M context window matches DeepSeek V4's full capability | Newer and less battle-tested than Claude Code or Codex CLI |
| YOLO mode for rapid prototyping without confirmations | Requires DeepSeek API access or local deployment |
📜 License: MIT · 👤 By: Z-Lab (research lab)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 3.6x speedup demonstrated on Gemma 4 26B | Requires compatible draft model for each model family |
| Works with major serving frameworks (vLLM, SGLang) | Research-stage project with rapid iteration |
| MLX support enables Apple Silicon deployment | Quality validation still emerging from community |
📜 License: MIT · 👤 By: HKU Data Science Lab (university research)
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Paper trading removes financial risk while testing | Research project, not production trading infrastructure |
| Multi-market support (stocks, crypto, forex, options) | Agent trading strategies are unproven at scale |
| Claude Code and MCP integration | CC-BY-NC-SA license restricts commercial use |
📜 License: MIT · 👤 By: LearningCircuit (individual)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Fully local option with zero data leakage | Local models produce lower-quality research than cloud |
| 10+ search engine integrations including academic sources | Setup requires installing local model infrastructure |
| MCP server available for Claude integration | Research depth depends heavily on model quality |
📜 License: Apache-2.0 · 👤 By: LobeHub (company)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 76K stars and mature ecosystem | Complex setup for full feature utilization |
| Self-hosted with no vendor lock-in | Plugin quality varies across the marketplace |
| Multi-agent collaboration built-in | TypeScript codebase may be unfamiliar to Python-focused teams |
📜 License: CC-BY-NC-SA-4.0 · 👤 By: Datawhale (community, China)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 44K stars signal strong community validation | Primarily Chinese-language content |
| 16 chapters from basics to advanced multi-agent | CC-BY-NC-SA restricts commercial derivative use |
| Hands-on code examples throughout | Focuses on Chinese AI ecosystem tools |
👤 By: SulphurAI · 🎯 Task: text-to-video
📐 Size: 9B
| ✓ Pros | ✗ Cons |
|---|---|
| No content restrictions on generation | License terms unclear |
| Multiple deployment options including Ollama | 9B parameters requires significant VRAM |
| Built-in prompt enhancement | Quality gap vs commercial video gen (Sora, Veo) |

👤 By: DeepSeek · 🎯 Task: text-generation
📐 Size: 1.6T total / 49B active
| ✓ Pros | ✗ Cons |
|---|---|
| Frontier performance with MIT license | 1.6T total parameters requires serious hardware |
| 1M token context window | 49B active parameters still substantial per query |
| Three reasoning modes for cost/quality tradeoff | Quantization community still optimizing deployment |

👤 By: Zyphra · 🎯 Task: text-generation
📐 Size: 8.4B total / 760M active
| ✓ Pros | ✗ Cons |
|---|---|
| Only 760M active params enables mobile deployment | Narrow specialization in math/code reasoning |
| Apache-2.0 license allows commercial use | 8.4B total still needs careful quantization for phones |
| Trained on AMD MI300X, proving non-NVIDIA viability | Limited general knowledge compared to larger models |

👤 By: OpenAI · 🎯 Task: PII detection
📐 Size: 1.5B total / 50M active
| ✓ Pros | ✗ Cons |
|---|---|
| Browser-deployable at 50M active parameters | Limited to 8 PII categories |
| 128K context handles long documents | OpenAI rarely open-sources - long-term support uncertain |
| Apache-2.0 license | PII detection accuracy not publicly benchmarked |

👤 By: Xiaomi · 🎯 Task: agentic/code
📐 Size: 1T total / 42B active
| ✓ Pros | ✗ Cons |
|---|---|
| 78.9% SWE-Bench competitive with frontier closed models | 1T parameters requires enterprise hardware |
| MIT license enables commercial deployment | Xiaomi's model ecosystem less established than competitors |
| Multi-token prediction provides real speedup | Community tooling still catching up |

👤 By: Mistral AI · 🎯 Task: multimodal text-generation
📐 Size: 128B
| ✓ Pros | ✗ Cons |
|---|---|
| Replaces three models with one | 128B dense requires significant serving infrastructure |
| 256K context with vision support | Modified MIT license has usage restrictions |
| 24+ languages including non-Latin scripts | Dense architecture less efficient than MoE alternatives |

👤 By: SenseTime · 🎯 Task: any-to-any
📐 Size: 8B
| ✓ Pros | ✗ Cons |
|---|---|
| True unified multimodal - no adapter overhead | 2.9K downloads indicates early adoption stage |
| 8B parameter footprint is manageable | Image quality gap vs specialized generators (DALL-E, Midjourney) |
| Apache-2.0 license | Documentation primarily in Chinese |

👤 By: NVIDIA · 🎯 Task: any-to-any
📐 Size: 31B total / 3B active
| ✓ Pros | ✗ Cons |
|---|---|
| Only 3B active parameters keeps inference cheap | NVIDIA-specific license terms |
| Video + audio + image + text in one model | Hybrid Mamba2 architecture is newer and less tooling support |
| 76% improvement on computer-use benchmarks | 31B total parameters still significant for deployment |

💰 Pricing: Freemium · 🏷 Category: AI Workflow Automation

💰 Pricing: Freemium · 🏷 Category: Developer Tools

💰 Pricing: Free/Open Source · 🏷 Category: AI Workflow Automation
💰 Pricing: Paid · 🏷 Category: Developer Tools

💰 Pricing: Freemium · 🏷 Category: AI Coding
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.7 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 1M |
| OpenAI | o3 | $2.00 | $8.00 | 200K |
| OpenAI | o4-mini | $1.10 | $4.40 | 200K |
| OpenAI | GPT-4.1 Mini | $0.40 | $1.60 | 1M |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | 200K | |
| Gemini 2.5 Pro | $1.25 | $10.00 | 200K | |
| Gemini 2.5 Flash | $0.30 | $2.50 | N/A | |
| Groq | GPT OSS 120B | $0.15 | $0.60 | 128K |
| Groq | Llama 4 Scout | $0.11 | $0.34 | 128K |
| Groq | Qwen3 32B | $0.29 | $0.59 | 131K |
Key finding: On a 14-agent competitive intelligence pipeline, Agent Capsules used 51% fewer input tokens than a hand-tuned LangGraph implementation at equivalent quality. On a 5-agent due diligence pipeline, it used 68% fewer tokens than DSPy MIPROv2 at +0.052 higher quality.
Why practitioners should care: If you run multi-agent systems in production using LangGraph, DSPy, or custom frameworks, this offers a drop-in runtime that halves your token bill without per-pipeline tuning or training data. It validates against real frameworks and real workloads, not toy benchmarks.