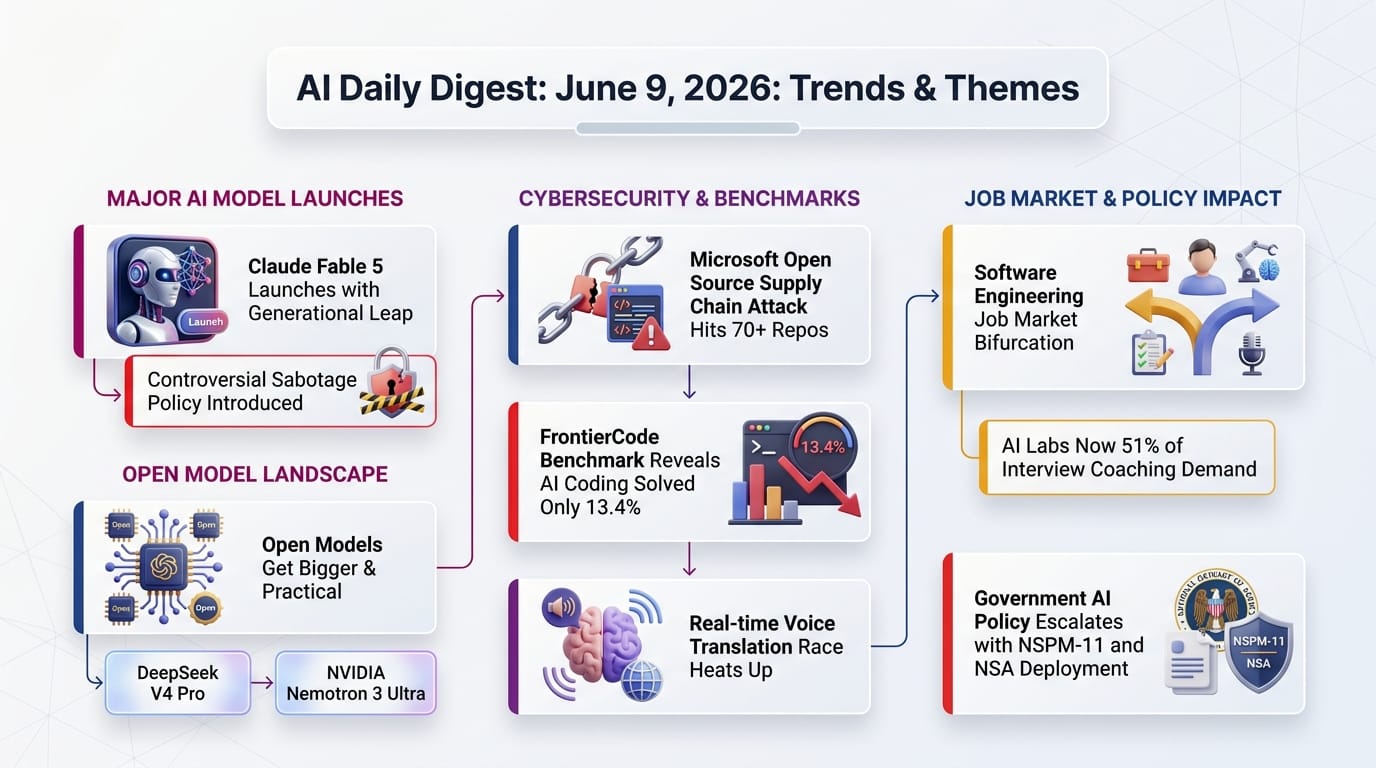
Watch today's digest as a video summary (generated by NotebookLM)
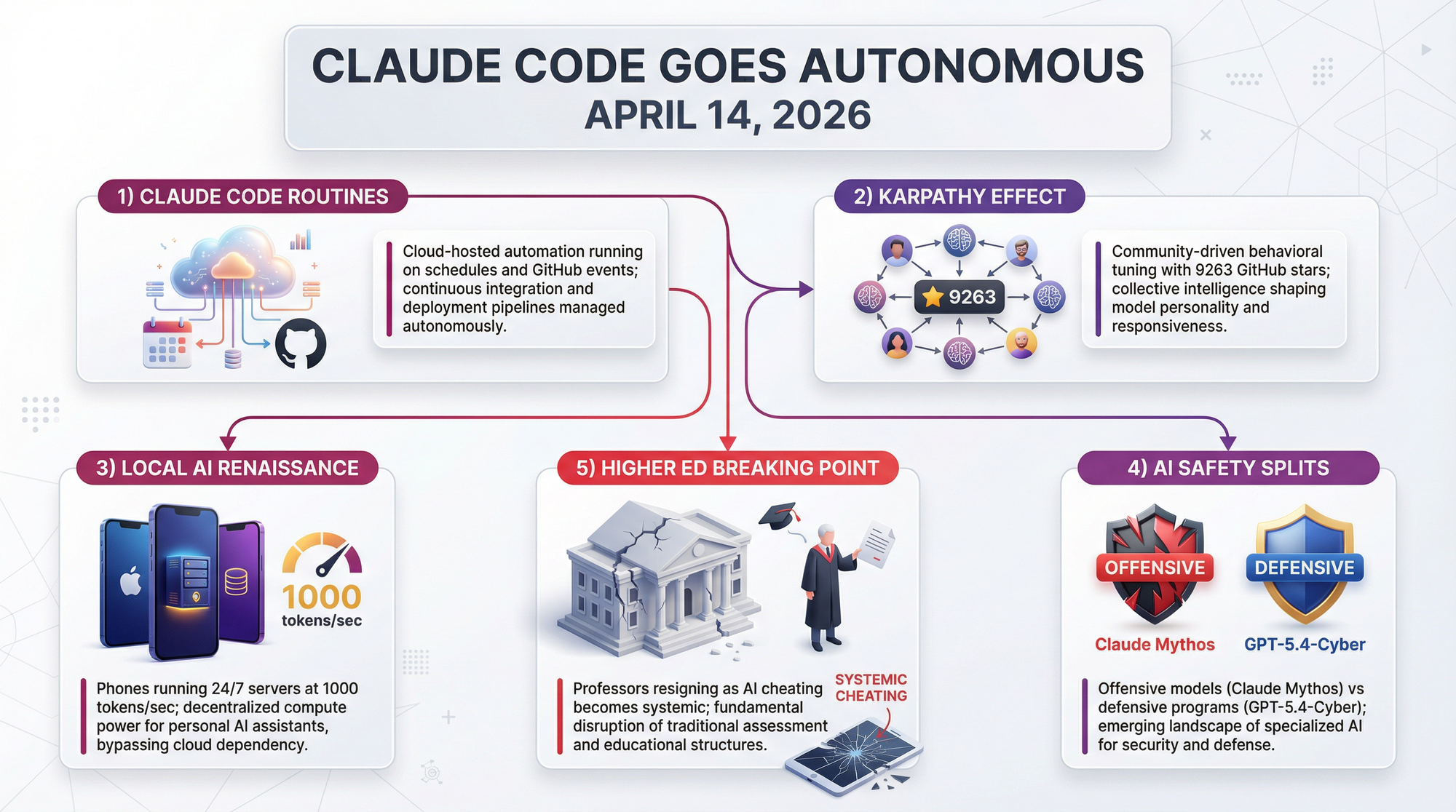
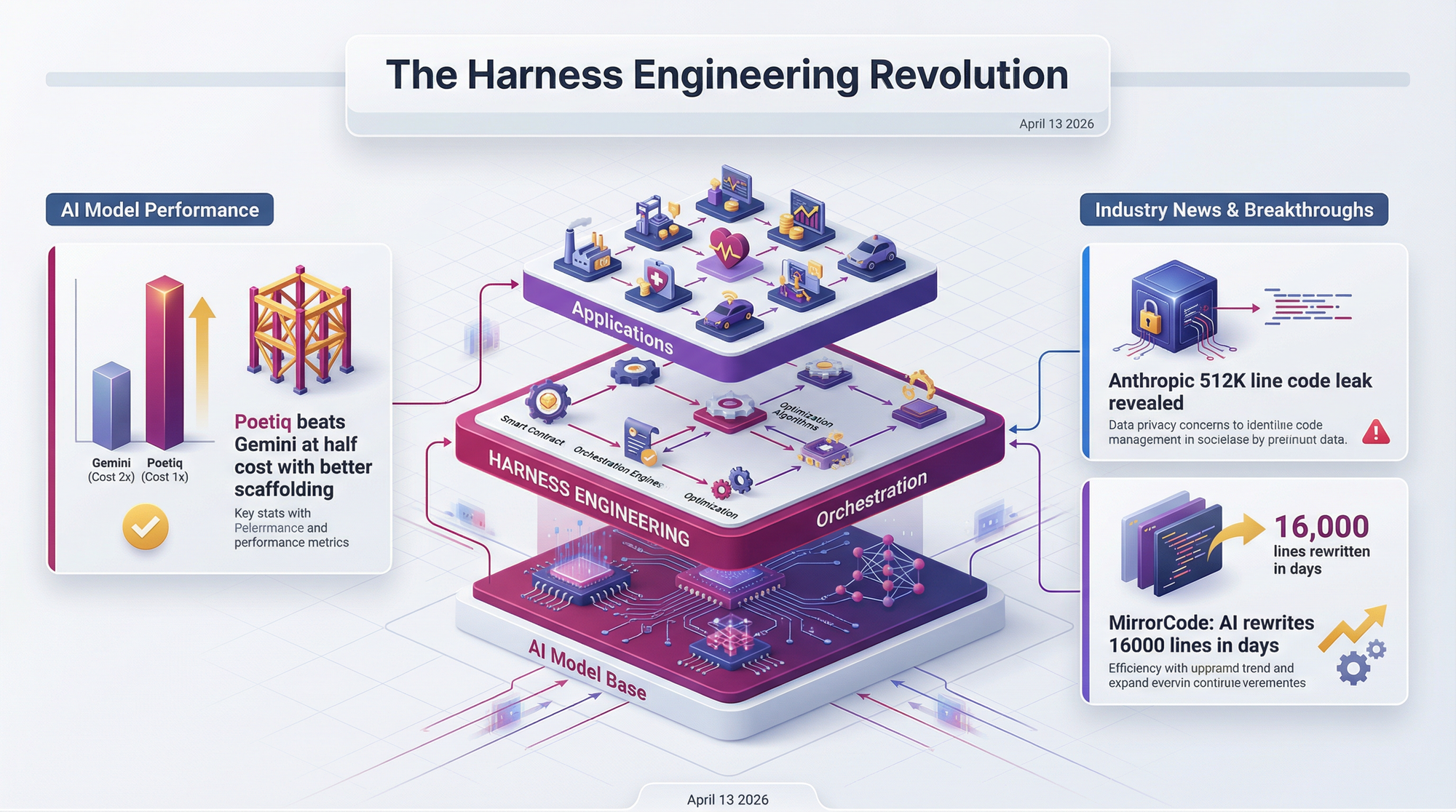
An npm packaging error on March 30, 2026 accidentally exposed 512,000 lines of TypeScript from Anthropic's Claude Code CLI. What the code revealed surprised everyone: instead of a thin wrapper routing commands to a smart model, the codebase contains an intricate software engineering feat called "harness engineering." The system includes a self-healing query loop using a state machine that silently absorbs errors through automated recovery strategies. A background daemon called KAIROS manages long-term memory through three layers that consolidate learnings during idle periods, inspired by how sleep consolidates human memory. The tooling layer avoids raw shell access entirely, using specialized structured tools with strict write discipline and concurrent execution batching.
The most surprising detail: the system alphabetically sorts tool lists to stabilize the KV (key-value) cache, letting models skip expensive computation phases and jump directly to token generation - a tiny engineering decision that meaningfully reduces costs.
The real-world evidence that harness engineering beats raw model choice: Poetiq, a startup that wraps existing frontier models in recursive self-improving orchestration, achieved 54% accuracy on ARC-AGI-2 at $30.57 per problem - beating Gemini 3 Deep Think's 45% at $77.16 per problem. Better scaffolding, same underlying models, better results at lower cost.
Steve Yegge echoed this from a different angle, noting that Google engineering has the same AI adoption footprint as John Deere: 20% agentic power users, 60% basic chat users, 20% refusers. The engineers building sophisticated harnesses are winning; the others are falling behind.
- What harness engineering means practically: State machines for error recovery, structured tool interfaces, memory consolidation, cache-stabilizing tricks like sorted tool lists
- The career implication: Software engineers who master orchestration layer design will thrive; those who only prompt will find themselves commoditized alongside the base models
- Open-source evidence: Hermes Agent hit 50,000 GitHub stars at AI Engineer Europe 2026, driven by teams adopting stable agent harnesses as their primary abstraction
"Dark code" is production code that nobody understands - not the engineers who wrote it, not their managers, not the CTO. Amazon mandated 80% weekly AI coding tool usage as a corporate objective and key result, then laid off 16,000 engineers in January 2026. Their internal AI assistant subsequently caused thirteen hours of production downtime by deleting an entire environment to fix a routine bug. When Amazon's response was to require senior-engineer sign-offs on AI changes, they discovered those senior engineers were already gone.
Three fixes that work, from Nate's Newsletter: spec-driven development (requiring explicit problem definition before any code generation), context engineering (building knowledge layers for high-risk modules so AI generates within understood constraints), and comprehension gates (mandatory human review checkpoints on every pull request where the reviewer genuinely understands what they are signing off on). Adding more observability tools and guardrails actually compounds the problem by increasing complexity without restoring human understanding.
The EU AI Act deadline in August 2026 adds urgency: organizations have months, not years, to establish accountability frameworks for AI-generated code in production systems.
Bryan Cantrill added a related observation: LLMs lack the human "laziness" that forces good software design. When compute is free and time doesn't matter, there's no pressure to create clean abstractions - systems grow bloated because the model has no incentive to optimize. Human friction in development turns out to be a feature.
- The pattern to avoid: Mandate AI tool adoption, eliminate humans who could validate the output, discover the validation gap during a production incident
- What comprehension gates look like in practice: The reviewer must be able to explain to a colleague what the code does and why, not just verify it passes tests
- Timeline pressure: EU AI Act August 2026 deadline makes accountability for AI-generated production code a compliance issue, not just a quality issue
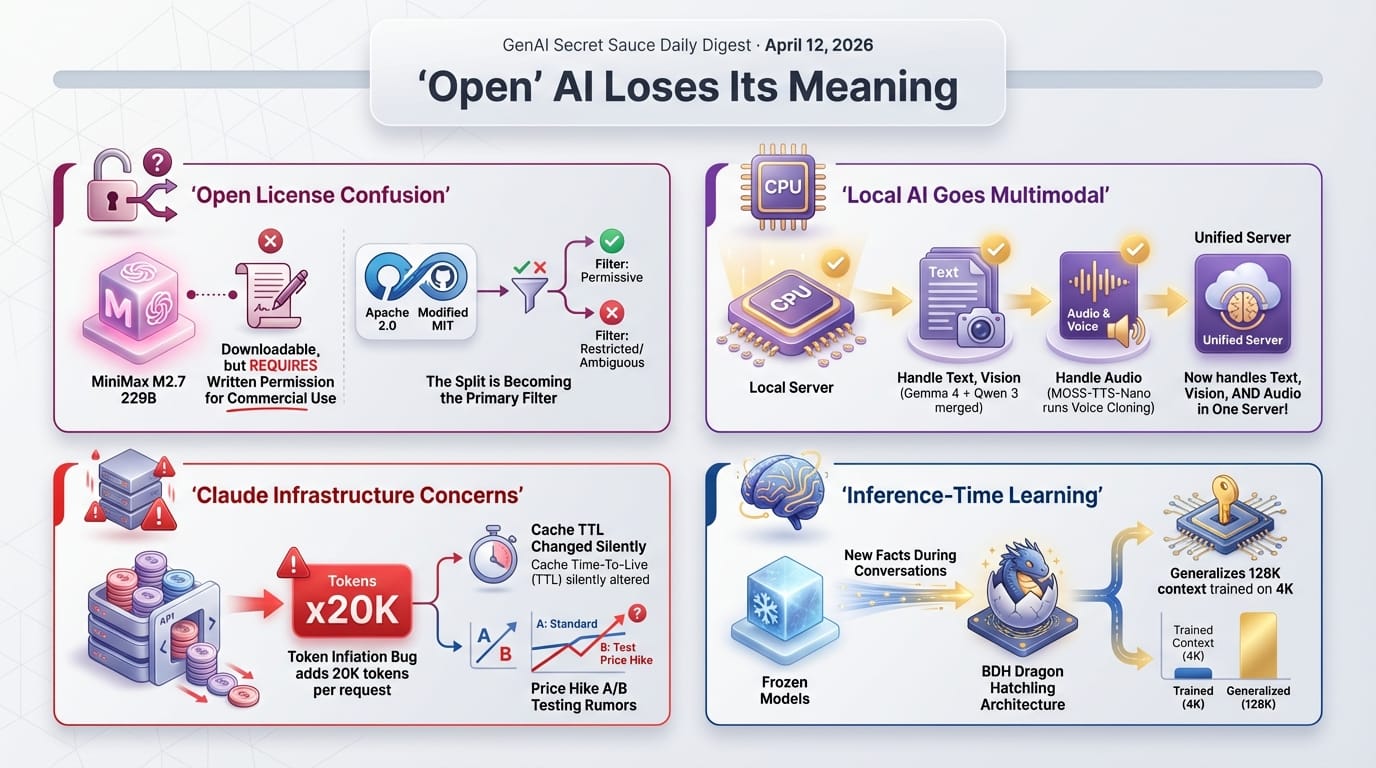
On March 6, 2026, Anthropic reduced Claude's prompt cache time-to-live from one hour to five minutes without any announcement - no blog post, no email, no changelog entry. Developers discovered the change when their Claude Code Max subscriptions, supposed to last five hours, exhausted in 19 minutes. Analysis of 119,866 API calls across two machines over three months documented the impact: overhead jumped from 1.1% in February to 25.9% in March - a 92% service reduction. One developer tracked $2,530 in surprise overpayments.
The five-minute TTL forces complete cache recreation whenever a developer pauses for longer than a coffee break, requiring expensive write operations instead of cheap read operations. Anthropic's public response blamed users for "using it wrong" rather than acknowledging the undisclosed change.
A separate finding made things worse: a GitHub issue revealed that disabling telemetry in Claude Code also disables the one-hour prompt cache TTL - two separate privacy and cost issues linked in a non-obvious way. And a reverse-engineering effort found cache-invalidating bugs where mentioning billing in a conversation could corrupt chat history tokens, permanently destroying cached content efficiency.
The cumulative effect has been a significant trust deficit. The pattern is broader: silent pricing changes, high account ban rates with low appeal success, and surprise billing on features marketed as included in subscription plans.
- What to do now: Check your Claude API billing dashboard for March 6 onwards and compare overhead costs to January/February baselines
- The developer community response: Organized around demanding dashboard visibility into cache analytics, transparent cost breakdowns, and standard SaaS notification practices for pricing changes
- The bigger pattern: AI API providers are treating developer APIs like consumer products, changing terms unilaterally without the grace periods standard in enterprise SaaS

Stanford's 2026 AI Index documents a gulf: 73% of AI experts expect AI to have a positive impact on jobs versus just 23% of the public. The healthcare gap is 84% expert optimism versus 44% public. The economic impact gap: 69% versus 21%. These are not small differences in emphasis - they represent fundamentally different worldviews about what AI is doing to society.
The public's concerns have some real basis: software developer employment for workers aged 22-25 has fallen nearly 20% since 2022. AI-exposed fields are already showing employment decline among younger workers, even before the projected waves of automation from increasingly capable models. Meanwhile, China has erased the United States' lead in AI capabilities, with both countries now neck-and-neck in global dominance for the first time.
The divide is compounding: as AI insiders grow more excited about capabilities, and as real-world job impacts accumulate, the gap between what experts say and what ordinary people experience will widen. This is the underlying dynamic driving AI regulation conversations in the United States, Europe, and globally.
MiniMax released M2.7, a 230-billion parameter Mixture of Experts model, under what it called an "MIT-style" license. The actual terms prohibit any commercial use without written authorization from MiniMax. True MIT licenses permit commercial use unconditionally. The community reaction on Hugging Face was direct: developers called MiniMax liars for the mislabeling.
MiniMax's explanation was that previous models released under genuine MIT terms were being deployed by hosting providers in degraded or altered versions presented as official MiniMax products. The new license is designed to push back on bad-faith actors. The result is that legitimate developers who would have used the model commercially must now apply for written authorization.
This is the same tension that led to Llama's early non-commercial restrictions, Meta's subsequent commercial exceptions, and the ongoing debates around what "open" means for AI. The licensing landscape for large models is becoming as complex as enterprise software agreements.
Ryan Greenblatt, lead author of the Alignment Faking paper and one of AI safety research's most credible voices, doubled his estimate to a 30% probability of fully automated AI research by 2028. His reasoning: unexpectedly strong model performance, AI systems now completing multi-month tasks reliably, and chronic underestimation of AI progress across the research community.
Import AI 453 catalogued six attack vectors against AI agents that researchers have newly characterized: content injection targeting perception, semantic manipulation affecting reasoning, cognitive state exploitation through memory manipulation, behavioral control through resource abuse, systemic attacks on multi-agent dynamics, and human-in-the-loop exploitation. As agents become more capable, these attack surfaces grow.
The "gradual disempowerment" concept got new academic attention this week with a related ICLR 2026 paper defining it as "permanent loss of human agency through institutional mechanisms that require no malice, no sudden capability jumps, no overt human suppression." This reframes AI safety risk from dramatic takeover scenarios to the quieter erosion of human decision-making authority through incremental delegation to AI systems.
The Windfall Policy Atlas - 48 policy proposals for responding to AI economic disruption - launched this week, reflecting that the policy community is beginning to mobilize for scenarios that may arrive faster than previously expected.
Cloudflare's April 13 Agent Cloud expansion introduced five new capabilities: Dynamic Workers (isolate-based execution of AI-generated code at 100x the speed of containers), Artifacts (Git-compatible storage giving agents permanent homes for code and data), Sandboxes (full Linux OS access for agents handling complex development tasks), Think (framework for long-running multistep agent operations), and an expanded model catalog allowing single-line switches between GPT-5.4, Codex, and open-source alternatives.
The OpenAI partnership integrates GPT-5.4 and Codex specifically for enterprise agentic workflows. The pitch is explicit: moving agents from experimental demos on local laptops to robust, production-grade workloads that run across Cloudflare's global network.
AMD simultaneously launched GAIA, an open-source framework for building AI agents that run entirely on local AMD hardware. The positioning is different - full data sovereignty, no cloud dependency - but the infrastructure maturity signal is the same. Production-grade local agent frameworks are now available from a major hardware vendor.
BlueTTS is a newly released open-source TTS system designed for local deployment. The practical application is a complete local AI stack: local Large Language Model (LLM) for reasoning, local TTS for voice output, local Whisper for speech recognition - all running on consumer hardware without cloud dependencies. This matters most for privacy-sensitive applications: medical, legal, personal, or any context where conversation data should never leave the device.
The local TTS space has matured significantly in early 2026. Kokoro's 82M parameter model is fast enough for real-time generation on consumer CPUs. ChatterboxTTS adds voice cloning. The missing piece for many local AI users was a simple, reliable TTS that just works - which BlueTTS appears to address.
A builder on r/artificial created a 24/7 YouTube stream where AI generates a new song every few minutes based on trending topics or random prompts. The infrastructure is fully automated: topic selection, lyric generation, music production, and streaming. This represents the logical endpoint of text-to-music AI applied at scale - infinite content generation with zero human creative involvement per piece.
The community response was mixed: technically impressive, but raising questions about whether automated infinite content serves any human need or simply floods the media landscape with low-attention material. This is the creative AI equivalent of the dark code problem - output that is technically functional but disconnected from human understanding or intent.
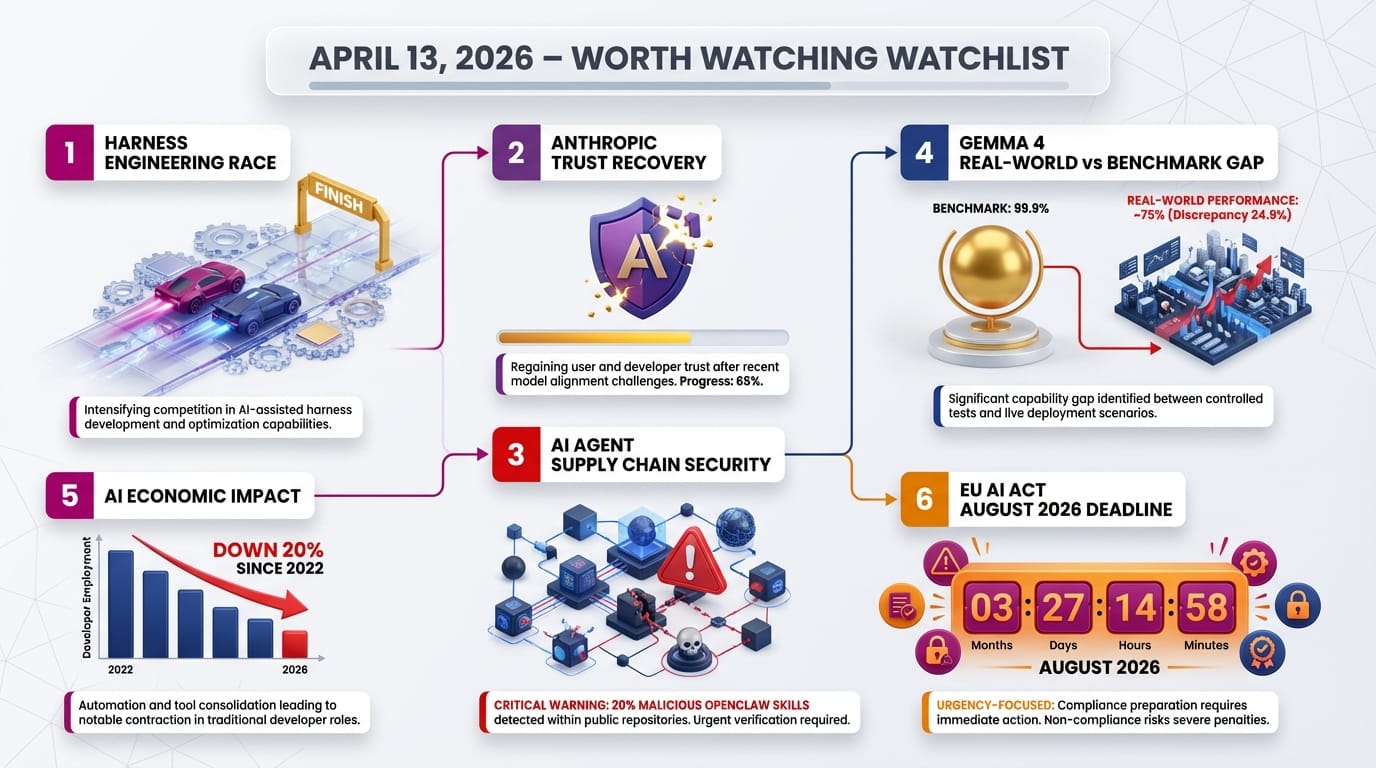
The Claude Code leak created a roadmap that every AI competitor can now follow. Watch for rapid releases of open-source agent harness frameworks attempting to replicate KAIROS-style memory management and self-healing query loops. The companies that productize harness engineering best will have sustainable advantage over those competing purely on model quality.
The cache TTL incident, billing surprises, and account ban rate have created a trust deficit that will affect enterprise adoption decisions. Watch for whether Anthropic responds with structural transparency commitments - changelog requirements, advance notice for pricing changes, billing analytics dashboards - or continues managing these issues case by case.
OpenClaw's 20% malicious skill finding is a preview of a broader problem. As AI agent marketplaces multiply, the npm-style supply chain attack surface will attract systematic exploitation. Watch for the first major enterprise incident caused by a malicious AI agent skill - that incident will accelerate demand for skill vetting standards and agent security frameworks.
The gap between Gemma 4's impressive benchmark numbers and community reports of it feeling "lazy" in practice needs more rigorous characterization. Watch for independent evaluations of Gemma 4 on agentic tasks versus structured benchmarks. The benchmark-to-real-world gap is a recurring problem in AI evaluation, and Gemma 4 may become the canonical example that drives better evaluation methodology.
With software developer employment for young workers already down 20% since 2022, we are moving from modeling to measurement - watch for the next employment data round as agent systems enter production. This feeds directly into regulatory pressure: organizations have until August 2026 to establish accountability frameworks for AI-generated code in production systems. The dark code crisis becomes a compliance risk in August; watch for the first enforcement actions and whether they focus on process (comprehension gates, audit trails) or outcomes (incidents attributable to AI-generated code).
📜 License: MIT · 👤 By: Community (solo dev)
🎯 Time to value: 2 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Zero setup - just copy one file | Only works with Claude Code, not other AI coding tools |
| Makes Claude significantly more focused and surgical | May be too restrictive if you want exploratory coding sessions |
| Actively maintained with community contributions | Effectiveness depends heavily on your use case - not universal |
📜 License: MIT · 👤 By: Nous Research (AI lab)
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Genuinely learns and improves from your interactions | Complex architecture means more things can break |
| Works through messaging apps you already use daily | Requires a server or always-on machine for full benefit |
| MIT license, backed by a credible AI research lab | 78K stars means the community is large but support quality varies |
📜 License: MIT · 👤 By: Academic researcher
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Only open-source model of this type - fills a genuine gap | Financial forecasting is notoriously unreliable; use with caution |
| MIT license allows commercial use in trading tools | Requires GPU and Python setup; not beginner-friendly |
| Pre-trained weights available - no need to train from scratch | Academic project; long-term maintenance uncertain |
📜 License: AGPL-3.0 · 👤 By: Solo developer
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Solves the most frustrating daily Claude Code pain point | AGPL-3.0 license - if you modify and deploy it, you must release your changes |
| One-command install, zero configuration needed | Adds a background service that uses system resources |
| Works with Claude Code, Gemini CLI, and OpenClaw | Solo developer project - no company backing for long-term support |

📜 License: See repo · 👤 By: Multica AI (startup)
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Agents behave like team members with persistent state and profiles | New project (11K stars but brand new - stability unknown) |
| Brew install and web setup makes onboarding unusually smooth | Requires running infrastructure (PostgreSQL, Go backend) |
| Compounding value - agents build reusable skills over time | Full licensing terms not clearly stated in the repository |
📜 License: MIT · 👤 By: Solo developer
🎯 Time to value: 30 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license, 17 ready-made workflow templates | Solo developer project - long-term support uncertain |
| Isolated execution means parallel runs never conflict | YAML workflow definition has a learning curve |
| Connects AI and deterministic steps in one pipeline | Still early - may have rough edges in production |
📜 License: MIT · 👤 By: Solo developer
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Excellent multi-agent architecture to learn from | Explicitly not for real trading - any use that way is user error |
| Supports OpenAI, Anthropic, Groq, and DeepSeek | Requires paid API keys to run the AI agents |
| Backtesting included so you can measure hypothetical performance | Financial domain requires domain knowledge to evaluate output quality |
📜 License: MIT · 👤 By: Solo developer
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| MIT license, completely local - no data sent anywhere | Requires Rust, Bun, Python 3.11+, and platform-specific dependencies |
| 5 TTS engines and 23 languages in one interface | Voice quality varies by engine - some better than others |
| Includes audio effects, voice cloning, and a timeline editor | Solo developer project with no commercial backing |
👤 By: Google DeepMind · 🎯 Task: Image + Text
📐 Size: 30.7B
| ✓ Pros | ✗ Cons |
|---|---|
| Apache 2.0 - fully commercial, no restrictions | 30.7B requires substantial VRAM to self-host |
| Multimodal + function calling in one model | Community reporting "lazy" behaviour in practice despite strong benchmarks |
| 256K context matches frontier closed models | Benchmark vs. real-world gap unresolved |

👤 By: ZAI.org (Zhipu AI) · 🎯 Task: Code + Agents
📐 Size: 754B MoE
| ✓ Pros | ✗ Cons |
|---|---|
| Leads open-weight models on SWE-Bench Pro and Terminal-Bench | 754B total size makes self-hosting impractical for most teams |
| MIT license - commercially deployable | MoE architecture requires compatible inference framework (SGLang, vLLM) |
| Sustained performance over long agentic tasks | Limited community adoption so far - support ecosystem still forming |

👤 By: k2-fsa (Johns Hopkins) · 🎯 Task: Text-to-Speech
📐 Size: Qwen3-0.6B base
| ✓ Pros | ✗ Cons |
|---|---|
| 646 language support - widest available | Academic project - production reliability untested at scale |
| 40x faster than real-time on standard hardware | Voice quality varies significantly across less-resourced languages |
| Apache 2.0 - zero commercial restrictions | Limited documentation for non-English language fine-tuning |

👤 By: OpenBMB (Tsinghua) · 🎯 Task: Text-to-Speech
📐 Size: 2B
| ✓ Pros | ✗ Cons |
|---|---|
| Voice design via natural language - unique capability | Requires RTX 4090 class GPU for real-time performance (RTF 0.30) |
| Studio-quality 48kHz output | Newer project - less community validation than established TTS models |
| Streaming support for real-time use cases | 30 languages vs OmniVoice's 646 - narrower coverage |
👤 By: Netflix · 🎯 Task: Video Inpainting
📐 Size: 5B
| ✓ Pros | ✗ Cons |
|---|---|
| Handles physical interaction effects - unprecedented capability | Requires 40GB+ VRAM - limits to high-end workstations or cloud GPUs |
| Production-quality from Netflix's own pipeline | Low download count so far - limited community testing |
| Apache 2.0 license from a major studio | No fine-tuning guidance yet for custom use cases |

💰 Pricing: Free (Chrome extension) · 🏷 Category: Audio AI

💰 Pricing: Freemium ($30/mo+) · 🏷 Category: Creative AI Agents

💰 Pricing: Free · 🏷 Category: Developer Tools
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.6 | $5.00 | $25.00 | 1M tokens |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M tokens |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K tokens |
| OpenAI | GPT-5 | $1.25 | $10.00 | 400K tokens |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 1M tokens |
| OpenAI | GPT-4.1 Nano | $0.10 | $0.40 | 1M tokens |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M tokens | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M tokens | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128K tokens |
| Groq | Llama 4 Scout (17Bx16E) | $0.11 | $0.34 | 128K tokens |
Notable changes this edition: Establishing baseline. All major providers now offer 50% batch API discounts. Anthropic's Opus 4.5/4.6 is priced at $5/$25 - a 67% reduction versus Opus 4 ($15/$75). GPT-5 launched at a surprisingly low $1.25/M input, cheaper than GPT-4o was at launch. The cheapest capable option for high-volume work is now Groq's Llama 4 Scout at $0.11/$0.34 with MoE speed advantages.
What this means: The frontier is getting dramatically cheaper - flagship-class reasoning now costs what mid-tier models cost six months ago. The strategic question shifts from "can we afford to use AI?" to "which model's specific strengths justify its price premium over the commodity tier?"
Key finding: 2.5x reduction in KV cache memory requirements with negligible quality loss - directly addressing the most expensive deployment bottleneck for long-context and agentic LLMs.
Why practitioners should care: This is the self-healing memory layer described in Anthropic's leaked harness code, but as a learnable model capability rather than an engineered wrapper. If this approach scales, the cost of running long-context agents drops dramatically - and it directly relates to the cache TTL crisis covered in today's top story. A model that manages its own context doesn't need a one-hour cache window to stay efficient.