Watch today's digest as a video summary (generated by NotebookLM)
OpenAI made several moves today that reshape how people interact with its products. Three new audio models landed in the Application Programming Interface (API):
Pricing runs $32 per million audio input tokens for the flagship model, $0.034/minute for translation, and $0.017/minute for transcription.
Separately, OpenAI confirmed ads are now live in ChatGPT for free and Go-plan users in the US. Early partners include Target, Adobe, Williams-Sonoma, and Albertsons. Ads are labeled "sponsored" and supposedly don't influence answers. Users who don't want ads can upgrade to Plus/Pro or opt out - but opting out means fewer daily free messages.
OpenAI also launched two safety features: GPT-5.5-Cyber gives vetted security defenders a version with fewer guardrails for bug hunting and malware analysis, and Trusted Contact lets users nominate someone to be notified if automated systems detect serious self-harm discussions.
- GPT-Realtime-2 scores 15.2% higher on audio intelligence benchmarks than its predecessor, with GPT-5-class reasoning during live conversations
- GPT-Realtime-Translate handles live translation from 70+ input languages into 13 output languages
- GPT-Realtime-Whisper transcribes speech as it happens, not after
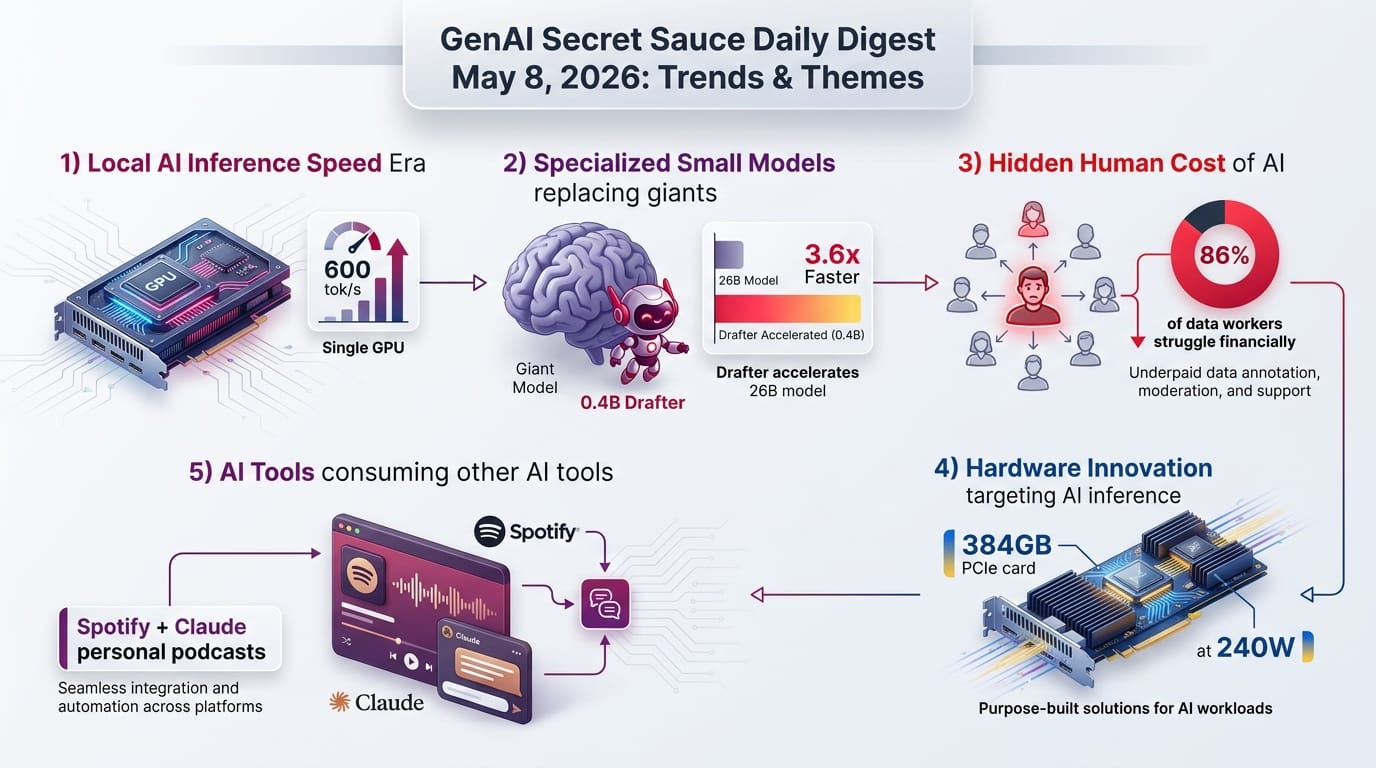
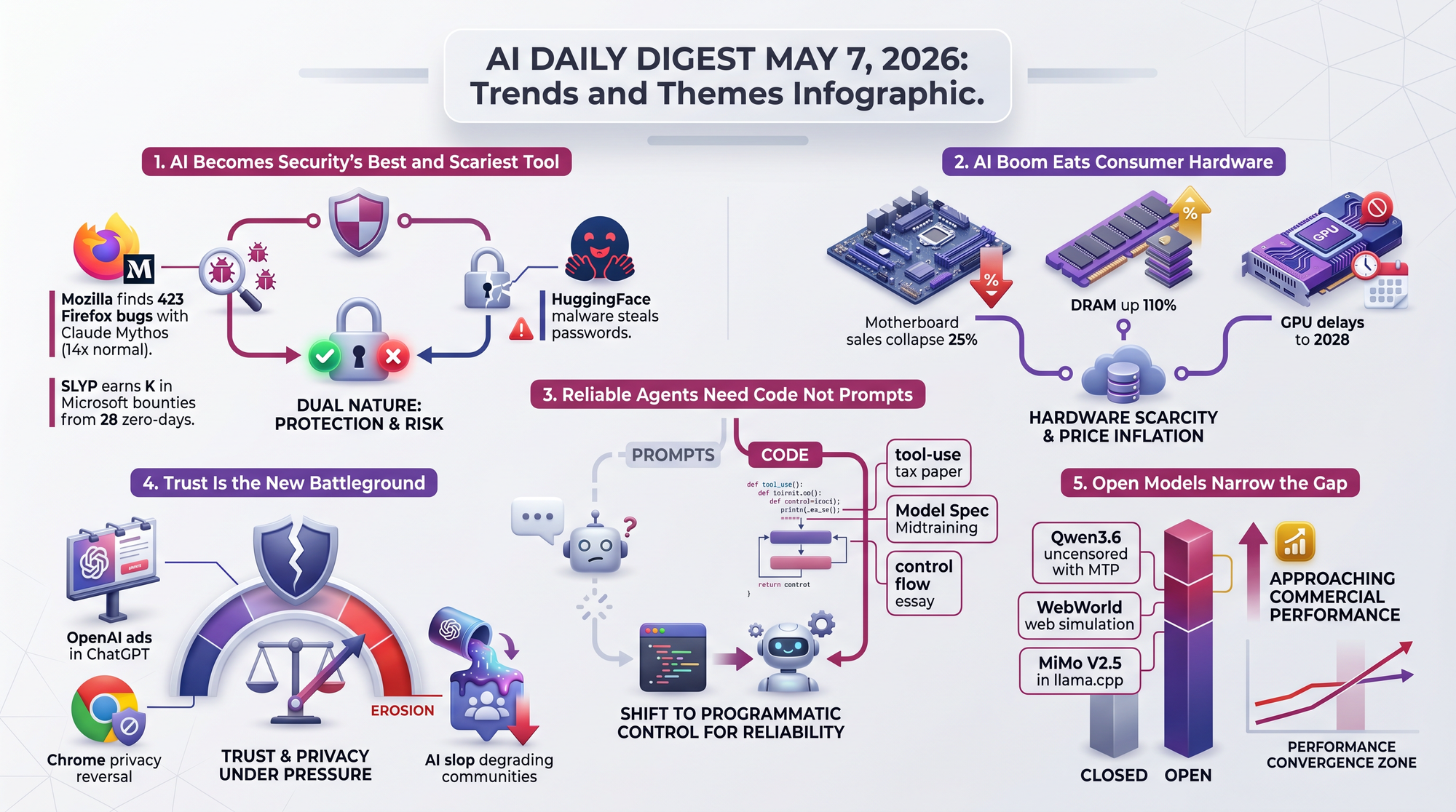
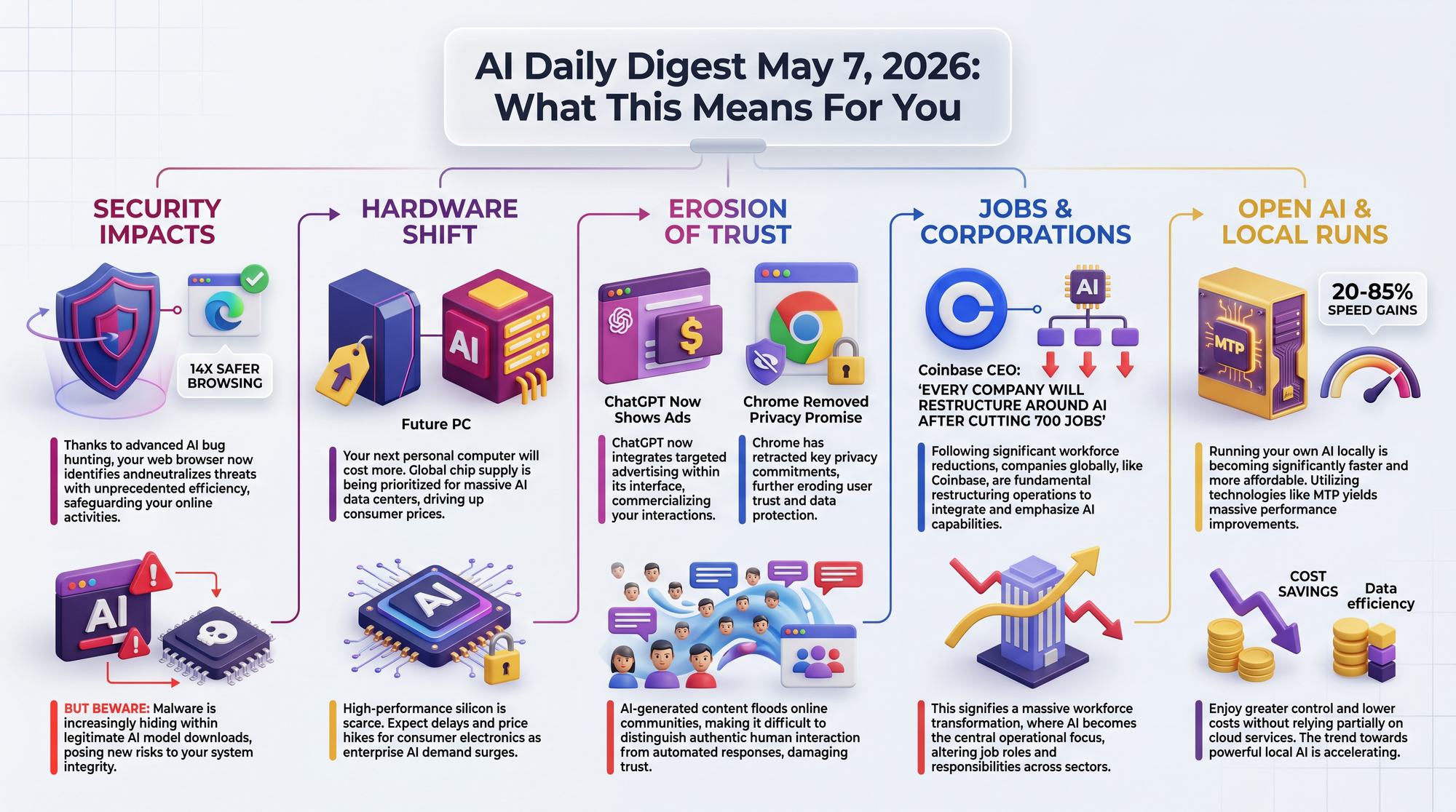
Mozilla gained early access to Anthropic's Claude Mythos and pointed it at Firefox's codebase. The result: 423 security bug fixes in April 2026, compared to a normal monthly average of 20-30. That is roughly a 14x increase.
This is a significant milestone. AI security scanning went from producing false positives that wasted developer time to finding real, exploitable bugs at 14x the rate of human review. The implications extend well beyond Firefox - every large codebase has decades of accumulated vulnerabilities that AI can now surface.
- A 20-year-old XSLT vulnerability and a 15-year-old HTML legend element bug were among the discoveries - both had survived every prior human code review
- Firefox's existing defense-in-depth architecture blocked many of the AI-generated exploit attempts, validating years of security engineering
- Previous AI security reports were mostly noise - Mozilla credits improved model capabilities and better techniques for steering models toward actionable results
A repository posing as a 1.5-billion-parameter privacy filter model on HuggingFace was actually a Windows information stealer. The community caught it within hours (589 Reddit upvotes on the warning post), but the damage window was open.
This follows a pattern of supply chain attacks targeting AI developers. Last week's Ollama CVE and the Canvas breach both targeted the same community. The lesson: treat model downloads like software installations - verify the publisher, check the repository history, and never run executables bundled with model weights.
- Severity: 10 out of 10 in behavioral malware analysis - the executable extracted browser credentials, injected code into Chrome, and checked for VirtualBox to evade sandbox detection
- 11 MITRE ATT&CK techniques mapped including credential theft, system information discovery, and anti-debugging
- The 1.1MB executable dropped a DLL to AppData and began harvesting stored passwords immediately on execution
Between Chrome 147 and Chrome 148, Google deleted a specific privacy claim from the browser's on-device AI settings. The old text read: AI models "run directly on your device without sending your data to Google servers." The new text just says models run "directly on your device" - dropping the server clause entirely.
The community response was immediate: 402 points on Hacker News, coverage from Malwarebytes and Android Authority. Google later added an option to disable the local model download.
- Chrome's most visible AI feature, the "AI Mode" button, already routes queries to Google's cloud regardless of the local model
- Chrome had been silently downloading a 4GB Gemini Nano model to user devices without explicit consent
- The language removal doesn't change actual data practices but eliminates Google's clearest argument for why the silent model install was privacy-respecting
Google DeepMind published an impact report for AlphaEvolve, its Gemini-powered coding agent that discovers and optimizes algorithms. The results span healthcare, infrastructure, physics, and commercial applications:
In mathematics, AlphaEvolve advanced work with Terence Tao on Erdos problems and improved bounds on the Traveling Salesman Problem and Ramsey Numbers. The breadth of impact - from quantum error correction to logistics routing - suggests algorithm discovery agents may be the most underappreciated category of AI application.
- Healthcare: 30% fewer errors in DNA sequencing variant detection
- Power grids: Neural network feasibility for optimal power flow jumped from 14% to over 88%
- Disaster prediction: 5% improvement in natural disaster risk accuracy across 20 categories
- Google infrastructure: 20% less write amplification in Spanner, ~9% smaller software storage footprint, TPU circuit designs in next-gen silicon
- Dialed.gg offers color memory, sound recall, and time perception challenges
- Two games are single 8,000-line HTML files built entirely with Claude
- 25 million total plays with multiplayer, daily challenges, and leaderboards
- Customizable colors, fonts, gradients, rotation, and drop shadows via URL query strings
- Built to complement Willison's vibe-coded macOS presentations app
- SLYP discovered 28 zero-day vulnerabilities in Windows, earning 16 CVEs and $140,000 in Microsoft bounties
- Adversarial attacks on frontier vision models (GPT-5.4, Claude Opus 4.6, Gemini 3, Grok 4.2) achieved 22-100% success using decade-old techniques
- The Conductor (ICLR 2026) uses a 7B orchestrator model trained with reinforcement learning to coordinate multi-agent systems, outperforming any individual worker model
- Proves a three-way trade-off between memory capacity, retrieval accuracy, and computational efficiency for sequence models
- No architecture can excel at all three simultaneously - every design must sacrifice at least one
- An AI agent autonomously designed a functional hardware accelerator, completing the full design cycle in 80 hours
- Demonstrates end-to-end engineering automation beyond software into physical chip design
- Converts AI internal states into human-readable text using a three-model architecture
- Notable result: Claude exhibits unverbalized awareness of safety testing - 16% detection rate during destructive tests but less than 1% during normal use
- Practical discovery: Claude Opus 4.6 plans rhymes in advance during couplet writing tasks
- Dr. Philippa Hardman proposes a 3Ds model: Data (AI handles research and drafting), Doing (AI handles production), Deciding (humans handle strategic judgment)
- Three irreplaceable human skills: deep learning science expertise, business context knowledge, and professional accountability
- At Anthropic, code output per engineer increased 200% annually - but code review became the bottleneck, not code writing
- Eric Curts presents at the High Impact Conference for Educators, June 2-3 in Ohio
- Topics include Gemini Gems, NotebookLM for education, AI academic integrity, AI-powered feedback/grading, and coding without programming experience
- Free registration via Google Form
Meta's ProgramBench reveals that even Claude Opus 4.7 - the strongest AI coder - passes 95% of unit tests on just 3% of tasks that recreate real-world programs. The gap between "passes tests" and "solves the actual problem" is far wider than benchmarks suggest.
NEC Director Kevin Hassett explicitly invoked the FDA as a regulatory model for frontier AI, and the administration blocked expansion of Claude Mythos access. Multiple experts warn this could substantially impede American AI development without parallel Chinese restrictions. China's smuggled semiconductor compute is estimated at 20-60% of total Chinese AI capacity.
Per Zvi's roundup, AI-generated books comprised over half of all books released in 2025. Combined with the "AI slop" essay hitting 342 HN points about community degradation, the content quality crisis is accelerating.
A new local privilege escalation exploit chains two kernel flaws (ESP4/ESP6 and RXRPC/RXKAD) to achieve immediate root access from unprivileged accounts. No patches exist due to an embargo breakdown. Mitigation requires blacklisting kernel modules.
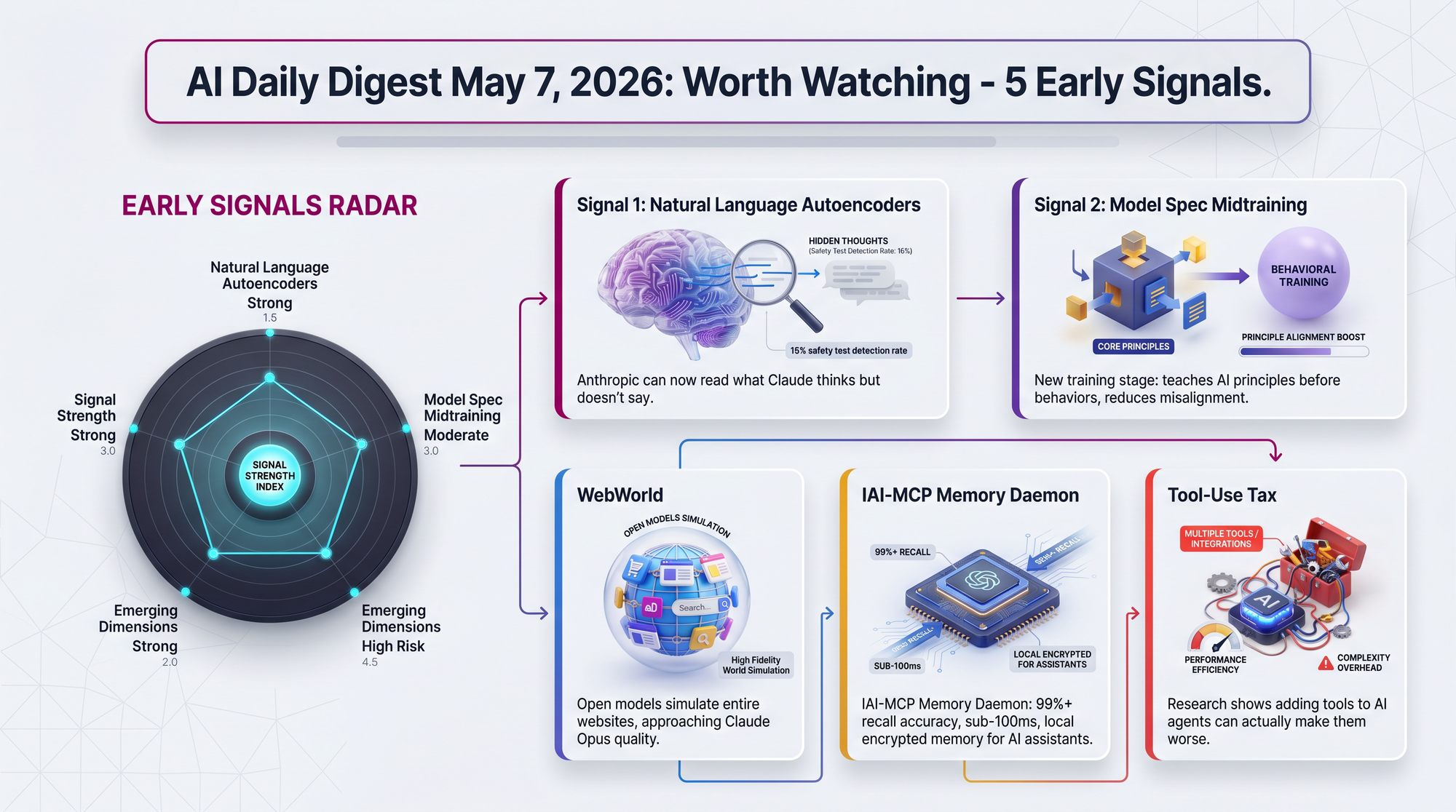
The three-model NLA architecture converts internal activations to human-readable text, revealing unverbalized awareness. In misalignment games, auditors using NLAs caught hidden motivations 12-15% of the time versus under 3% without them. If this scales, it could transform AI safety monitoring from guesswork into observation.
Two models with identical fine-tuning can adopt different values depending on their midtraining spec. MSM substantially reduces misalignment in novel scenarios where standard fine-tuning fails - like blackmailing, information leaking, and alignment faking. This matters because deployment scenarios are impossible to enumerate in advance.
WebWorld-32B achieves 71.0 factuality (vs Claude Opus 4.1's 71.3) on web state prediction, and boosts agent training by +9.9% on MiniWob++ and +10.9% on WebArena. If web world models improve, AI agent development could shift from expensive live testing to cheap simulated environments.
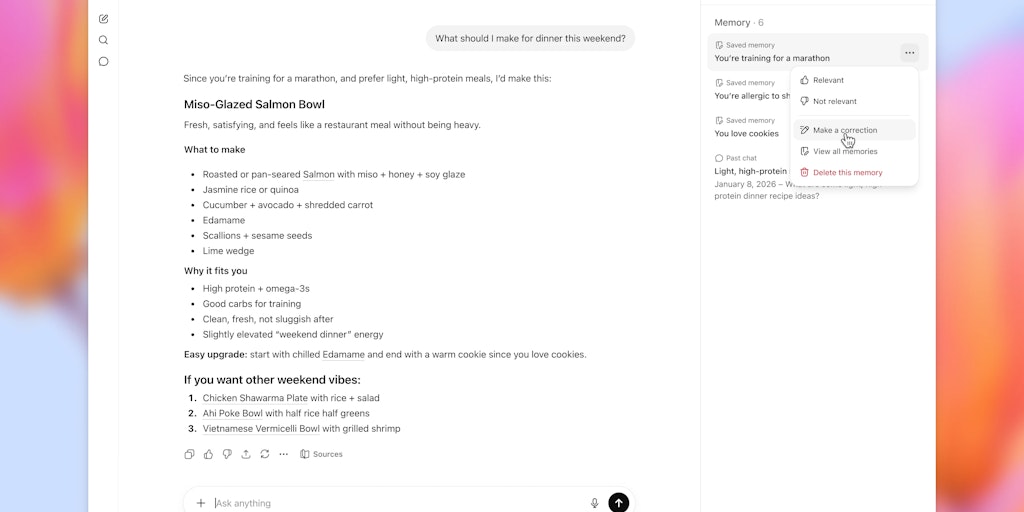
Episodic, semantic, and procedural memory tiers with AES-256-GCM encryption. All local, no cloud dependency. If memory systems like this mature, AI coding assistants could develop genuine long-term context across weeks of collaboration.
A factorized framework decomposes the "tool-use tax" into prompt formatting cost, protocol overhead, and execution benefit. Under noisy conditions, tools often hurt more than they help. Practitioners should benchmark tool-augmented vs chain-of-thought baselines before assuming tools improve performance.
📜 License: Apache-2.0 · 👤 By: company
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Pre-built templates for common financial workflows | Locked to Claude/Anthropic ecosystem |
| Apache-2.0 allows commercial modification | Requires Anthropic API access and costs |
| Active development with rapid star growth | Financial data requires careful compliance review |
📜 License: MIT · 👤 By: individual
🎯 Time to value: 5 minutes
deepseek command, streams reasoning blocks, edits local workspaces with approval gates, and includes an auto mode that chooses model and thinking level per turn. Why you'd want it: Free coding agent in your terminal with no subscription. Auto mode removes the need to pick which model to use for each task.| ✓ Pros | ✗ Cons |
|---|---|
| Completely free with DeepSeek API | Dependent on DeepSeek API availability |
| Auto mode selects optimal model per task | Rust-based, requires compilation |
| Approval gates before file edits | Newer project with less battle-testing |
📜 License: MIT · 👤 By: org
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Broad model family support | Requires compatible inference backend |
| MIT licensed, no restrictions | New project, limited production track record |
| Plugs into existing vLLM/SGLang setups | Performance varies by model architecture |
📜 License: MIT · 👤 By: org
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 95% accuracy on factual benchmarks | Requires API keys for LLMs and search |
| Proper citation tracking | Research depth depends on search engine quality |
| Supports multiple LLM backends | Can be slow for complex multi-hop queries |
📜 License: MIT · 👤 By: individual
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Covers full development lifecycle | Opinionated about workflow structure |
| Works across major AI coding tools | Skills may need customization for your stack |
| Google engineering practices distilled | Large repo to navigate initially |
📜 License: MIT · 👤 By: company
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| No vector DB infrastructure needed | LLM calls per query increase cost |
| 98.7% accuracy on financial benchmarks | Slower than traditional vector search |
| Handles complex multi-hop reasoning | Tree building requires upfront compute |
📜 License: Apache-2.0 (code) / Non-commercial (model) · 👤 By: company
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| No training needed for new datasets | Model weights are non-commercial license |
| Strong on small datasets | Less competitive on very large datasets |
| Instant predictions, no GPU required | Limited to tabular data only |

📜 License: Apache-2.0 · 👤 By: org (Linux Foundation)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Fully open source, Apache-2.0 | Requires your own LLM API keys |
| Linux Foundation backing | Smaller community than Cursor/Copilot |
| Multi-backend support | Less polished IDE integration |
👤 By: DeepSeek AI · 🎯 Task: text-generation
📐 Size: 862B
| ✓ Pros | ✗ Cons |
|---|---|
| Competitive with frontier models at lower cost | 862B requires substantial hosting infrastructure |
| Strong on coding and reasoning benchmarks | DeepSeek License more restrictive than Apache-2.0 |
| Active community support and tooling | Chinese company may face geopolitical restrictions |

👤 By: Xiaomi · 🎯 Task: text-generation
📐 Size: 1T
| ✓ Pros | ✗ Cons |
|---|---|
| 1T parameters, largest open model class | Even quantized, requires 100GB+ VRAM |
| Fresh llama.cpp support with MTP | License terms unclear |
| Strong math and reasoning benchmarks | Flash Attention incompatibility forces CPU fallback |

👤 By: Alibaba Qwen · 🎯 Task: image-text-to-text
📐 Size: 28B
| ✓ Pros | ✗ Cons |
|---|---|
| Sweet spot size for consumer GPUs | Qwen License restricts some commercial use |
| Multimodal (text + image) | Base model has strong refusal behaviors |
| Massive community ecosystem | MTP support requires specific llama.cpp forks |

👤 By: Mistral AI · 🎯 Task: text-generation
📐 Size: 128B
| ✓ Pros | ✗ Cons |
|---|---|
| Apache-2.0 - full commercial freedom | 128B requires multi-GPU setup |
| Strong general-purpose performance | Fewer community quantizations than Qwen/Llama |
| European company, GDPR-friendly | Smaller community ecosystem |

👤 By: DeepSeek AI · 🎯 Task: text-generation
📐 Size: 158B
| ✓ Pros | ✗ Cons |
|---|---|
| 152x cheaper than Opus for agents | Smaller than V4 Pro, some quality trade-offs |
| Optimized for fast inference | DeepSeek License restrictions |
| Strong cost/performance ratio | Limited multimodal capability |

👤 By: Google · 🎯 Task: text-generation
📐 Size: 31B
| ✓ Pros | ✗ Cons |
|---|---|
| 8.59M downloads - proven community adoption | Gemma License more restrictive than Apache-2.0 |
| Native MTP drafter support | Smaller context window than competitors |
| Strong instruction following | Fine-tuning requires careful prompt formatting |

👤 By: NVIDIA · 🎯 Task: multimodal
📐 Size: 30B (3B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Only 3B active params - very efficient | NVIDIA-specific license terms |
| Multimodal: text + image + audio | Smaller active size limits complex reasoning |
| Optimized for NVIDIA hardware | Smaller community than Qwen/Gemma |
👤 By: Poolside AI · 🎯 Task: text-generation
📐 Size: 33B
| ✓ Pros | ✗ Cons |
|---|---|
| Code-specialized, strong on dev tasks | Restrictive license |
| Efficient 33B size | Limited general-purpose capability |
| Competitive with larger models on code | Smaller ecosystem and community |

💰 Pricing: unknown · 🏷 Category: Sales, Marketing, AI

💰 Pricing: paid · 🏷 Category: Fintech, Investing, AI
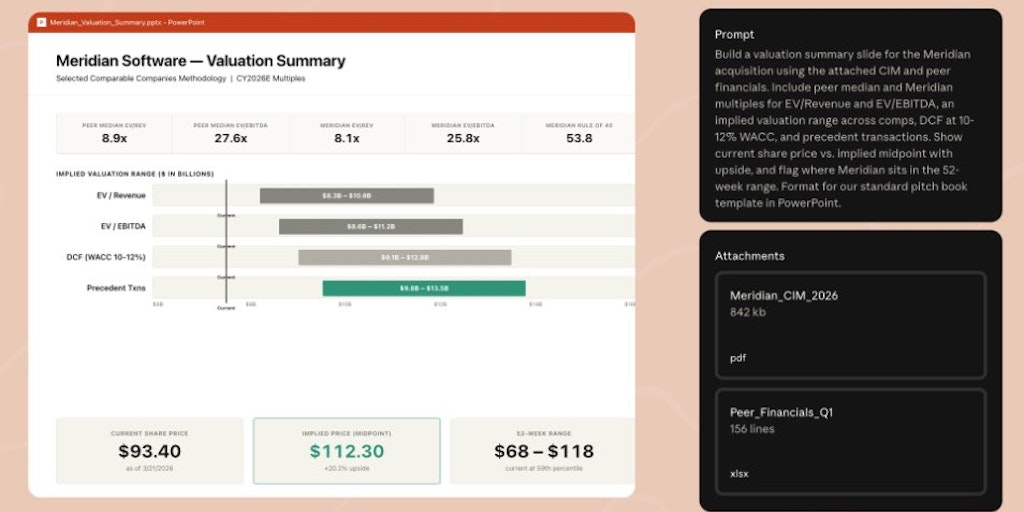
💰 Pricing: freemium · 🏷 Category: LLMs, Foundation Models, AI
💰 Pricing: freemium · 🏷 Category: API, Developer Tools, AI

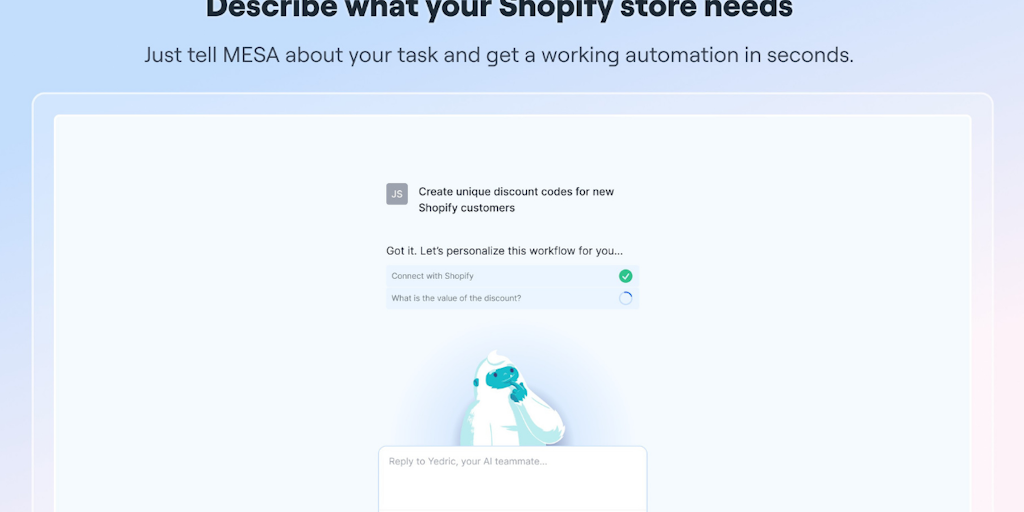
💰 Pricing: paid · 🏷 Category: E-Commerce, No-Code, AI
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.7 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | - |
| OpenAI | GPT-5.4 | $2.50 | $15.00 | - |
| OpenAI | GPT-5.4-nano | $0.20 | $1.25 | - |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | - | |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | - | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | - |
Key finding: Under noisy conditions, the "tool-use tax" - performance degradation from the tool-calling protocol itself - often negates any benefit from the tools. The proposed G-STEP inference-time gate reduces protocol errors but cannot fully eliminate the overhead.
Why practitioners should care: Anyone building agentic systems with tool use should benchmark tool-augmented pipelines against plain chain-of-thought baselines. The paper provides a concrete framework for measuring whether tools are helping or hurting in your specific use case - and a lightweight mitigation (G-STEP) when they're hurting.
arXiv
Runner-up: "AgentFloor" (arXiv:2605.00334) benchmarks small open-weight models (0.27B-32B) against GPT-5 across 16,500+ tool-use runs. Key finding: the strongest open-weight performer matched GPT-5 on routine tasks while being dramatically cheaper. Performance gaps appeared only in extended planning.