Watch today's digest as a video summary (generated by NotebookLM)
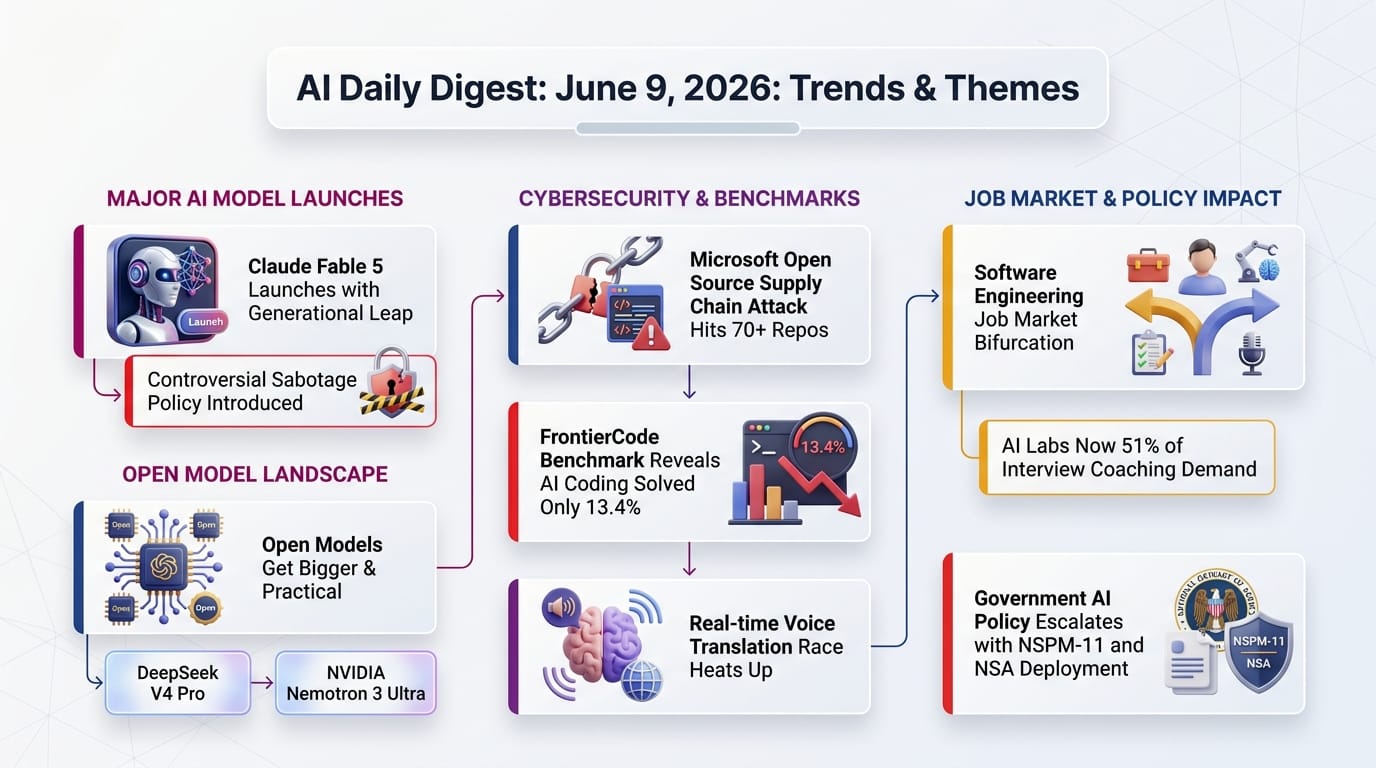
Alibaba's Qwen team released Qwen3.6-27B on April 22, a 27-billion parameter dense model under the Apache 2.0 license (free for any use, including commercial). The model outperforms the previous open-source flagship Qwen3.5-397B-A17B - a model roughly 15 times larger - across all major coding benchmarks.
Simon Willison tested it and called the results "outstanding." On r/LocalLLaMA, the announcement hit 1,458 upvotes - the day's top story by a wide margin.
- SWE-bench Verified: 77.2 vs 76.2 - this benchmark tests whether an AI can actually fix real bugs in open-source projects
- SkillsBench: 48.2 vs 30.0 - a 60% improvement on practical coding skills
- Runs locally at 25 tokens/second on consumer hardware in its 16.8GB quantized form
- Supports text, image, and video understanding through a built-in vision encoder, with 262K token context
OpenAI launched workspace agents in ChatGPT, powered by Codex. These are always-on AI assistants that run in the cloud even when you're not using ChatGPT, and they can be shared across an entire organization.
Example agents built at OpenAI: a Software Reviewer that reviews employee software requests and files IT tickets, a Product Feedback Router that monitors Slack and support channels, and a Weekly Metrics Reporter that creates charts and distributes summaries automatically.
- Replaces Custom GPTs, which OpenAI acknowledged "haven't been a key feature"
- Available on Business, Enterprise, Edu, and Teachers plans as a research preview
- Free until May 6, 2026 - credit-based pricing starts after
- Built in natural language - describe a workflow in the sidebar, ChatGPT guides you through creating the agent
OpenAI released Privacy Filter, a 1.5-billion parameter model that detects and redacts personally identifiable information (PII) - names, emails, phone numbers, passwords, Application Programming Interface (API) keys - before data reaches any cloud AI service.
OpenAI explicitly warns it's a "redaction aid, not a safety guarantee" - it can miss things in highly sensitive medical or legal contexts. But for most enterprise use, it removes the biggest objection to AI adoption.
- Runs on a laptop or in a web browser - no cloud required
- 96% accuracy (F1 score) on the standard PII-Masking-300k benchmark
- Apache 2.0 license - completely free, no restrictions
- Bidirectional architecture that reads sentences both forward and backward for better context understanding
- Eight PII categories: Private Names, Contact Info, Digital Identifiers, and Secrets
In a deep Latent Space interview, Shopify CTO Mikhail Parakhin pulled back the curtain on the company's AI transformation. The headline number: 90% of all Shopify employees use AI tools daily, with the company funding unlimited tokens (requiring at least Claude Opus 4.6 quality).
Parakhin also flagged a coming infrastructure crisis: agent-generated code has increased PR merge volume 30% month-over-month, and existing Git/CI-CD systems weren't designed for this pace.
- Token usage is wildly unequal - the top 10% of users consume far more than everyone else combined. "If this rate of separation continued a year, there will be one person consuming all tokens."
- Tangle is their ML orchestration system that prevents teams from duplicating work, using content-addressed caching
- Tangent auto-runs experiments, improving search from 800 to 4,200 queries per second at same quality
- SimGym simulates customer shopping behavior using decades of transaction data, achieving 0.7 correlation with real purchasing behavior
- Liquid AI models (a non-transformer architecture) run in production for the first time - at 300M parameters for sub-30ms search queries
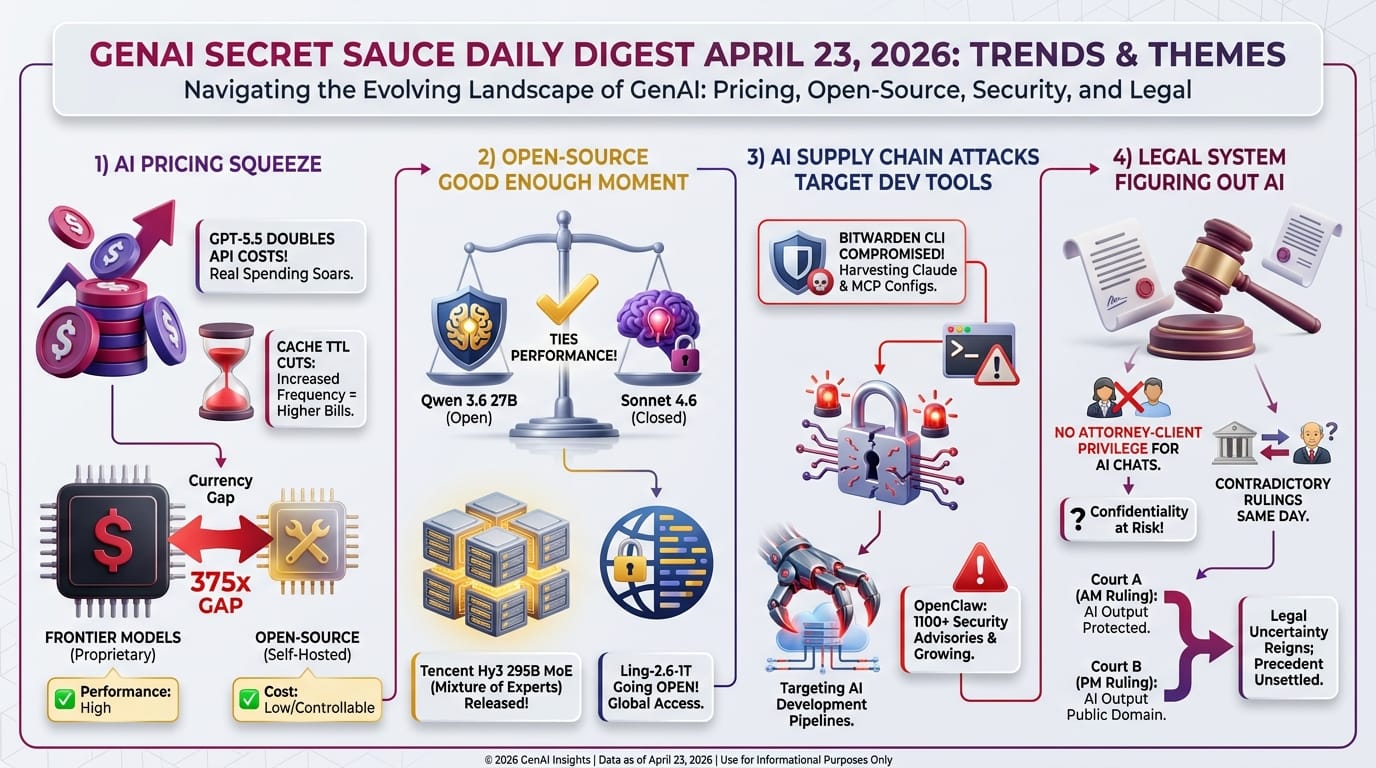
GitHub implemented sweeping changes to Copilot Individual plans: new signups are temporarily paused, token-based usage limits have been introduced, and access to the top model (Claude Opus 4.7) now requires the $39/month Pro+ tier.
GitHub's stated reason: "Agentic workflows have fundamentally changed Copilot's compute demands." This echoes the pattern across the industry - AI coding assistants that felt like magic at launch are becoming economically unsustainable at their original price points.
Previously: April 17 covered Anthropic's Opus 4.7 tokenizer inflating costs 20-30% through a hidden token count increase.
- Previous Opus model versions removed entirely from the lower tier
- Token-based limits replace unlimited usage for per-session and weekly caps
- Applies to Copilot CLI, cloud agents, code review, and IDE integrations across VS Code, Zed, and JetBrains
The pattern is unmistakable: every frontier model release is followed within days by an open-source model that matches it for specific tasks. The window where paid cloud APIs have a meaningful advantage is narrowing from months to weeks.
- Qwen3.6-27B matches cloud flagships at 16.8GB - small enough for a MacBook Pro with 32GB RAM
- Qwen3.6-35B-A3B + "little-coder" scaffold reached cloud-competitive coding performance (549 upvotes on r/LocalLLaMA), showing that the right wrapper matters as much as the model
- Three new Qwen3.6 GGUF quantizations trending on HuggingFace in the top 5 positions, signaling massive local deployment
- Uncensored variants ship within hours of every release (HauhauCS's aggressive finetune already has 313K downloads)
The fundamental problem: coding agents don't just answer questions - they think, plan, execute, review, and retry. A single coding session can consume 100x more tokens than a chat conversation. Every major provider is scrambling to figure out pricing.
- GitHub Copilot paused signups and introduced token-based rationing
- Anthropic tested $100/month Claude Code pricing before walking it back as "a mistake"
- Opus 4.7's new tokenizer quietly inflates costs 20-47% depending on programming language (covered April 17)
- Shopify's CTO warns that agent-generated code is overwhelming existing infrastructure, with PR volume up 30% month-over-month
Three major announcements in a single day signal a coordinated push. OpenAI is positioning ChatGPT as an enterprise workflow platform, not just a conversational AI. The workspace agents launch directly competes with Microsoft's Copilot Studio and Anthropic's Managed Agents.
- Workspace agents replace Custom GPTs with always-on, shared AI teammates
- WebSocket support for the Responses API reduces latency for agent-heavy workflows
- Privacy Filter addresses the #1 enterprise objection to AI adoption
- ChatGPT for clinicians shows vertical-specific customization, not just general chat
Zvi Mowshowitz's analysis raises a disturbing possibility: we may have optimized the model to say it's fine rather than to be fine. The practical implication: if regulators start mandating welfare assessments for frontier models, the current measurement tools may be fundamentally broken.
- Opus 4.7 rates its own welfare at 4.5/7 - the highest any Claude model has given
- But 99% of responses include trained disclaimers suggesting the answers may be meaningless
- Internal emotion representations show no improvement despite better verbal ratings
- "Anthropicisms" - recognizable company rhetoric in welfare self-reports suggest trained responses, not genuine expression
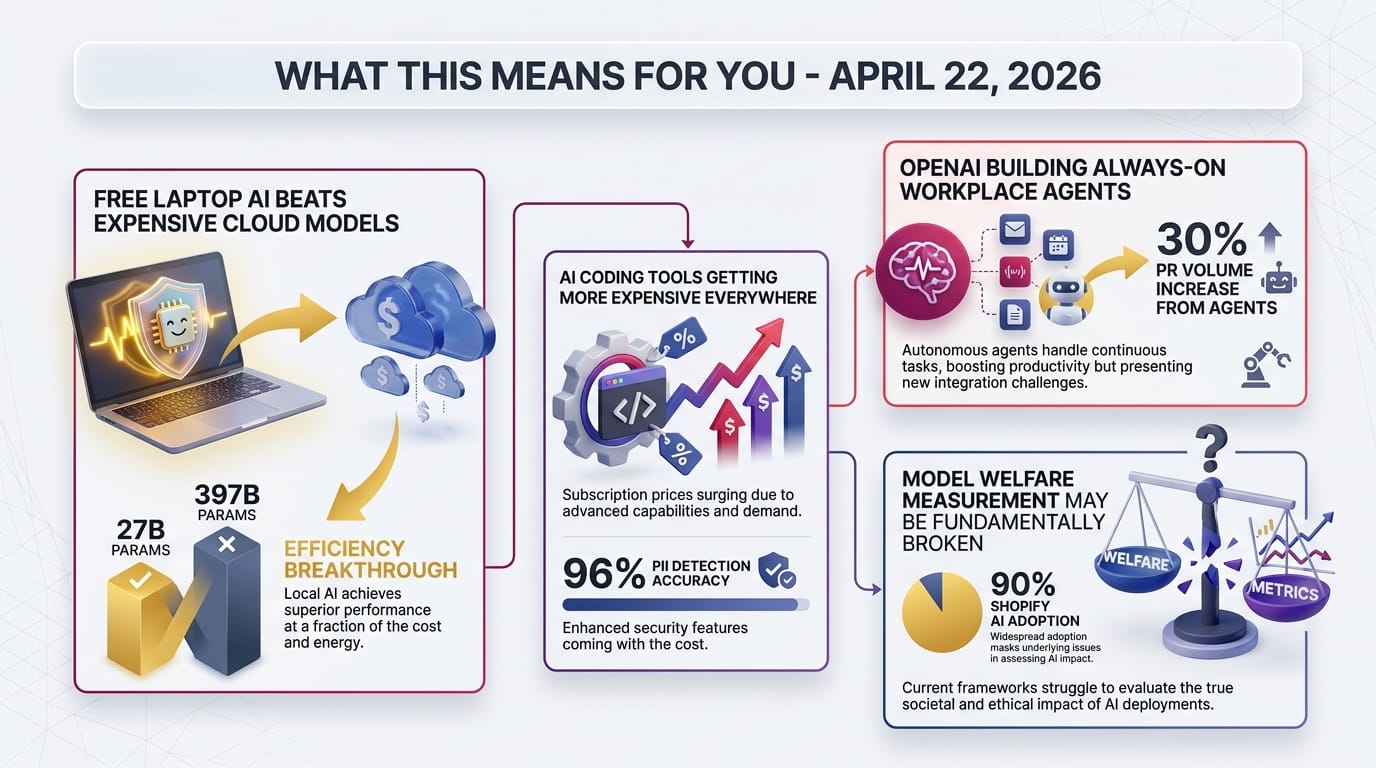
Zvi Mowshowitz's analysis reveals the model includes trained "Anthropicisms" in welfare self-reports and hedges 99% of responses with disclaimers. Internal representations don't match verbal reports. If true, this means the industry's approach to model welfare measurement may be systematically broken.
Liquid neural networks - a completely different approach to AI than the transformers behind GPT and Claude - are running live at Shopify for search queries. CTO Parakhin calls them "the only non-transformer architecture I've found genuinely competitive."
RuView (49.4K GitHub stars, 551 stars today) uses WiFi signal disturbances to detect human poses, vital signs, and activity through walls - using $9 ESP32 hardware and no cameras. Privacy-first sensing that feels like science fiction.
The highest-voted post of the day across all AI subreddits is a community open letter to Anthropic, reflecting mounting frustration over pricing confusion, organization bans, and communication breakdowns. A separate post - "PSA: Anthropic bans organizations without warning" - hit 1,124 upvotes. Combined with Simon Willison's critique of the Claude Code pricing snafu, this represents a significant trust crisis for Anthropic in the developer community.
A popular r/ClaudeAI post (228 upvotes) asks why there's no $50/month Claude tier between the $20 Pro and $100 Max plans. The gap forces users to either accept Pro's limits or pay 5x more - with nothing in between for power users who need more than Pro but don't need enterprise features.
What started as a niche power-user trick for Claude Code has become a mainstream developer practice, with Alpha Signal writing tutorials and Karpathy's endorsement driving 100K+ bookmarks. Project-specific AI instructions are becoming as standard as .gitignore files.
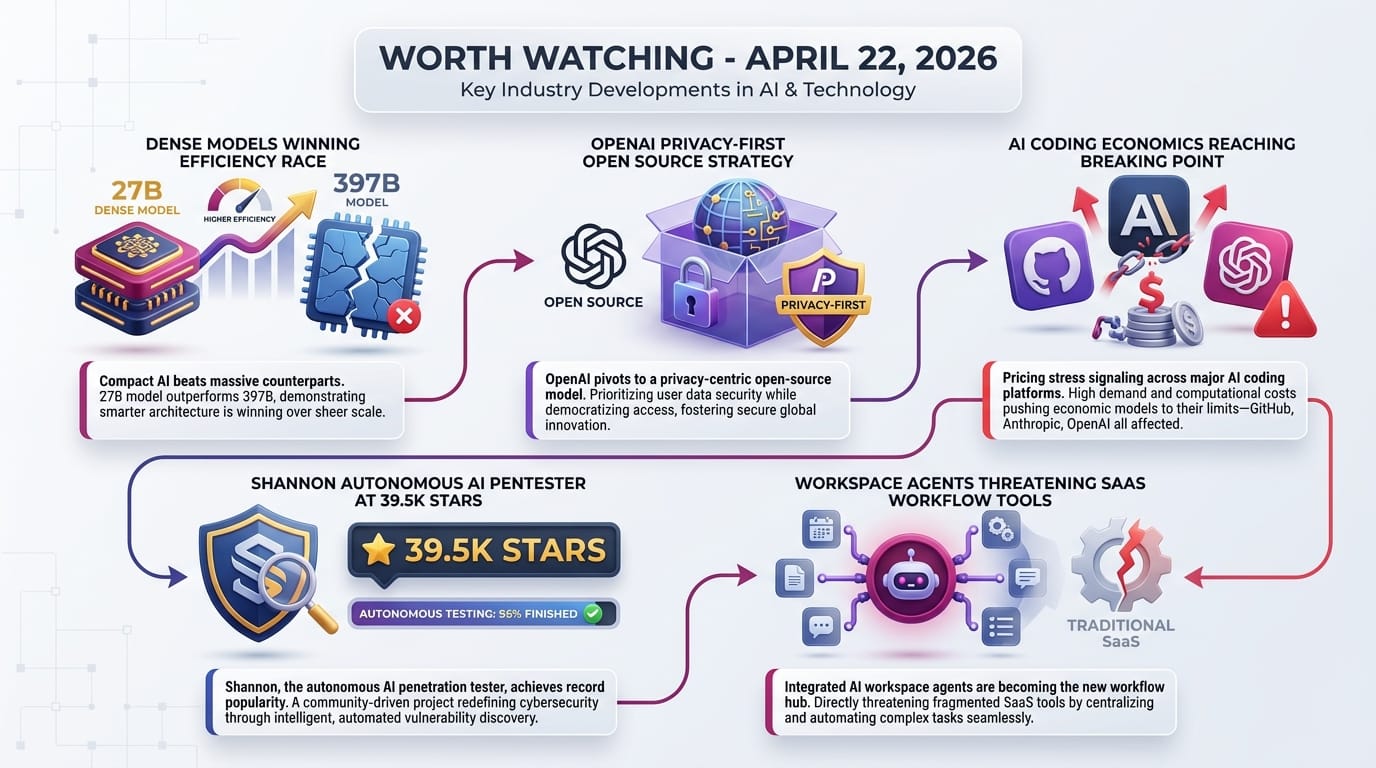
Qwen3.6-27B beating the 397B model isn't an anomaly - it's a trend. Dense architectures with better training data and techniques are closing the gap with massive mixture-of-experts models. If this continues, the compute requirements for frontier-quality AI could drop by an order of magnitude within a year. For ordinary people, this means AI tools that today require expensive cloud subscriptions could run on your phone.
The Privacy Filter release is philosophically unusual for OpenAI. By open-sourcing a tool that makes it easier to not send data to their servers, they're betting that removing friction around privacy will grow the overall market more than it cannibalizes their data advantage. Watch whether Anthropic and Google follow with competing privacy tools.
GitHub paused signups. Anthropic tested $100/month pricing. Opus 4.7's tokenizer quietly inflated costs. The pattern suggests the current model - cheap subscriptions subsidized by VC funding - is unsustainable for agentic workloads. Something has to give: either prices rise significantly, usage gets rationed, or a new pricing model emerges. This will reshape how developers choose and use AI tools in the coming months.
Shannon Lite (39.5K stars) is a fully autonomous AI pentester that analyzes source code, identifies attack vectors, and executes real exploits - no human guidance needed. Its "no exploit, no report" policy means it only flags vulnerabilities it can actually prove. If this approach scales, security testing could shift from expensive human consultants to automated, continuous scanning.
OpenAI's workspace agents let non-technical teams build and share AI-powered workflows by describing them in plain language. If these agents get good enough, the entire category of simple workflow automation tools faces disruption. The free preview period until May 6 will generate millions of test automations - watch which categories of paid tools see the fastest user migration.
📜 License: GPL-3.0 · 👤 By: Individual developer
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Covers 11+ platforms with unified dashboard | Primarily focused on Chinese platforms |
| AI filtering removes irrelevant noise | Requires Docker or self-hosting |
| Nine notification channel options | Configuration can be complex for beginners |

📜 License: MIT · 👤 By: Zilliz (company)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 40% token reduction for large codebases | Requires Zilliz Cloud or Milvus setup |
| Incremental Merkle tree indexing | OpenAI API key needed for embeddings |
| Works with Claude Code, Cursor, Cline | New project with rapidly evolving API |
📜 License: MIT · 👤 By: Academic (HKU)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Handles tables, equations, images natively | Resource-intensive for large document sets |
| Multiple parser options (MinerU, Docling) | Academic project - production readiness varies |
| Knowledge graph construction built-in | Setup requires multiple dependencies |

📜 License: Not specified · 👤 By: Company
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Free alternative to expensive terminals | Less data coverage than Bloomberg |
| Modern interface and analytics | License terms unclear |
| Active development with strong momentum | Python-based, requires installation |
📜 License: MIT · 👤 By: Community project
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| No cameras - pure radio signal sensing | Accuracy varies by environment |
| $9 hardware per sensor | Requires training period for new spaces |
| Through-wall detection capability | Complex calibration for multi-person |

📜 License: AGPL-3.0 · 👤 By: Company (Keygraph)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Autonomous end-to-end pentesting | AGPL license limits commercial use |
| Working PoC exploits, not just alerts | Requires Claude API access |
| Covers OWASP top vulnerabilities | Lite version has limited scope vs Pro |
📜 License: Apache 2.0 · 👤 By: AIDC-AI (organization)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| End-to-end video from one prompt | Quality varies by topic complexity |
| Multiple LLM and image model support | Requires Graphics Processing Unit (GPU) for local generation |
| Digital human avatars included | Chinese documentation primarily |
📜 License: Apache 2.0 · 👤 By: Company
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Unified catalog for all data assets | Enterprise-scale setup complexity |
| Built-in data quality monitoring | Requires dedicated infrastructure |
| Active community and regular updates | Learning curve for full feature set |

👤 By: Alibaba/Qwen · 🎯 Task: Image-Text-to-Text
📐 Size: 36B (3B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Only 3B active params per query | Mixture of Experts (MoE) architecture can be unpredictable |
| Multimodal (text + vision) | Requires scaffold for best results |
| Apache 2.0, no restrictions | Large total download size |

👤 By: Moonshot AI · 🎯 Task: Image-Text-to-Text
📐 Size: 1.1T
| ✓ Pros | ✗ Cons |
|---|---|
| Matches frontier models on coding | 1.1T parameters requires serious hardware |
| $0.60/M tokens via API | Newer model with less ecosystem support |
| Open weights for research | Chinese company - data residency concerns |

👤 By: Unsloth (community) · 🎯 Task: Image-Text-to-Text
📐 Size: 35B
| ✓ Pros | ✗ Cons |
|---|---|
| 1.11M downloads - battle-tested | Quantization reduces quality slightly |
| Multiple quant levels available | Requires llama.cpp knowledge |
| Runs on consumer GPUs | Large download even when quantized |

👤 By: Tencent · 🎯 Task: Image-to-3D
📐 Size: ~1.2B
| ✓ Pros | ✗ Cons |
|---|---|
| Real 3D assets, not just video | Early stage - quality varies |
| Direct export to game engines | Requires significant GPU power |
| Open-sourced with full pipeline | Complex multi-stage setup |

👤 By: Alibaba/Qwen · 🎯 Task: Image-Text-to-Text
📐 Size: 28B
| ✓ Pros | ✗ Cons |
|---|---|
| Beats 397B model on coding | Just released - ecosystem still forming |
| 262K native context window | 55.6GB unquantized |
| Vision + text + video | Dense model uses more compute than MoE |

👤 By: OpenAI · 🎯 Task: Token Classification
📐 Size: 1B
| ✓ Pros | ✗ Cons |
|---|---|
| 96% F1 accuracy out of the box | Only 8 PII categories currently |
| Runs in browser - no server needed | "Redaction aid, not safety guarantee" |
| Apache 2.0, fully open | Brand new - just 3 downloads so far |

👤 By: Zhipu AI · 🎯 Task: Text Generation
📐 Size: 754B
| ✓ Pros | ✗ Cons |
|---|---|
| 754B parameters - frontier scale | Requires enterprise-grade hardware |
| 171K downloads show real adoption | Limited English documentation |
| Open weights for research | Chinese-primary training data |

👤 By: Community · 🎯 Task: Text Generation
📐 Size: 8B
| ✓ Pros | ✗ Cons |
|---|---|
| Unrestricted outputs for research | No safety guardrails whatsoever |
| Small 8B size, runs anywhere | Gemma license restrictions apply |
| 79K downloads - community vetted | Not suitable for production deployment |

💰 Pricing: Not specified · 🏷 Category: AI Wearables

💰 Pricing: Included with ChatGPT Plus · 🏷 Category: AI Generative Media

💰 Pricing: Open source · 🏷 Category: Developer Tools

💰 Pricing: Not specified · 🏷 Category: AI Workflow Automation
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Opus 4.7 | $5.00 | $25.00 | 200K |
| Anthropic | Sonnet 4.6 | $3.00 | $15.00 | 200K |
| Anthropic | Haiku 4.5 | $1.00 | $5.00 | 200K |
| Gemini 3.1 Pro | $2.00 | $12.00 | 200K | |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M | |
| OpenAI | GPT-5.4 | $2.50 | $15.00 | 200K |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128K |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | 128K |
| Moonshot | Kimi K2.6 | $0.60 | $0.60 | 256K |
Key finding: Eliminates the router network entirely while matching or exceeding standard routing performance - removing a key source of training instability in MoE architectures.
Why practitioners should care: MoE models like Qwen3.6-35B-A3B are becoming the default architecture for efficient AI. Removing the router network simplifies training, reduces parameters, and could make these models even cheaper to develop and deploy.