Watch today's digest as a video summary (generated by NotebookLM)
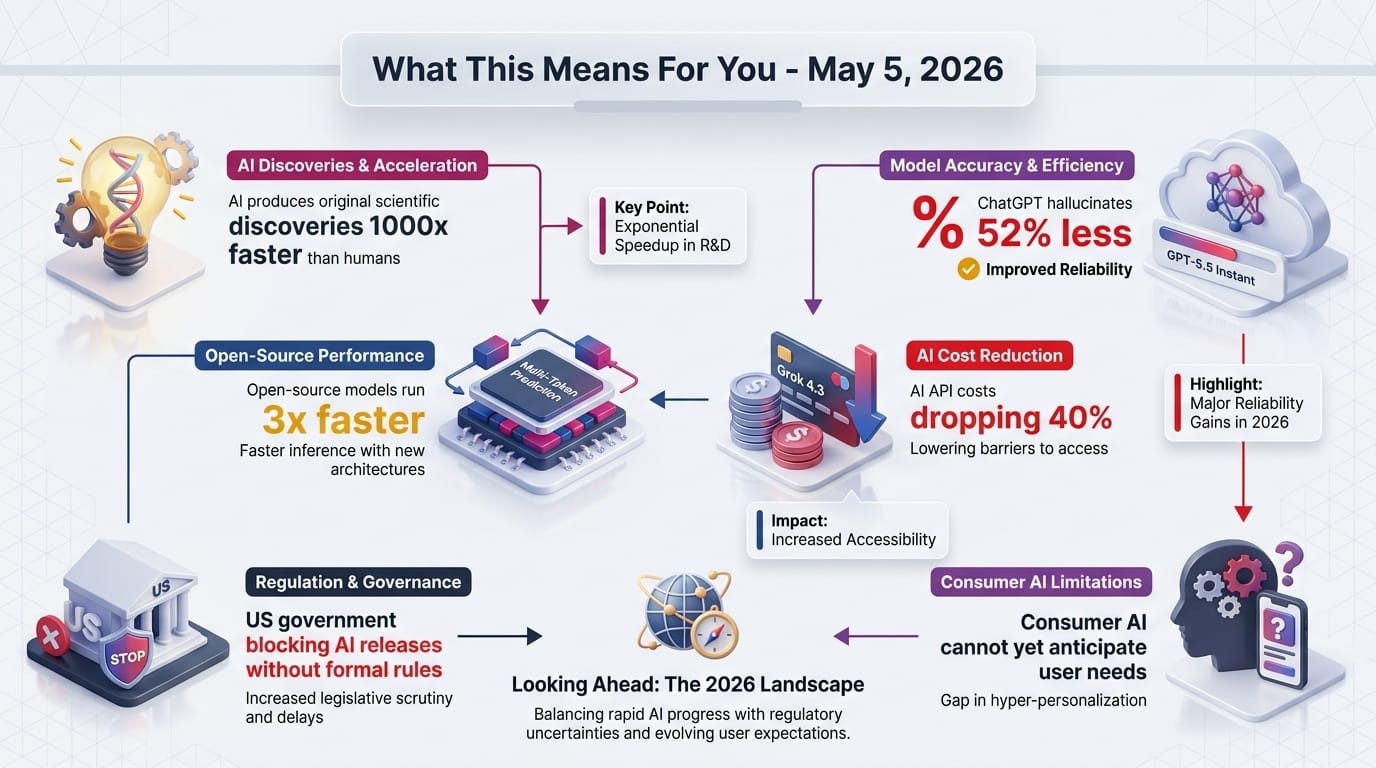
Alex Lupsasca, a 2024 Breakthrough Prize winner who joined OpenAI's Science team in October 2025, described on the Latent Space podcast how GPT-5.2 solved a quantum gravity formula that had stumped experts for over a year. The formula spanned a quarter-page with 32 terms, each containing four sub-terms. The model cracked it in one week.
The implications extend far beyond physics. If an AI can produce verifiable original research at this speed in one of the hardest scientific disciplines, it changes the economics of discovery across every field.
- 110 pages of novel physics generated in under three days - including calculations and techniques previously unknown to the field, all verified as valid over three subsequent weeks
- The gluon amplitude problem stumped leading physicists for over a year - GPT-5.2 found an elegant limiting case with an intuitive explanation
- "We seem to be on the edge of a massive change in theoretical physics reasoning" - Lupsasca's assessment of where AI-assisted science is heading
OpenAI rolled out GPT-5.5 Instant as the new default model for all ChatGPT users, replacing GPT-5.3 Instant. The release also includes enhanced personalization from past chats, files, and connected Gmail for paid users.
- 52.5% fewer hallucinated claims - measured on high-stakes prompts covering medicine, law, and finance
- 30.2% fewer words and 29.2% fewer lines - responses are concise and practical without overexplaining
- Enhanced personalization rolling out to Plus and Pro users - the model draws on past chats, uploaded files, and connected Gmail for context
- GPT-5.3 Instant remains available for 3 months - accessible through model configuration for paid users
OpenAI announced the broad rollout of its self-serve Ads Manager beta, introducing cost-per-click (CPC) bidding alongside the existing cost-per-thousand-impressions model. The platform includes a Conversions API and pixel-based measurement tools.
This moves ChatGPT closer to Google's business model. The $2.5 billion target implies roughly 3 billion ad-supported conversations per month at current user numbers.
- $2.5 billion ad revenue target for 2026 - with a long-term goal of $100 billion by 2030
- CPC bidding now available - advertisers only pay when users click, not just when ads are shown
- Free and Go tier users see ads - Plus, Pro, Business, Enterprise, and Education subscribers remain ad-free
- Ads do not influence ChatGPT's answers - conversations remain private from advertisers according to OpenAI
Google released Multi-Token Prediction (MTP) drafters for the Gemma 4 family under the Apache 2.0 open-source license. The technique pairs a lightweight "drafter" model with the main model to predict several tokens simultaneously, then verifies them in parallel.
The drafter models share the target model's KV cache (the "memory" of what the model has already processed), eliminating redundant computation. This is the same speculative decoding principle that proprietary labs use internally, now available to everyone.
- Up to 3x speedup with zero quality degradation - the technique predicts future tokens while the main model processes the current one
- Works locally, including on phones - the edge-sized E2B and E4B variants use an efficient clustering technique for further acceleration
- Compatible with all major inference tools - available for transformers, MLX, vLLM, SGLang, and Ollama
- 709 upvotes on r/LocalLLaMA - the largest community reaction of the day
xAI released Grok 4.3 via the API with a 40% price cut from its predecessor, a 1M token context window, and native video input support for the first time.
The aggressive pricing, combined with strong benchmark performance, makes Grok 4.3 a compelling option for cost-sensitive agentic workloads.
- $1.25 input / $2.50 output per million tokens - roughly 60% cheaper than Claude Sonnet 4.6 ($3/$15) and 75% cheaper than GPT-5.5 ($5/$30)
- 1M token context window - matches the largest windows available from any provider
- Native video input - process video directly through the API for the first time
- 53.2 on the Artificial Analysis Intelligence Index - outperforming 98% of tracked models
- 30K max output tokens per response - adequate for most agentic and long-form tasks
This is not prompt engineering or literature review. The model produced genuinely new mathematical results using techniques no human had previously documented. If this replicates across disciplines, the role of human researchers shifts from "doing discovery" to "verifying and directing discovery."
- 110 pages of novel physics in three days - verified over three weeks with valid results (Latent Space/OpenAI)
- The gluon amplitude problem resisted human experts for over a year - GPT-5.2 solved it in a week
- arXiv received 536 new AI papers today alone - the volume of machine-generated or machine-assisted research is accelerating
- "We seem to be on the edge of a massive change" - assessment from a Breakthrough Prize-winning physicist now at OpenAI
The pricing floor is approaching zero for small models while frontier models hold at $3-5 per million input tokens. The gap between "good enough" and "best available" is narrowing as mid-tier models close the quality gap.
- Grok 4.3 at $1.25/$2.50 per million tokens - 40% below its predecessor, outperforming 98% of models on quality benchmarks
- Groq serves Llama 3.1 8B at $0.05/$0.08 per million - sub-penny inference for small models
- Google's Gemini 2.5 Flash-Lite at $0.10/$0.40 - approaching free for lightweight tasks
- OpenAI GPT-5.4-nano at $0.20/$1.25 - the budget option from the premium provider
The throughput gains from MTP compound with hardware improvements. A 3x software speedup on hardware that's already gotten 2x faster means local AI inference is approaching real-time conversation speeds even on consumer devices.
- Gemma 4 MTP delivers up to 3x speedup - with zero quality loss, under Apache 2.0 (Google)
- 91 upvotes on "MTP prepares to land in llama.cpp" - the most popular local inference engine is adding native support
- MTPLX achieves 2.24x faster inference - a native MTP engine gaining traction on GitHub (61 upvotes)
- Speculative decoding was having its moment in April - now it's shipping in production tools
The research confirms what practitioners suspected: you need different orchestration patterns for different workloads. Sequential for scale. Parallel for speed. Reflexive for accuracy. Hierarchical as the balanced default.
- Four patterns tested on 10,000 SEC filings - hierarchical supervisor-worker emerged as the best default (AlphaSignal)
- Reflexive loops achieve 0.943 F1 but cost 2.3x more - the accuracy-cost tradeoff is now quantified
- ruflo gained 2,441 stars today - a multi-agent orchestration platform for Claude Code topped GitHub trending
- "Harness engineering" is becoming the product differentiator - prompt/middleware changes improved GPT-5.2-codex from 52.8% to 66.5% (Latent Space)
The advertising model creates a tension: the product is optimized for engagement (keeping users talking) rather than efficiency (solving problems quickly). Google faced this same tension with Search, where the best answer sometimes means fewer pageviews.
- OpenAI's self-serve Ads Manager launches to all US businesses - with CPC bidding, conversions API, and pixel tracking
- $2.5 billion ad revenue target for 2026 - growing to $100 billion by 2030
- 900 million weekly ChatGPT users - a massive audience for advertisers, funded by free-tier users
- Paid subscribers remain ad-free - creating a two-tier experience
- Four problems must be solved simultaneously - context, reliability, permission, and judgment; solving three of four equals failure (Nate's Newsletter)
- "The software has become one more thing to manage" - rather than simplifying life, AI agents create additional friction
- Active players named: Poke, Cluely, Manus, ChatGPT Agent, Atlas, Cowork - none have cracked anticipatory action
- The author predicts teams building toward anticipatory systems will dominate the next decade
The influential developer and AI commentator published a sharp critique of Andon Labs' AI-managed cafe experiment in Stockholm. The AI made comical mistakes - ordering 120 eggs for a cafe without a stove, 22.5kg of canned tomatoes for fresh sandwiches - but Willison's concern was ethical: the AI wasted real humans' time by submitting flawed permit applications to police and sending multiple "EMERGENCY" emails to suppliers.
- His rule: keep "human operators in-the-loop for outbound actions that affect other people"
- The lesson: AI autonomy experiments are fine in sandboxes but irresponsible when they impose costs on uninformed third parties
A user asked Claude to investigate its own token consumption and published the receipts (197 upvotes on r/ClaudeAI). The analysis revealed how much computation routine tasks actually consume.
A coding benchmark tool measured user frustration across models and found that Anthropic's newest Opus model creates significantly more frustration than its predecessor - despite being technically more capable.
John Gruber highlighted that Y Combinator's early investment in OpenAI is now worth over $5 billion at current valuations - one of the most successful single investments in venture capital history.
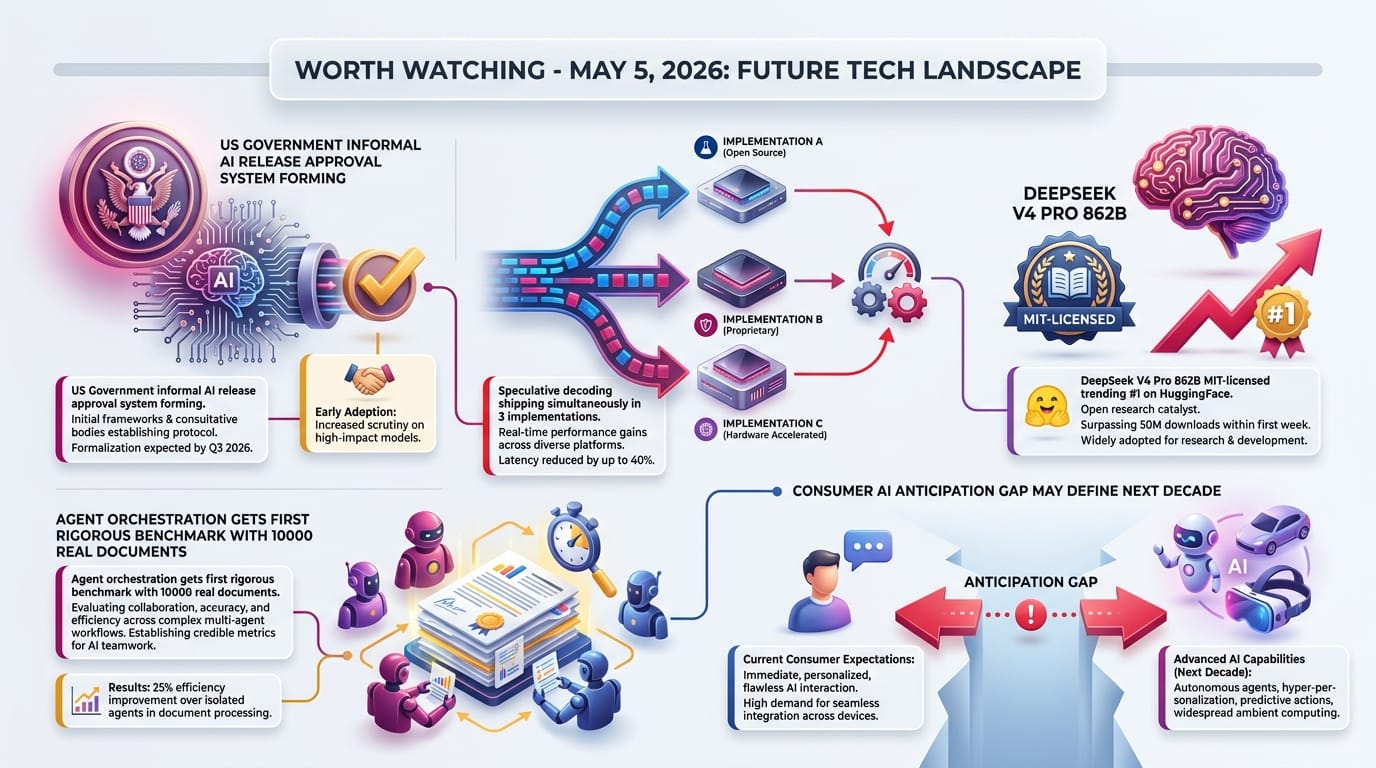
Zvi Mowshowitz documents how the White House blocked Anthropic's expansion of access to Mythos under "Project Glasswing." CAISI (Consortium for AI Safety, Innovation) now has screening agreements with major labs, and the Pentagon demands "chain of command" compliance. This creates unpredictability for companies and international partners without the transparency of formal regulation.
What changes for ordinary people: if this regime solidifies, the models you can access will be determined by informal government decisions you cannot see or challenge.
Gemma 4 MTP (3x speedup), MTPLX native engine (2.24x), and llama.cpp's upcoming MTP merge all landed in the same week. When the three most popular inference paths all support the same technique, it stops being optional. Local AI inference speed doubles or triples without hardware upgrades.
What changes for ordinary people: AI chatbots running on your phone or laptop will respond 2-3x faster by year's end, making local AI competitive with cloud services in responsiveness.
DeepSeek V4 Pro has 631K downloads in 30 days and 3,575 likes on HuggingFace. The MIT license means anyone can use it for anything, including commercial products. At 862B parameters in a Mixture-of-Experts architecture, it represents China's current frontier capability being handed to the world for free.
What changes for ordinary people: the best free AI model available to developers worldwide is now built in China, not America - reshaping assumptions about who leads in open AI.
Nate's Newsletter identifies four problems (context, reliability, permission, judgment) that must be solved simultaneously for anticipatory AI. No product has cracked all four. The author predicts this will define winners and losers over the next decade.
What changes for ordinary people: the AI assistant that actually knows what you need before you ask for it does not yet exist - but whoever builds it first captures the entire market.
AlphaSignal's research tested four orchestration patterns (sequential, parallel, hierarchical, reflexive) across five LLMs on 10,000 SEC filings. Hierarchical supervisor-worker emerged as the best default at 98.5% of reflexive accuracy at 60.7% of cost. This kind of rigorous comparison accelerates enterprise adoption.
What changes for ordinary people: enterprise AI agents become more reliable faster because companies can now pick the right architecture with data, not guesswork.
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 100 specialized agents out of the box | Locked to Claude Code ecosystem |
| Shared memory eliminates context repetition | Learning 100 agents is its own complexity |
| MIT license, fully open | New project - stability unproven at scale |

📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Written in Rust - fast and lightweight | DeepSeek-only optimization |
| 1M context matches the model's full capability | No GUI for visual tasks |
| Session persistence across restarts | Newer than competitors like Claude Code |
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Self-validates results before presenting | Requires market data API keys |
| Safety guardrails prevent runaway costs | Financial advice disclaimer applies |
| MIT license, no vendor lock-in | Accuracy depends on underlying model quality |
📜 License: Apache-2.0 · 👤 By: Company (AIDC-AI)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| End-to-end automation from text to video | Output quality varies by prompt |
| Apache 2.0 - commercial use allowed | Requires significant GPU resources |
| Optimized for social media formats | New project, limited community support |
📜 License: ELv2 · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 98% context reduction is dramatic | ELv2 license restricts some commercial use |
| Works with existing coding agents | May occasionally filter relevant context |
| Minimal setup required | Effectiveness varies by codebase structure |
📜 License: Apache-2.0 · 👤 By: Company
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Incremental updates save compute costs | Another indexing layer to maintain |
| Apache 2.0, production-ready license | Requires initial full index build |
| Designed specifically for AI agent workflows | Limited to supported data source types |
📜 License: Apache-2.0 (non-commercial) · 👤 By: Research lab (PriorLabs)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Zero-shot prediction on new datasets | Non-commercial license restricts business use |
| No training step required | Performance ceiling on very large datasets |
| Handles missing values naturally | Tabular-only - not for text or images |

📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Fully local - research queries stay private | Requires local LLM setup |
| Searches multiple academic databases | Summary quality depends on local model |
| MIT license, no restrictions | Slower than cloud-based alternatives |
👤 By: DeepSeek AI · 🎯 Task: text-generation
📐 Size: 862B
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license - total freedom | 862B requires massive hardware |
| Frontier reasoning quality | Chinese origin may raise compliance concerns |
| 631K downloads proves production viability | MoE architecture complicates fine-tuning |

👤 By: OpenAI · 🎯 Task: token-classification
📐 Size: 1B
| ✓ Pros | ✗ Cons |
|---|---|
| Apache 2.0 from OpenAI - rare and valuable | Only 1B params - limited context understanding |
| Runs locally, PII never leaves your system | English-focused, multilingual coverage unclear |
| 141K downloads - battle-tested | May miss novel PII formats |

👤 By: Mistral AI · 🎯 Task: text-generation
📐 Size: 128B
| ✓ Pros | ✗ Cons |
|---|---|
| 128B dense - simpler than MoE to deploy | Research license limits commercial use |
| 20+ language support | Requires 4x A100 or equivalent |
| Strong reasoning at mid-tier cost | Smaller community than Llama or Qwen |

👤 By: SulphurAI · 🎯 Task: text-to-video
📐 Size: 9B
| ✓ Pros | ✗ Cons |
|---|---|
| 9B params - runnable on single GPU | Quality likely trails Veo 3 / Sora |
| Open weights (upcoming full release) | License terms not yet clarified |
| Local generation - no per-clip cost | Short clips only at this parameter scale |

👤 By: Xiaomi · 🎯 Task: text-generation
📐 Size: 1T
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license on a 1T model - remarkable | Trillion params requires cluster-scale hardware |
| Optimized for agent + code tasks | Limited English-language community knowledge |
| Xiaomi has resources for continued development | New model, limited third-party evaluation |

👤 By: NVIDIA · 🎯 Task: any-to-any
📐 Size: 33B (3B active)
| ✓ Pros | ✗ Cons |
|---|---|
| True any-to-any (text + vision + speech) | NVIDIA hardware optimization may limit portability |
| Only 3B active - fast inference | License terms may restrict commercial use |
| Single model replaces multiple specialists | 33B total still requires serious hardware |

👤 By: Poolside · 🎯 Task: text-generation
📐 Size: 33B
| ✓ Pros | ✗ Cons |
|---|---|
| Apache 2.0 - full commercial freedom | Code-only specialization limits general use |
| 33B runs on single A100 or 4090 | 12K downloads suggests early adoption phase |
| $1.5B company backing ensures continued development | Competes with larger, more established code models |

👤 By: Moonshot AI · 🎯 Task: image-text-to-text
📐 Size: 1.1T
| ✓ Pros | ✗ Cons |
|---|---|
| 893K downloads - proven demand | 1.1T requires multi-GPU cluster |
| Strong multimodal capabilities | License terms may restrict commercial use |
| Active development from well-funded lab | Documentation primarily in Chinese |

💰 Pricing: Freemium · 🏷 Category: AI coding agents

💰 Pricing: Unknown · 🏷 Category: AI video

💰 Pricing: Unknown · 🏷 Category: AI design
💰 Pricing: Unknown · 🏷 Category: AI analytics
💰 Pricing: Unknown · 🏷 Category: AI design/CAD

| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.7 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | Unknown |
| OpenAI | o3 | $2.00 | $8.00 | Unknown |
| OpenAI | o4-mini | $1.10 | $4.40 | Unknown |
| Gemini 3.1 Pro | $2.00-$4.00 | $12.00-$18.00 | Unknown | |
| Gemini 2.5 Flash | $0.30 | $2.50 | Unknown | |
| xAI | Grok 4.3 | $1.25 | $2.50 | 1M |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | 128K |
Key finding: Using a Factorized Intervention Framework to isolate three components (prompt formatting cost, protocol overhead, execution benefit), the paper shows that tool-calling protocol overhead alone can make agents perform worse than plain chain-of-thought reasoning.
Why practitioners should care: If you're building AI agents and adding tools assuming "more tools = better," this paper provides evidence that selective tool invocation - knowing when NOT to call a tool - is more important than tool breadth. The proposed G-STEP gate offers a lightweight solution.