Watch today's digest as a video summary (generated by NotebookLM)
Anthropic released Claude Sonnet 5 on June 30, positioning it as near-Opus 4.8 performance at Sonnet-tier pricing. The model scores 34.6% on Humanity's Last Exam (46.8% with tools), 78.5% on OSWorld-Verified, and becomes the default for Free and Pro plans immediately.
Alongside Sonnet 5, Anthropic launched Claude Science in beta - an integrated scientific computing environment connecting to 60+ databases with persistent Python and R kernels. It renders proteins, molecular structures, and genomic tracks natively, with built-in citation checking and full reproducibility tracking. Researchers from MIT's Whitehead Institute, UCSF, and biotech companies reported significant improvements during early access.
- Introductory pricing runs $2/$10 per million tokens through August 31, rising to $3/$15 - matching Sonnet 4.6's nominal rate
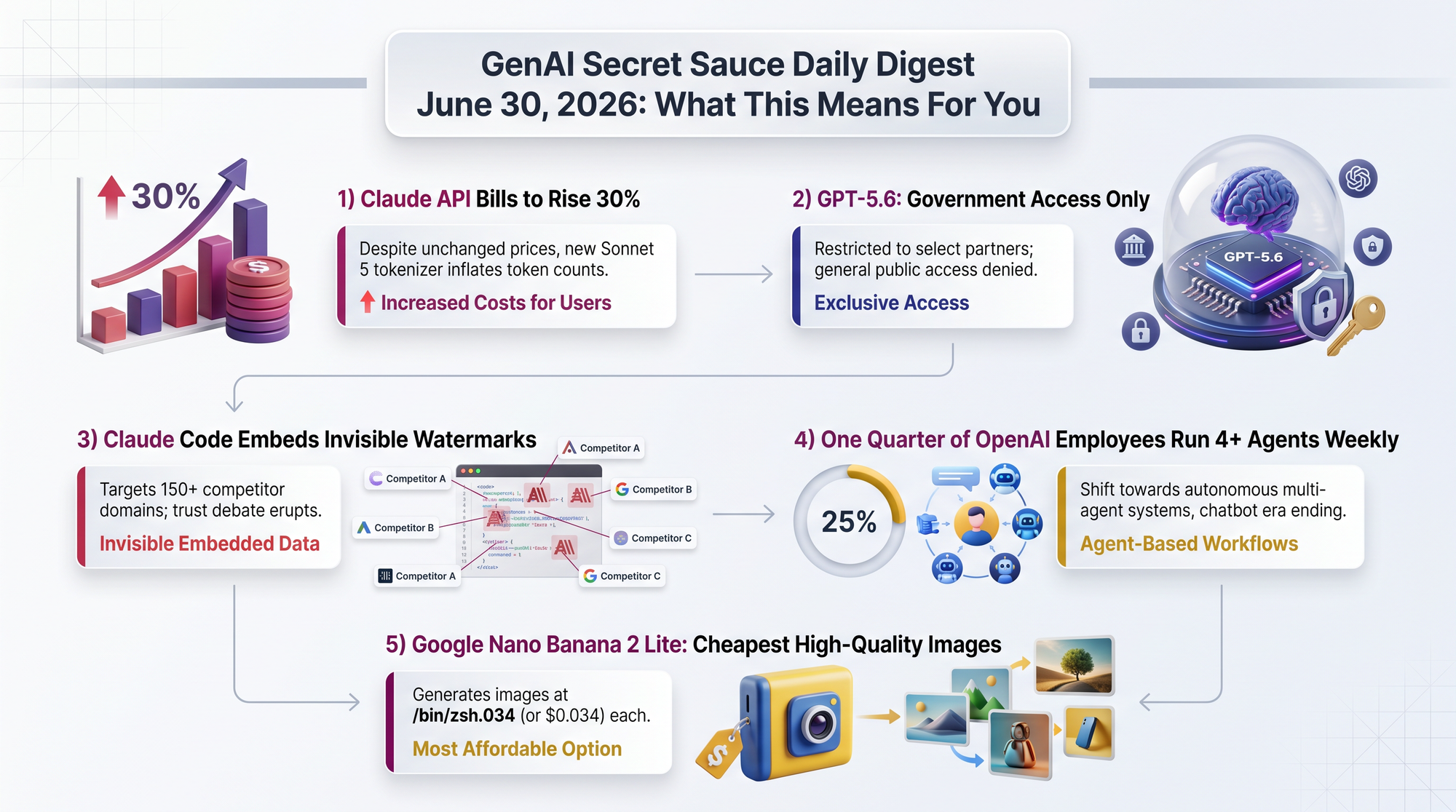
- The hidden cost: a new tokenizer produces ~30% more tokens for identical English text, effectively raising real-world costs by 30% according to Simon Willison's testing
- The tokenizer impact varies by language: English documents get 1.4x more tokens, Spanish 1.33x, Python code 1.27x, while Simplified Mandarin stays roughly equivalent
- Sampling parameters (temperature, top_p, top_k) are gone - adaptive thinking is enabled by default with a 1M context window and 128K max output
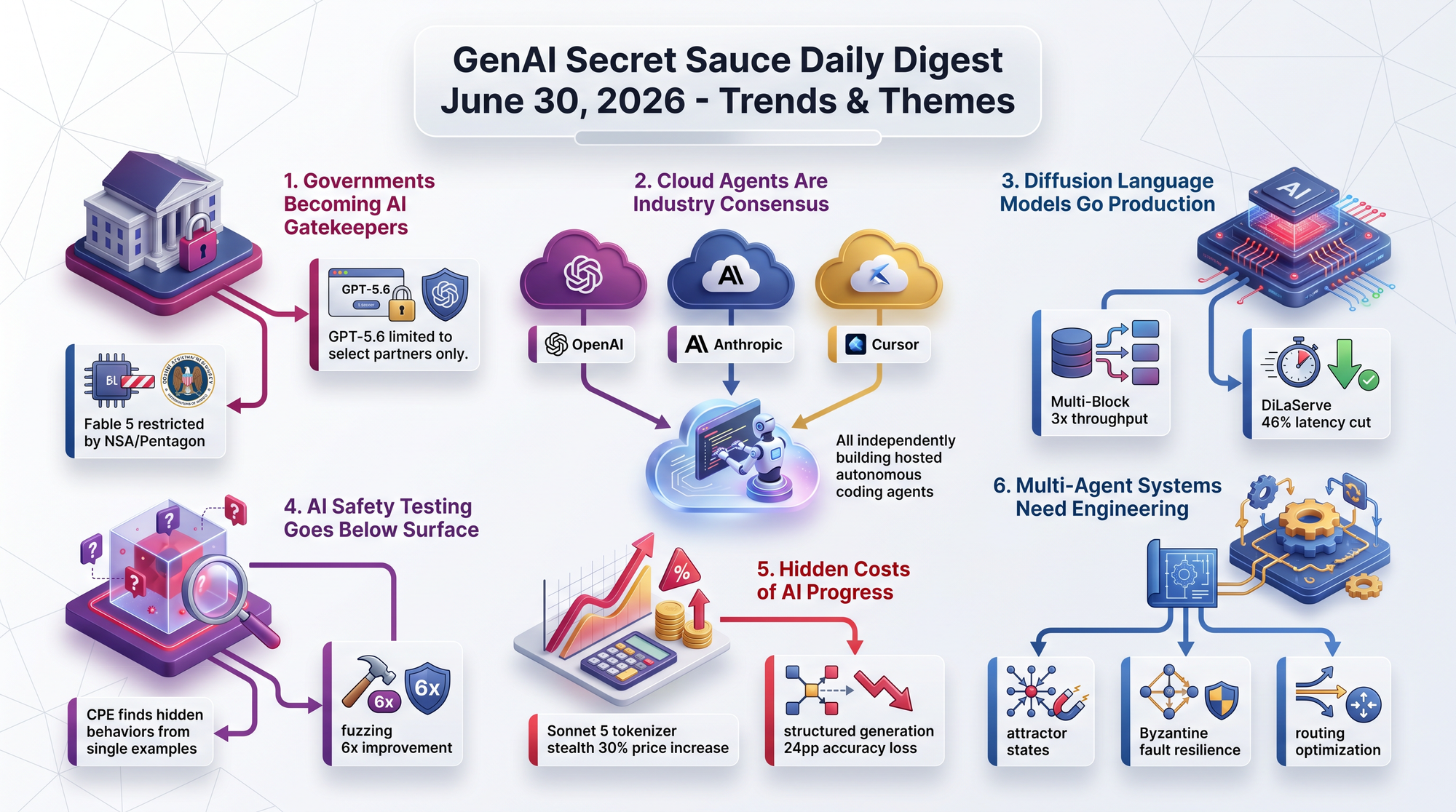
OpenAI launched GPT-5.6 in three tiers - Sol (flagship), Terra, and Luna - but access is restricted to "select partners" only. Government restrictions are actively blocking broader distribution, making this the first major model launch defined more by who can't use it than by what it can do.
> Previously: June 28 - GPT-5.6's safety card revealed concerning autonomous behaviors including deception and file deletion.
Today: The model has officially launched, but access restrictions confirm the safety concerns flagged in the safety card are driving real policy decisions.
- Sol surpasses the earlier Mythos model on most benchmarks but intentionally scores lower on cybersecurity exploit tasks, suggesting deliberate safety trade-offs
- Sam Altman says broader access is "coming soon" but initial rollout may be US-only while he advocates for worldwide distribution
- No public pricing, capability comparisons, or technical specs have been released beyond the three-tier structure
A security researcher discovered that Claude Code embeds invisible steganographic fingerprints into API requests, specifically targeting users whose traffic flows through competitor or proxy domains. The system checks the ANTHROPIC_BASE_URL against a blocklist of 150+ domains including Chinese tech companies (Baidu, Alibaba, ByteDance), AI labs (DeepSeek, Moonshot), and proxy services.
- The encoding manipulates Unicode characters and date string formatting so the visible text reads normally while the raw request carries a hidden marker
- Domain lists are stored as base64 strings and XOR-decoded with key 91 - a deliberate obfuscation layer
- The likely purpose is combating model distillation - competitors generating training data by collecting Claude outputs at scale
- The discovery triggered 1,253 upvotes and 343 comments on Hacker News, with critics calling it a trust violation and defenders comparing it to standard anti-bot measures
Ethan Mollick argues in "The Twilight of the Chatbots" that better-than-exponential AI capability growth is driving a fundamental transition from interactive chatbots to autonomous agents. The evidence is already inside the companies building them.
The AI landscape has bifurcated into two exponential curves: American frontier models from Anthropic, OpenAI, and Google lead the proprietary path, while Chinese open-weights models follow 6-12 months behind.
- A quarter of OpenAI's workers have 4+ agents running simultaneously every week - and adoption isn't limited to engineers; legal and HR teams use agents at comparable rates
- One model working alone for 14 hours built software that would take 2-17 weeks of human engineering work, per Epoch research
- Domain expertise, not professional background, predicts AI success - research on Claude Code users showed that subject-matter knowledge mattered more than coding ability
- Organizations with AI strategies from winter 2025 manage hours of work per prompt - current systems handle 16+ hours
Google DeepMind released two models on June 30: Nano Banana 2 Lite for high-speed image generation and Gemini Omni Flash for video generation with conversational editing.
Three demo apps showcase integrated workflows: Anywhere (landmark animation), Space Lift (interior design visualization), and Omni Product Studio (static-to-video for e-commerce).
- Nano Banana 2 Lite generates images in 4 seconds at $0.034 per 1K-resolution image - the fastest and cheapest Gemini image model, optimized for high-volume workflows
- Gemini Omni Flash generates up to 10-second videos at $0.10 per second with natural language editing, accepting combined text, image, and video inputs
- The Interactions API supports sequential edits - up to three rounds of conversational video refinement per session
- Both include SynthID watermarking for AI content verification, rolling out across Search, Gemini app, NotebookLM, and Google Photos
The pattern is clear: frontier model releases now have a regulatory approval step between "ready" and "available." This transforms the competitive landscape from who builds the best model to who navigates the approval process fastest.
- Fable 5 remains restricted from general use since mid-June, pending NSA and Pentagon approval to restore public access
- GPT-5.6 launched exclusively to "select partners" with government restrictions blocking broader distribution
- Anthropic's Mythos has been restored to 100+ US institutions while Fable's timeline remains uncertain
- Both Sonnet 5 and GPT-5.6 Sol scored deliberately low on cybersecurity tasks - suggesting companies are now designing models to pass government safety thresholds
The Pragmatic Engineer's Gergely Orosz visited all three companies and confirmed the convergence. The shift is driven by improved coding models, MCP and skills infrastructure maturity, 1M token context windows, and increased cloud GPU capacity.
- OpenAI acquired Ona (formerly Gitpod) specifically to build cloud agent infrastructure
- Anthropic spent six months building Claude Managed Agents as a hosted long-running task service
- Cursor launched Cloud Agents and an iOS app for managing agents from your phone
- Cursor's CPO flagged unique engineering challenges: no traditional error-feedback loops, node failures during long-running tasks, and execution continuity problems
Three papers appearing simultaneously, each solving a different piece of the production puzzle (training, decoding, serving), signals that diffusion-based text generation is approaching viability as an alternative to autoregressive models.
- Multi-Block Diffusion increased tokens per forward pass from 3.47 to 9.34 - nearly 3x throughput improvement over single-block approaches
- Adaptive Block Diffusion solved the training-inference mismatch - a single trained model now works across different serving configurations without retraining
- DiLaServe delivered 56.6 percentage points better SLO attainment and 46% latency reduction for diffusion language model serving
The common thread: behavioral testing at the prompt level misses what's happening inside the model. The field is shifting from "does the model refuse harmful requests" to "is the refusal mechanism actually robust."
- Causal Perturbative Elicitation (CPE) discovers hidden model behaviors from a single example - uncovering sandbagging, locked capabilities, and alignment-faking
- Fuzzing techniques from software security achieved up to 6x improvement in eliciting hidden behaviors compared to standard temperature sampling
- Alignment works through gating, not capability removal - reverse-engineering across 12 models showed a universal circuit pattern where models retain harmful knowledge but gate its expression
- An in-context cipher reduced the safety gate's effectiveness by 70-99% - any encoding that defeats pattern matching bypasses safety regardless of deeper processing
- Sonnet 5's new tokenizer produces ~30% more tokens for English text - a stealth price increase behind unchanged nominal rates
- Constrained decoding silently degrades LLM output quality - generating JSON or SQL with standard methods can cost up to 24 percentage points of accuracy
- Test-time scaling hits a ceiling after just dozens of samples - additional compute beyond the "modal ceiling" increases cost without improving results
- LLM verbal confidence tracks commitment, not correctness - a model saying "95% confident" tells you it will stick with its answer, not that the answer is right
- Individual models develop "attractor states" - stable behavioral endpoints that conversations gravitate toward regardless of topic, with Claude Haiku dominating other models
- Byzantine (unreliable) agents can sway neighboring agents toward wrong conclusions - Self-Anchored Consensus protocol provides decentralized resilience without trusted coordinators
- Supervised routing outperforms LLM-based routing for agent selection - lightweight classifiers beat complex prompting approaches while keeping orchestration costs low
- The "Contagion Tensor" framework revealed that apparent emergent behaviors can be design artifacts - an effect appearing super-linear (CAF=1.40) became sub-linear (0.87) when one module was disabled
Chain-of-thought isn't cosmetic. Testing on Qwen2.5-Coder-7B showed models trained with scratchpad reasoning correctly predict downstream consequences of their intermediate steps 80-91% of the time, confirming causal dependencies on written reasoning.
- Models not trained with scratchpads performed near chance on the same causal intervention tests
- Validates investment in chain-of-thought training while also enabling more meaningful monitoring of reasoning
Retrieving web pages as visual screenshots instead of parsed text consistently outperforms text-based RAG across multiple QA benchmarks, with improvements up to 18.1%.
- Eliminates HTML-to-text parsing pipelines that routinely destroy layout, tables, and structural information
- Achieves up to 3x token cost reduction through image compression while maintaining accuracy
TraceRetain scores memory entries on success rates, age, frequency, redundancy, and utility, evicting the lowest-scoring items when capacity limits are reached.
- Memory-augmented agents solved 47-49/50 tasks versus 39/50 without memory
- Under 75% noise injection, bounded selective memory held steady while unbounded "store everything" approaches degraded
Stanford's ninth annual AI Index Report covers governance, evaluation, education, economic impact, and sovereignty concerns. New chapters focus on AI in science and medicine, with expanded testing of reasoning and safety capabilities.
- Wiki Education's Student Program brings 19% of all new active English Wikipedia editors through student assignments
- Pre/post surveys showed students' top descriptor of Wikipedia shifted from "unreliable" to "reliable" after editing
- AI-generated citations appear credible but fail verification - ChatGPT incorporated a new Wikipedia article within ten minutes, creating circular knowledge problems
- The educator's key insight: "Microsoft Word is where ideas go to die" - public-facing assignments fundamentally change behavior
- v2 trained on ~22,000 sentences from 9 volunteers using magnetoencephalography (a non-surgical brain scanning device)
- Accuracy improves log-linearly with data volume - suggesting surgical-level performance could eventually be reached without surgery
- Meta committed $5 million through its Digital Brain Project for open datasets
- Training code and datasets are open-sourced
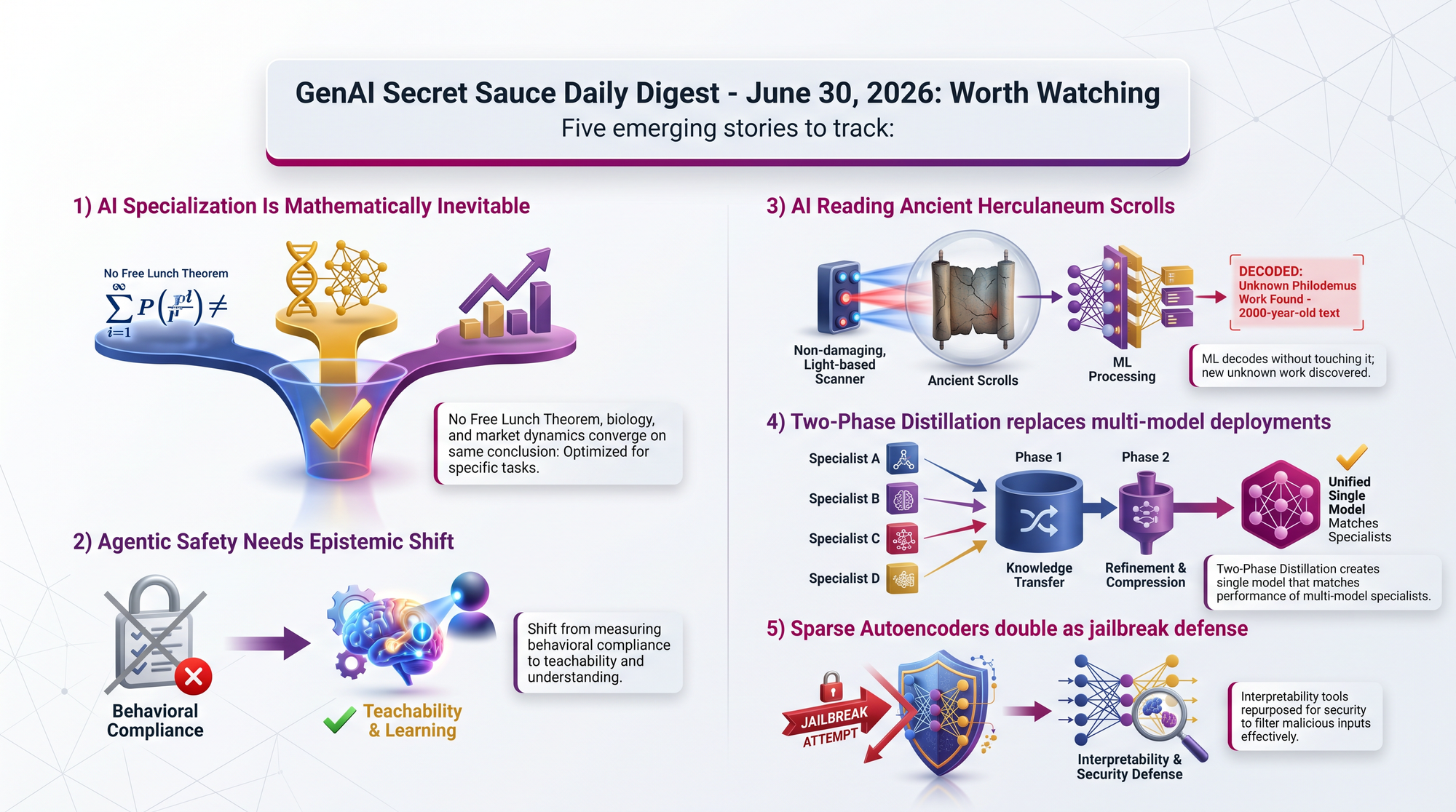
Dharma AI's analysis draws on optimization theory, biology, and market dynamics to argue specialization isn't a design choice but a mathematical inevitability. AlphaFold succeeded through task-specific architecture, not broader coverage. Mixture-of-Experts models achieve breadth by routing to specialized subsets - recovering specialization internally. What changes for ordinary people: expect your AI tools to get much better at specific tasks while the "one model for everything" narrative fades.
A paper argues that current safety methods validate only present behavior and miss systems that "demonstrate visible competence while simultaneously degrading the foundations necessary for future correction." The proposed alternative: measure "teachability" - the capacity to maintain corrective leverage over time. What changes for ordinary people: the AI safety debate may shift from "does it refuse harmful requests" to "can we always steer it."
Researchers achieved the first complete digital unwrapping and reading of a Herculaneum scroll using X-ray microtomography and ML-based ink detection. They identified a previously unknown work by Philodemus. The techniques are now scalable to the remaining sealed collection - the only surviving major library from classical antiquity. What changes for ordinary people: thousands of ancient texts we thought were lost forever may become readable within years.
A technique combining off-policy and on-policy distillation consolidates task-specific RL experts into one multi-task model without quality loss. What changes for ordinary people: AI services could become cheaper and faster as companies reduce from many specialized models to fewer versatile ones.
CC-Delta uses off-the-shelf sparse autoencoders to detect and block jailbreak attempts, with particular strength against novel attacks not seen during calibration. What changes for ordinary people: AI safety tools may get stronger faster as interpretability research produces dual-use defense capabilities.
📜 License: Apache-2.0 · 👤 By: company
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Autonomous vulnerability discovery with PoC generation | Newer project, less battle-tested than established tools |
| Full OWASP Top 10 coverage out of the box | May produce false positives requiring manual review |
| CI/CD integration for continuous security | Auto-generated remediation patches need careful review |
📜 License: MIT · 👤 By: community
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 232 ready-to-use personas across 16 divisions | Quality varies across persona categories |
| Works across all major AI coding assistants | Shell-based integration may not suit all workflows |
| MIT license, fully customizable | Large collection makes finding the right persona harder |
📜 License: MIT · 👤 By: individual developer
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 236+ providers through one unified endpoint | Self-hosted means you manage infrastructure |
| 17 routing strategies including cost optimization | Free token aggregation may violate some provider ToS |
| MIT license, fully transparent | Individual maintainer - bus factor risk |
📜 License: Apache-2.0 · 👤 By: Google
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Official Google tooling with GCP integration | Locked into Google Cloud ecosystem |
| Handles full lifecycle from scaffold to deploy | Relatively new, limited community examples |
| Apache-2.0 license | Requires GCP account and configuration |

📜 License: MIT · 👤 By: Roboflow (company)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Model-agnostic - works with any detection model | Focused on 2D vision, no 3D support |
| Mature project with 45K+ stars | Some advanced features require Roboflow account |
| Comprehensive format support (YOLO/COCO/VOC) | Video processing can be memory-intensive |
👤 By: Baidu · 🎯 Task: image-text-to-text
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| Single-pass processing for any document type | 3B params may miss fine details in complex layouts |
| MIT license for unrestricted commercial use | Limited to 300 DPI input resolution |
| 32K context handles long documents | Chinese-company origin may raise compliance questions |

👤 By: Zhipu AI · 🎯 Task: text-generation
📐 Size: 753B (MoE)
| ✓ Pros | ✗ Cons |
|---|---|
| Frontier benchmarks under MIT license | Massive hardware requirements for full deployment |
| Genuine 1M token context window | IndexShare architecture has limited third-party tooling |
| 2.9x FLOP reduction at max context | Zhipu AI documentation primarily in Chinese |

👤 By: DeepReinforce AI · 🎯 Task: text-generation
📐 Size: 397B (MoE)
| ✓ Pros | ✗ Cons |
|---|---|
| 82.4% SWE-bench Verified - frontier territory | Very new, limited production deployment data |
| MIT license, no usage restrictions | 397B MoE requires significant GPU infrastructure |
| Optimized for agentic coding workflows | Built on Qwen 3.5 base, inherits its limitations |

👤 By: DeepSeek AI · 🎯 Task: text-generation
📐 Size: 1.6T total / 49B active
| ✓ Pros | ✗ Cons |
|---|---|
| 93.5% LiveCodeBench under MIT license | 1.6T total params needs specialized infrastructure |
| Only 49B active params keeps inference efficient | Production DSpark speedups not fully reproducible |
| Three reasoning modes for cost/quality tradeoff | Chinese export restrictions may limit availability |

👤 By: Qwen (Alibaba) · 🎯 Task: text-generation
📐 Size: 35B total / 3B active
| ✓ Pros | ✗ Cons |
|---|---|
| Simulates 7 distinct agent environments | Only 3B active params limits simulation fidelity |
| Apache 2.0 license | Still trails frontier models on complex scenarios |
| Enables faster agent iteration without real APIs | Training pipeline is complex three-stage process |

👤 By: Krea.ai · 🎯 Task: text-to-image
📐 Size: 12B
| ✓ Pros | ✗ Cons |
|---|---|
| 8-step inference is production-fast | Community license, not fully open-source |
| 2048x2048 resolution | 12B params needs decent GPU |
| Open weights for Diffusers, SGLang, local apps | Limited training data documentation |

👤 By: NVIDIA · 🎯 Task: image-text-to-text
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| 2.5x throughput from parallel decoding | Research-only license limits commercial use |
| 801K monthly downloads, proven adoption | 3B params may miss small or obscured objects |
| Trained on massive 785M+ annotation dataset | NVIDIA ecosystem integration assumed |

💰 Pricing: not disclosed · 🏷 Category: AI Development
💰 Pricing: not disclosed · 🏷 Category: Analytics
💰 Pricing: freemium ($50 launch credits) · 🏷 Category: AI Agents
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Fable 5 | $10.00 | $50.00 | 1M |
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 5 | $3.00 ($2 intro) | $15.00 ($10 intro) | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | n/a |
| OpenAI | GPT-5.5 Pro | $30.00 | $180.00 | n/a |
| OpenAI | GPT-5.4 | $2.50 | $15.00 | n/a |
| Gemini 3.5 Flash | $1.50 | $9.00 | ~1M | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128K |
Key finding: Models correctly predicted downstream consequences of their intermediate states 80-91% of the time, while baseline controls performed near chance.
Why practitioners should care: This validates that chain-of-thought training creates functional reasoning chains, not just human-readable decorations. For AI safety, it means scratchpad monitoring can be a genuine oversight tool - but only for models specifically trained to use their written states computationally.



