Watch today's digest as a video summary (generated by NotebookLM)
OpenAI announced the OpenAI Deployment Company (DeployCo) with over $4 billion in initial investment at a $10 billion pre-money valuation, with OpenAI retaining majority control. The venture partners with 19 global firms including Bain, Capgemini, McKinsey, TPG, and Brookfield.
The subtext is striking: the company behind ChatGPT is essentially admitting that making AI easy to use isn't enough. Someone has to show up in person.
- DeployCo embeds "Forward Deployed Engineers" - specialists who sit inside client organizations to build custom AI workflows, similar to Palantir's model
- The timing is telling - only 14% of enterprises deploying AI have a clear strategy, according to McKinsey's latest survey
- OpenAI retains majority control - ensuring DeployCo stays aligned with OpenAI's product roadmap rather than becoming vendor-neutral
Google's Threat Intelligence Group identified what appears to be the first known zero-day exploit developed with AI assistance. The attack targeted a popular open-source web administration platform and bypassed two-factor authentication.
- Researchers spotted AI fingerprints - educational docstrings, a hallucinated CVSS severity score, and clean textbook-style Python formatting characteristic of LLM output
- The exploit was functional - this wasn't a proof of concept but a working attack used in the wild
- Cybersecurity experts had predicted this milestone - but its arrival means the theoretical threat is now a practical reality
OpenAI's Q1 2026 Signals report reveals ChatGPT grew from 400 million to 900 million weekly active users in 12 months - a 125% year-over-year increase at a scale where most consumer products plateau.
- Growth broadened across demographics - no longer skewing young and male, with rising adoption among users with typically feminine names and older age groups
- The fastest-growing use cases shifted from coding to everyday tasks - writing, research, shopping, and planning
- Enterprise adoption deepened - organizations moved from pilot projects to company-wide deployment
Software engineer James Shore, highlighted by Simon Willison, laid out a mathematical argument that AI-assisted coding can be a net negative over a system's lifecycle. The core logic: if an LLM doubles code output but also doubles maintenance costs, total lifetime costs quadruple.
- The math only works if AI tools decrease maintenance costs by exactly the inverse of the rate they add code - a condition rarely met in practice
- A threefold productivity boost requires maintenance costs to drop by two-thirds just to break even over the long term
- SlopCodeBench - a new benchmark released this week - found that coding agents' output becomes 2.3x more verbose over long sessions, with only 14.8% checkpoint success rates for the top agent
PowerColor launched the Radeon AI PRO R9600D, a single-slot passive GPU with 32GB GDDR6 memory aimed squarely at local LLM inference. Based on AMD's RDNA 4 architecture, it draws just 75 watts and requires zero fans.
- 32GB on a single slot with passive cooling - fits in compact builds and produces no noise, ideal for 24/7 inference servers
- 640 GB/s memory bandwidth on a 256-bit bus - competitive with much more expensive professional cards
- Runs 35B-parameter models comfortably - Qwen 3.6 35B-A3B at useful speeds, covering the sweet spot for local coding and chat assistants
- Price not yet announced - but AMD consumer cards have historically undercut NVIDIA by 30-40%

What it lets you do: Have a natural voice conversation with an AI that can switch between speaking, role-playing characters, and actually singing - all in one model.
- First end-to-end spoken language model supporting conversation, role-playing, and singing generation
- Uses multi-codebook audio tokens for richer expression beyond flat text-to-speech
- Composable voice presets allow mixing emotional styles and singing techniques
What it lets you do: Generate longer AI videos where characters, objects, and scenes stay consistent from beginning to end - the biggest weakness of current video AI.
- Closed-loop Retrieve-Synthesize-Refine-Update cycle operating segment-by-segment
- Multimodal Video Memory tracks visual and narrative consistency across segments
- Addresses the core problem of current AI video: characters changing appearance mid-scene
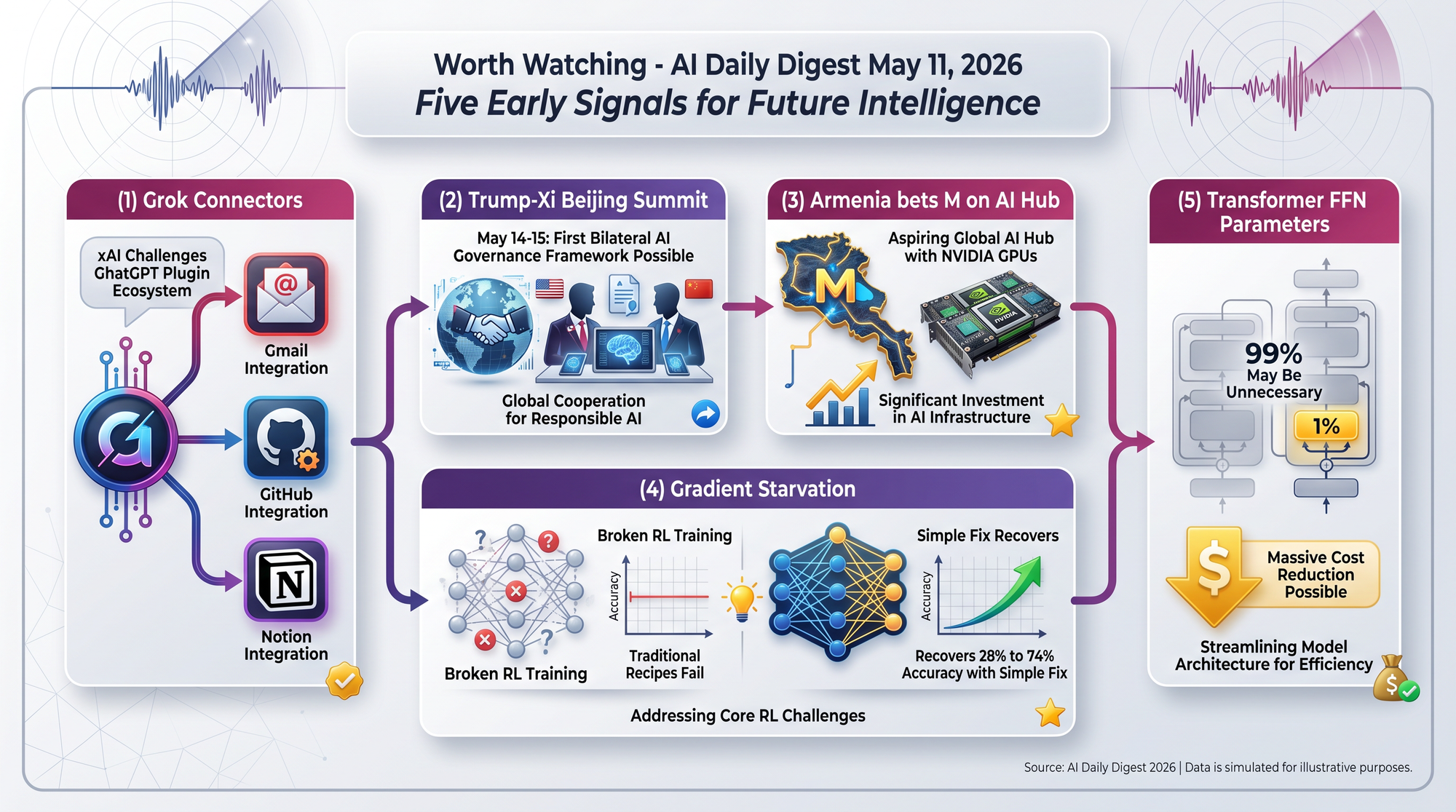
Grok Connectors launched on Product Hunt, connecting Grok to Gmail, Notion, GitHub, Linear, and Google Workspace with support for custom MCP servers. This transforms Grok from a standalone chatbot into a workspace integration layer. If Grok's smaller but growing user base adopts this, it creates a third major AI assistant ecosystem alongside OpenAI and Anthropic.
The Trump-Xi meeting scheduled for May 14-15 confronts a closing AI capability gap - Stanford's annual report says US and Chinese model performance is now effectively equal. The US has accused China of "industrial-scale" theft of AI models, while Beijing blocked Meta's acquisition of a Chinese AI lab. Whether this produces cooperation or escalation will shape AI development rules for years.
Armenia's ICT exports already hit $1.18 billion in 2024 (roughly 20% of services exports). The new investment targets Dell PowerEdge servers and NVIDIA Blackwell GPUs, with a scaled vision of $4 billion and 50,000 GPUs. If successful, it demonstrates that AI infrastructure isn't limited to tech superpowers.
Researchers discovered that binary rewards in Group Relative Policy Optimization cause gradient starvation - the model stops learning because gradients collapse. A simple fix (Sign advantage) recovers from 28.4% to 73.8% on GSM8K. Anyone training models with GRPO and binary rewards should check whether this affects their setup.
If this finding holds at scale, it implies dramatic cost reductions are possible through better architecture rather than better hardware. The immediate practical application is inference-time pruning for deployment on resource-constrained devices.
📜 License: Apache 2.0 · 👤 By: ByteDance (company)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Full GUI automation with screenshot-based reasoning | Heavy download; relies on large vision-language models |
| Apache 2.0 license, backed by ByteDance engineering | Privacy concerns - screenshots are processed by the model |
| MCP server integration for real-world tool connections | Still v0.3.0; breaking changes likely |
📜 License: MIT · 👤 By: Individual developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Smart 3-tier fallback keeps coding sessions uninterrupted | Routing through third-party free tiers raises data privacy questions |
| 20-40% token compression reduces costs | Quality may vary across provider fallbacks |
| Works with every major AI coding tool | Individual maintainer; bus-factor risk |
📜 License: GPL-3.0 · 👤 By: Individual developer
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 118+ integrations with local-only data storage | GPL-3.0 limits commercial embedding |
| Desktop mascot with voice adds a personal-assistant feel | Very early (1.4K stars); ecosystem still forming |
| Auto-fetch sync keeps context fresh across services | Rust build chain may challenge non-technical users |
📜 License: Not specified · 👤 By: Shanghai Jiao Tong University (academic)
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| University-quality curriculum covering 11+ advanced topics | Primarily in Chinese; English learners need translation |
| Runnable notebooks - learn by doing, not just reading | No formal license specified |
| Covers cutting-edge topics (agent safety, watermarking) | Assumes baseline ML and PyTorch familiarity |
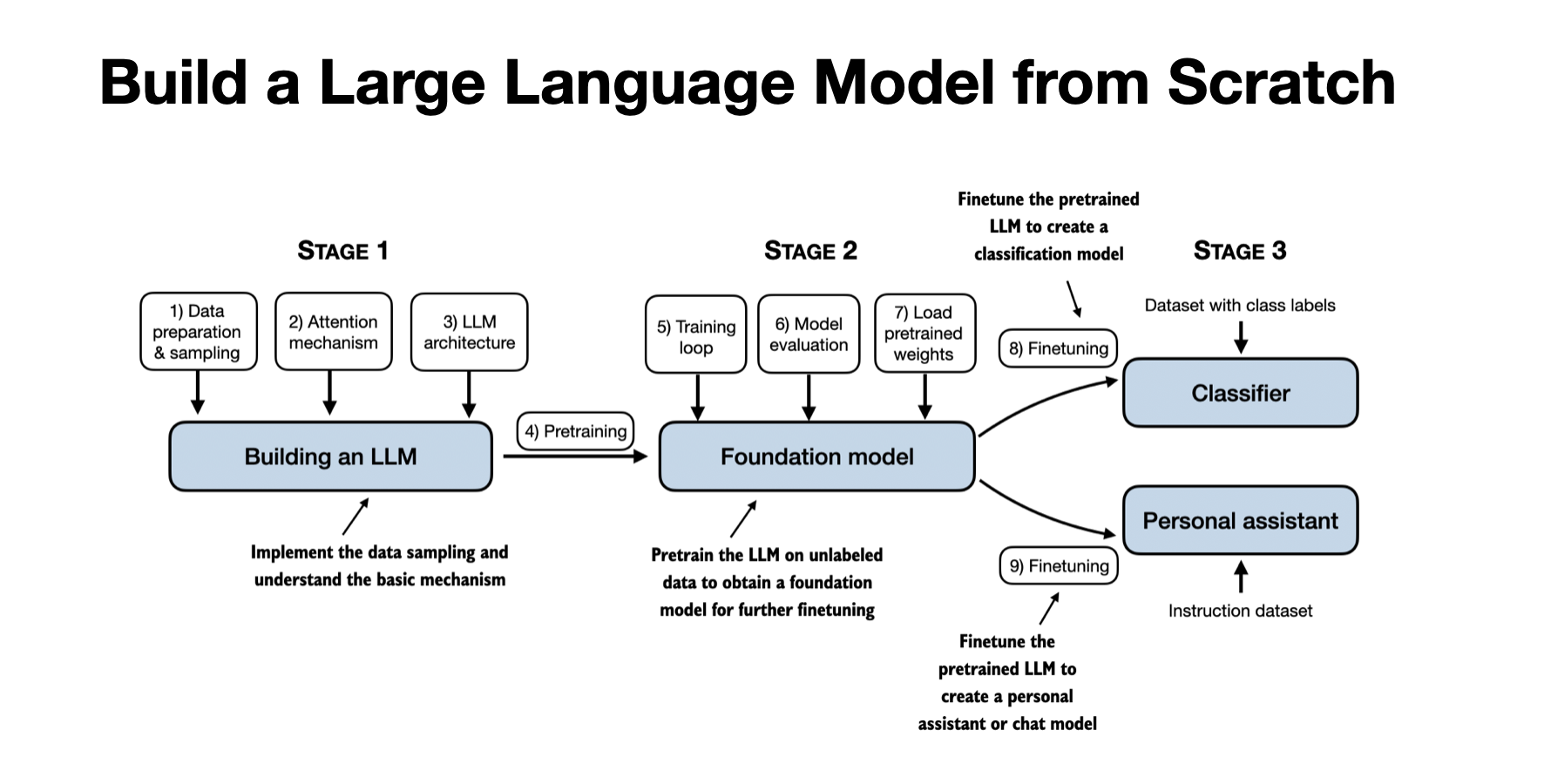
📜 License: Custom (book companion) · 👤 By: Sebastian Raschka (individual / author)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 93K stars; battle-tested by a massive community | Companion to a paid book (repo alone misses narrative) |
| Runs on CPU - no GPU required for core exercises | Teaches GPT architecture; less coverage of MoE or SSMs |
| Bonus chapters cover modern architectures (Llama, Qwen3, Gemma) | Not a quick tutorial; requires sustained time investment |
📜 License: MIT · 👤 By: Nous Research (research lab)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Self-improving skill system - gets better the more you use it | 145K-star project means rapid churn; keep up with releases |
| Multi-platform (terminal, Telegram, Discord, Slack, WhatsApp, Signal) | Learning loop quality depends heavily on the underlying model |
| MIT license; model-agnostic across 200+ providers | Complex setup if you want all integrations running |
📜 License: Apache 2.0 · 👤 By: Individual developer
🎯 Time to value: 8 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 95.2% retrieval accuracy (R@5) with hybrid search | Adds a background daemon and storage overhead |
| Zero manual effort - 12 automatic capture hooks | Individual maintainer; sustainability uncertain |
| Works across Claude Code, Cursor, Gemini CLI, and others | Knowledge graph indexing can be slow on large histories |
👤 By: OpenBMB · 🎯 Task: Image-Text-to-Text
📐 Size: 1B
| ✓ Pros | ✗ Cons |
|---|---|
| Runs on mobile CPUs with no cloud dependency | 1B param ceiling limits complex reasoning |
| Apache 2.0 with full deployment code open-sourced | Smaller context window than desktop models |
| Outperforms models 3x its size on vision-language benchmarks | Video understanding less tested than image |

👤 By: k2-fsa (Kounji Technologies) · 🎯 Task: Text-to-Speech
📐 Size: ~0.6B (Qwen3-0.6B base)
| ✓ Pros | ✗ Cons |
|---|---|
| 600+ languages in a single model - nothing else comes close | Quality varies across low-resource languages |
| 40x real-time inference speed | Voice cloning quality depends on reference audio length |
| Apache 2.0, pip-installable, GPU or CPU | 24kHz output (not studio-grade 48kHz) |

👤 By: Supertone Inc. · 🎯 Task: Text-to-Speech
📐 Size: 99M
| ✓ Pros | ✗ Cons |
|---|---|
| 99M params - fits in browser or embedded device | Fewer voices and less expressiveness than larger TTS |
| CPU-only, no GPU needed, ONNX portable | OpenRAIL-M license has use restrictions vs Apache 2.0 |
| Expression tags add natural breathing and laughter | 31 languages is strong but far behind OmniVoice's 600+ |

👤 By: SenseNova (SenseTime) · 🎯 Task: Any-to-Any
📐 Size: ~18B total (8B understanding + 8B generation)
| ✓ Pros | ✗ Cons |
|---|---|
| Unified understand + generate in one model (no VAE/VE) | 18B total params need decent GPU for inference |
| Native interleaved image-text generation | Generation quality trails dedicated diffusion models |
| Apache 2.0 with production inference stack (LightLLM) | Relatively new - community tooling still thin |

👤 By: HiDream.ai · 🎯 Task: Image-Text-to-Image
📐 Size: 8B
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license - maximally permissive for commercial use | 8B params need GPU; no CPU-only path |
| Best-in-class text rendering in generated images | 50-step inference is slow without distilled variant |
| Five distinct image tasks in one model checkpoint | Smaller community than FLUX/SD ecosystem |

👤 By: Moonshot AI · 🎯 Task: Multimodal Agentic
📐 Size: 1T total / 32B active
| ✓ Pros | ✗ Cons |
|---|---|
| 1T params with only 32B active - efficient MoE design | Massive download; needs multi-GPU for full precision |
| 80.2% SWE-bench, 96.4% AIME 2026 | Modified MIT license adds some restrictions |
| Proven 300+ agent swarm orchestration | Less battle-tested than DeepSeek V4 in production |

👤 By: DeepSeek-AI · 🎯 Task: Text Generation
📐 Size: 1.6T total / 49B active (862B safetensors)
| ✓ Pros | ✗ Cons |
|---|---|
| MIT-licensed 1M-token context - best open-source reasoning | 862B download; serious hardware required |
| 90% KV cache reduction vs V3.2 | Community quantizations still catching up |
| Top coding benchmarks (Codeforces 3206, SWE-bench 80.6%) | Has trended for 6+ days - no longer fresh news |

💰 Pricing: Freemium ($12-15/mo Pro) · 🏷 Category: AI Dictation
💰 Pricing: Freemium · 🏷 Category: AI Networking
💰 Pricing: Freemium (free trial + sales) · 🏷 Category: AI Code Review
💰 Pricing: Free trial · 🏷 Category: AI Recruiting
💰 Pricing: Freemium · 🏷 Category: AI Product Design
| Provider | Model | Input $/1M | Output $/1M | Context | vs Yesterday |
|---|---|---|---|---|---|
| Anthropic | Claude Opus 4.7 | $5.00 | $25.00 | 1M | -- |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M | -- |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K | -- |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | 1M | -- |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 1M | -- |
| OpenAI | o4-mini | $1.10 | $4.40 | 200K | -- |
| OpenAI | GPT-4.1 Mini | $0.40 | $1.60 | 1M | -- |
| Gemini 3.1 Pro | $2.00 | $12.00 | 200K | -- | |
| Gemini 2.5 Pro | $1.25 | $10.00 | 200K | -- | |
| Gemini 2.5 Flash | $0.30 | $2.50 | N/A | -- | |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | N/A | -- | |
| Groq | Llama 3.3 70B Versatile | $0.59 | $0.79 | 128K | -- |
| Groq | Qwen3 32B | $0.29 | $0.59 | 131K | -- |
| Groq | GPT OSS 120B 128k | $0.15 | $0.60 | 128K | -- |
| Groq | Llama 4 Scout 17Bx16E | $0.11 | $0.34 | 128K | -- |
What this means: At the flagship tier, Anthropic and OpenAI are price-matched on input ($5/MTok) but OpenAI charges a 20% premium on output ($30 vs $25). Google undercuts both on its mid-tier workhorse Gemini 2.5 Pro at $1.25/$10, while Groq remains the clear cost leader for open-weight inference - Llama 4 Scout on Groq costs roughly 45x less per input token than Claude Opus 4.7 or GPT-5.5, making it the go-to for high-volume, latency-tolerant workloads.