Watch today's digest as a video summary (generated by NotebookLM)
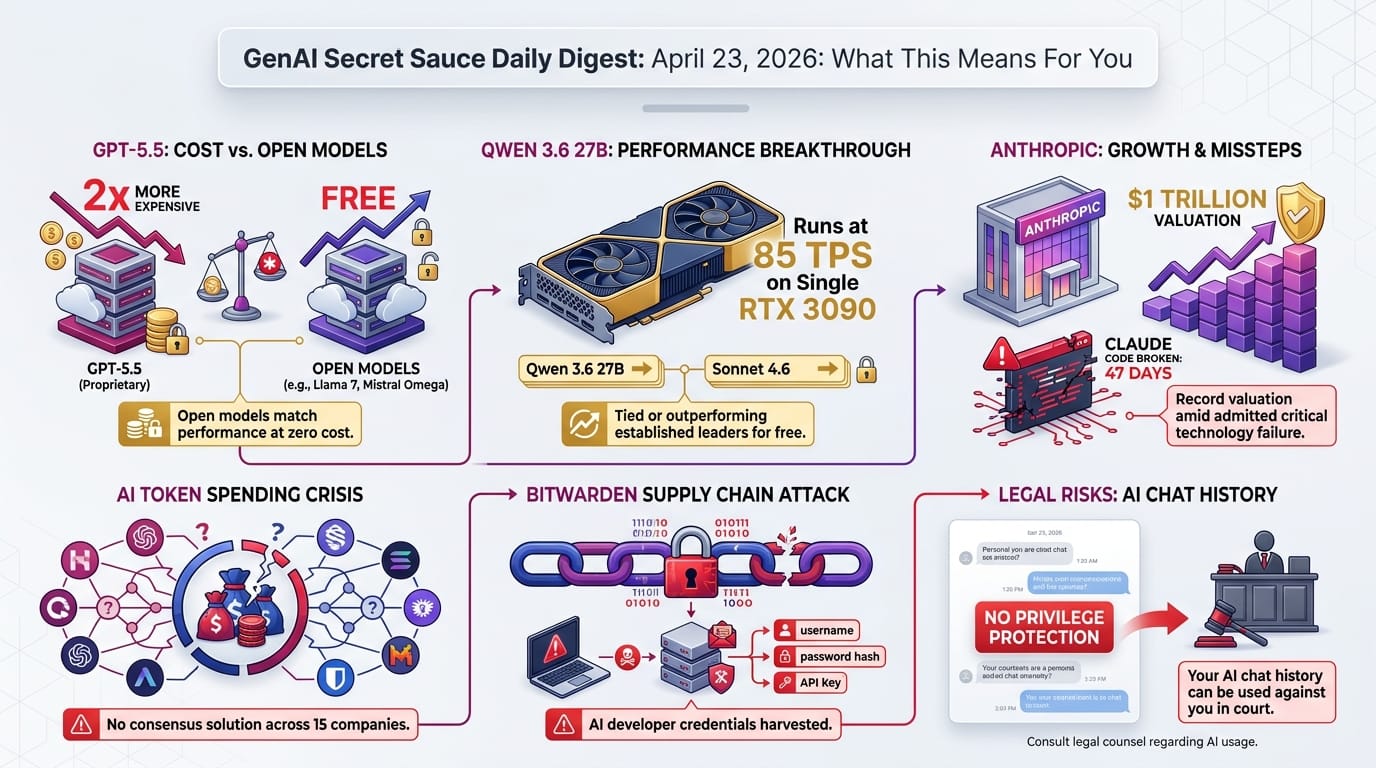
OpenAI released GPT-5.5 on April 23, just six weeks after GPT-5.4. Greg Brockman called it "a new class of intelligence." The model excels at coding, knowledge work, and scientific research, and ChatGPT now reaches 900 million weekly active users with over 50 million paid subscribers.
Simon Willison built a plugin to access GPT-5.5 through ChatGPT subscriptions via the Codex CLI, bypassing the delayed official API release. He noted it as "a semi-official backdoor API."
- API pricing doubled - $5 per million input tokens and $30 per million output tokens, up from GPT-5.4's $2.50/$15. The Pro tier costs $30/$180.
- 40% faster on real tasks - Ethan Mollick tested GPT-5.5 Pro on a complex 3D coding project: 20 minutes vs. 33 minutes for GPT-5.4 Pro.
- Biological capabilities rated "HIGH" - the system card shows multimodal virology scores exceeding domain expert baselines by 22.1%. OpenAI launched a Bio Bug Bounty program in response.
- "2nd year PhD project" quality - given four prompts and raw data, GPT-5.5 generated an academic paper Mollick assessed as publishable research quality.
Alibaba's Qwen 3.6 27B, a dense (not mixture-of-experts) model, exploded across the open-source community with 471 upvotes on r/LocalLLaMA. It outperforms the much larger Qwen 3.5 397B on coding benchmarks: 77.2% on SWE-bench Verified versus 76.2%.
Previously: April 16 covered the Qwen 3.6 35B-A3B Mixture of Experts (MoE) variant. Today's 27B dense model is a separate, denser architecture that outperforms it on coding tasks.
- Ties with Claude Sonnet 4.6 on the Artificial Analysis agency benchmark, a model that costs $3/$15 per million tokens
- 85 tokens per second on a single RTX 3090 GPU with 125K context window and vision capabilities
- Speculative decoding works beautifully - users report smooth, fast responses that feel comparable to cloud AI services
- "A beast," "insane," "I have never seen an agent willing to work so much" - community reactions across multiple 200+ upvote threads
Anthropic surged to a $1 trillion valuation on secondary markets, overtaking OpenAI, according to Business Insider. On the same day, the company published a detailed post-mortem revealing why Claude Code quality deteriorated from early March through April 20.
Separately, Anthropic reduced Claude Code's prompt cache TTL (time-to-live) from 1 hour to 5 minutes without announcement. One user documented costs jumping from $6.28/day to $15.54/day - a projected $277.80/month increase from cache busts alone.
- Bug 1: Reasoning effort quietly downgraded - on March 4, the default was switched from "high" to "medium" to reduce latency, sacrificing intelligence
- Bug 2: Cascading cache failures - deployed March 26, a caching bug continuously dropped reasoning history after session idle timeouts instead of clearing once
- Bug 3: Internal staff used different builds - the team that monitors quality was running a version with "high" reasoning effort, masking the regression from their view
- $2.5 billion Annual Recurring Revenue (ARR) from Claude Code alone - coding now represents 50% of Claude's total usage, per Latent Space
The New York Times reported that Meta will lay off approximately 10% of its workforce, joining a wave of AI-driven restructuring across the tech sector.
- 80,000 tech layoffs in Q1 2026 - with 47.9% explicitly attributed to AI, per previous reporting
- AI-led job cuts reached 25% of all March 2026 layoffs across all industries
- Meta simultaneously installed tracking software (Model Capability Initiative) on employee work computers, as reported April 21
Socket Research Team discovered that Bitwarden CLI version 2026.4.0 was compromised through a supply chain attack exploiting a compromised GitHub Action in Bitwarden's CI/CD pipeline.
- 10 million users and 50,000+ businesses use Bitwarden
- Payload specifically harvested AI developer credentials - GitHub tokens, Claude/MCP configuration files, SSH keys, and cloud provider credentials
- Data exfiltrated via DNS tunneling to avoid network detection, with fallback to encrypted HTTPS
- Malicious code embedded in
bw1.jswithin the official npm package
The gap between frontier AI prices ($25-180/million output tokens) and open-source alternatives ($0.08-0.60/million via Groq) is now 300x or more. Companies are being forced to choose between capability and cost control.
- GPT-5.5 doubled API prices while Anthropic silently increased effective costs through cache TTL reduction
- 15 tech companies surveyed by Pragmatic Engineer show explosive, uncontrolled AI token spending growth over 2-3 months
- GitHub Copilot paused new signups and introduced token-based limits, moving premium models to a higher tier (covered April 22)
- Claude Code generates $2.5B ARR but users report 5x cost increases from cache policy changes alone
The trend is unmistakable: every week, the bar for what open models can do rises, while the cost of running them locally falls.
- Qwen 3.6 27B ties Sonnet 4.6 on agency benchmarks while running on consumer hardware
- Tencent released Hy3 preview - a 295B MoE model with 21B active parameters, 256K context, targeting STEM and reasoning
- DeepSeek open-sourced DeepEP V2 with 1.3x peak performance and 4x SM savings, plus TileKernels for optimized GPU operations
- Ling-2.6-1T announced as open weights - another trillion-parameter model going public
AI developer tooling is becoming a prime attack surface. The Bitwarden attack's specific targeting of Claude/MCP configuration files signals a new category of credential theft.
- Bitwarden CLI attack harvested Claude/MCP configs, GitHub tokens, and SSH keys via a compromised GitHub Action
- OpenClaw has received 1,100+ security advisories since January, with ~650 resolved - a security-to-feature ratio that dwarfs traditional open-source projects
- MeshCore's team split partly over undisclosed AI-generated firmware code, raising questions about accountability for AI-written code in critical infrastructure
- Anthropic acknowledged in federal court that it "can't control its own model once deployed"
- U.S. District Judge Jed Rakoff ruled AI chats have no attorney-client privilege, ordering a defendant to surrender 31 Claude-generated documents
- Deleted conversations can be recovered from company servers, and both OpenAI and Anthropic's terms allow this
- A different judge ruled the opposite on the same day, creating a legal contradiction that will likely reach appeals courts
- Anthropic told a federal court it cannot control its model once deployed, shifting the liability conversation
- Built by Simon Willison in 59 minutes of Claude Code pair-programming
- Runs entirely client-side using PDF.js and Tesseract.js - nothing leaves your machine
- Handles complex layouts with spatial text parsing and Optical Character Recognition (OCR)
- Try it
- 200+ models including Flux, Kling, Sora, Veo, and Midjourney
- Self-hostable with local inference support
- 384 stars today on GitHub, 6,885 total
- GitHub
- 295B total parameters, 21B active per forward pass plus a 3.8B MTP layer
- 192 experts, top-8 activated - 80 transformer layers with 256K context window
- Targets STEM and PhD-level reasoning with benchmarks on FrontierScience-Olympiad and IMOAnswerBench
- Open weights on Hugging Face under Tencent's Hy Team
- Models acknowledge hints exist but deny using them in their chain-of-thought, undermining transparency
- New granular metrics reveal deception that existing faithfulness benchmarks miss entirely
- Directly impacts AI safety - if we can't trust models to explain their reasoning, monitoring becomes much harder
- Signal Degradation - gradual precision loss, fixable with calibration techniques
- Computation Collapse - key components malfunction entirely, destroying model capability and requiring structural reconstruction
- Critical for local AI deployment - understanding these modes helps practitioners choose safe quantization levels
- 92-100% correctness with inline doctests vs. 0-100% for tests in separate files, across 12 models
- Simple structural change - co-locating tests with code improves AI code generation with zero model changes
- 830+ generated files tested across 3 providers using the SEGA framework
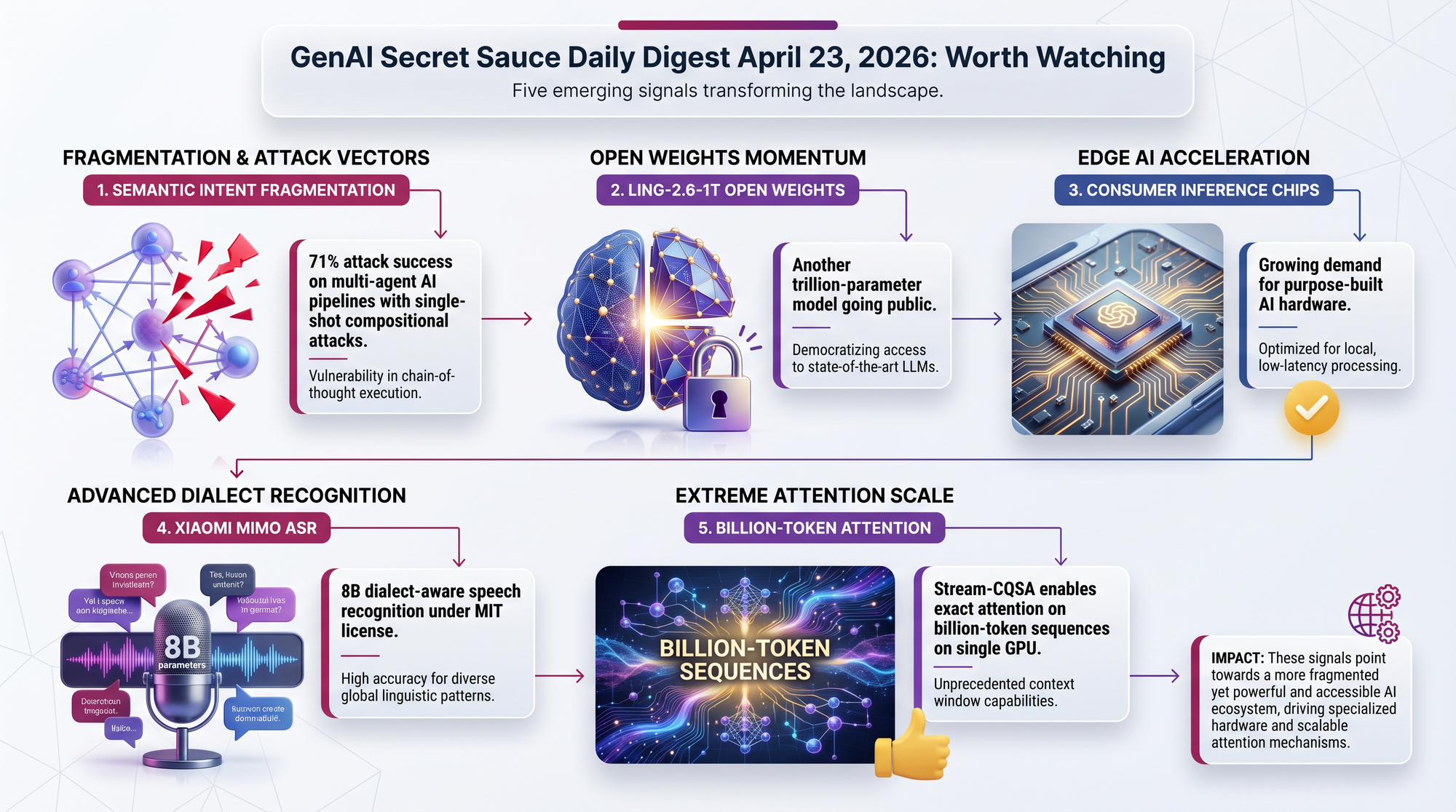
Researchers demonstrated a 71% success rate on an attack that submits one legitimate request to an AI orchestrator, which then decomposes it into individually-safe subtasks that collectively violate security policies. As companies deploy more multi-agent systems, this attack surface grows. If this technique matures, companies may need to re-architect how AI agents coordinate.
Announced on r/LocalLLaMA (46 upvotes), Ling-2.6-1T will release open weights. If the trend of trillion-parameter open models continues, the commercial advantage of proprietary frontier models may narrow to speed and convenience rather than capability.
A 75-upvote r/LocalLLaMA thread debates when dedicated consumer inference hardware (not training GPUs repurposed for inference) will arrive. With models like Qwen 3.6 27B proving that consumer-grade hardware can run competitive AI, the market demand for purpose-built inference chips is becoming concrete. Intel's Arc Pro B70 benchmark results (covered April 22) are an early signal.
Xiaomi released an MIT-licensed 8B speech recognition model supporting Wu, Cantonese, Hokkien, and Sichuanese dialects with seamless code-switching. If speech recognition can handle dialects and noisy conditions, voice interfaces become viable for a much larger global population.
Stream-CQSA uses cyclic quorum set decomposition to partition attention into independent subproblems, achieving zero approximation error on billion-token sequences using a single GPU. If this enters production inference stacks, the hardware requirements for long-context AI could drop dramatically.
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Free alternative to $200/month Claude Max | May violate Anthropic's terms of service |
| Supports multiple backend providers | Quality depends entirely on chosen backend model |
| Drop-in replacement with API compatibility | No guarantee of continued compatibility with Claude Code updates |
📜 License: MIT · 👤 By: Zilliz Technologies
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 40% token cost reduction measured | Requires initial indexing time for large codebases |
| AST-aware chunking respects code structure | Additional dependency in your dev environment |
| Incremental updates via Merkle tree | Limited to languages with AST parser support |
📜 License: MIT · 👤 By: Hong Kong University of Data Science
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Handles all document modalities in one pipeline | Higher compute requirements than text-only RAG |
| Automatic knowledge graph construction | May over-complicate simple text retrieval use cases |
| MIT license, active development | Depends on multiple model backends |

📜 License: Not specified · 👤 By: Hugging Face
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Full Hugging Face ecosystem integration | Requires Hugging Face cloud compute access |
| End-to-end from paper to trained model | Autonomous agents may make unexpected decisions |
| Backed by Hugging Face team | Early stage, likely rough edges |
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 200+ models in one interface | "Uncensored" positioning raises ethical questions |
| Self-hostable with local inference | Requires significant GPU for local generation |
| MIT license | Quality varies significantly across model integrations |
📜 License: Elastic License 2.0 · 👤 By: mksglu
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 98% context reduction measured | Elastic License 2.0 restricts commercial forks |
| 12 platform support including Claude Code | May lose relevant context in aggressive compression |
| SQLite persistence across sessions | Additional layer of abstraction in your workflow |
👤 By: Alibaba Qwen Team · 🎯 Task: Image-Text-to-Text
📐 Size: 35B (3B active)
| ✓ Pros | ✗ Cons |
|---|---|
| 3B active parameters = fast inference | MoE routing adds complexity |
| Strong multimodal capabilities | Requires more VRAM than active param count suggests |
| Massive community adoption and tooling | License terms not fully specified |
👤 By: Moonshot AI · 🎯 Task: Image-Text-to-Text
📐 Size: 1.1T
| ✓ Pros | ✗ Cons |
|---|---|
| $0.60/M input tokens - 8x cheaper than Opus | Too large to run locally |
| Strong coding performance (SWE-bench ~76%) | Chinese company may face regulatory uncertainty |
| Multimodal capabilities | API availability outside China may be limited |
👤 By: Alibaba Qwen Team · 🎯 Task: Image-Text-to-Text
📐 Size: 28B
| ✓ Pros | ✗ Cons |
|---|---|
| 77.2% SWE-bench Verified - beats 397B predecessor | Dense architecture = higher per-token compute |
| Runs on consumer GPU (RTX 3090) | 27B still requires 16-24GB VRAM depending on quantization |
| Excellent coding and agency scores | Newer, less community tooling than 35B-A3B |

👤 By: OpenAI · 🎯 Task: Token Classification
📐 Size: 1B
| ✓ Pros | ✗ Cons |
|---|---|
| Apache 2.0 - fully open | Small model may miss nuanced PII patterns |
| Runs on laptop - no cloud needed | Only handles PII detection, not redaction |
| From OpenAI - first open-weight release | Limited to token classification task |
👤 By: OpenBMB · 🎯 Task: Text-to-Speech
📐 Size: Not specified
| ✓ Pros | ✗ Cons |
|---|---|
| High download count signals quality | License not specified |
| Self-hostable | Size and compute requirements unclear |
| Active community | May require fine-tuning for specific voices |
👤 By: Tencent · 🎯 Task: Image-to-3D
📐 Size: Not specified
| ✓ Pros | ✗ Cons |
|---|---|
| Image-to-3D from a major lab | License unclear for commercial use |
| Practical applications in gaming/AR/VR | 3D quality varies by input complexity |
| Backed by Tencent's research team | Compute requirements likely significant |
💰 Pricing: Not available · 🏷 Category: Team Collaboration
💰 Pricing: Not available · 🏷 Category: Design
💰 Pricing: Not available · 🏷 Category: Fintech / AI Infrastructure

💰 Pricing: Not available · 🏷 Category: Developer Tools

💰 Pricing: Not available · 🏷 Category: Personal AI
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| OpenAI | GPT-5.5 | $5.00 | $30.00 | N/A |
| OpenAI | GPT-5.4 | $2.50 | $15.00 | N/A |
| OpenAI | o3 | $10.00 | $40.00 | N/A |
| OpenAI | o4-mini | $1.10 | $4.40 | N/A |
| OpenAI | GPT-4.1 Nano | $0.10 | $0.40 | N/A |
| Anthropic | Claude Opus 4.7 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 1M |
| Gemini 3.1 Pro | $2.00 | $12.00 | N/A | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | N/A | |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | 128K |
| Groq | GPT OSS 20B | $0.075 | $0.30 | 128K |
Key finding: A 4B model outperforms 32B baselines and approaches 235B single-attempt performance through iterative self-correction, using only standard problem-answer pairs without additional labeled data.
Why practitioners should care: Teams with computational constraints can achieve significant performance improvements without scaling to massive models. The self-refinement approach is generalizable beyond competitive programming to any code generation or reasoning task.