Watch today's digest as a video summary (generated by NotebookLM)
MiniMax released M2.7, a 229-billion parameter Mixture of Experts (MoE) model where only about 10 billion parameters activate per token - meaning it runs at roughly 10B-equivalent speed despite the headline size. On software engineering benchmarks, it scores 56.22% on SWE-Pro (matching GPT-5.3-Codex), 76.5% on SWE Multilingual, and 57% on Terminal Bench 2 (which tests log analysis, bug troubleshooting, and security audits). On professional work automation, it achieves ELO 1495 on GDPval-AA - highest among open-source releases.
The model even helped build itself: an internal version improved 30% through 100+ autonomous optimization rounds and achieved a 66.6% medal rate across 22 ML (machine learning) competitions on MLE Bench Lite, second only to Opus-4.6 and GPT-5.4.
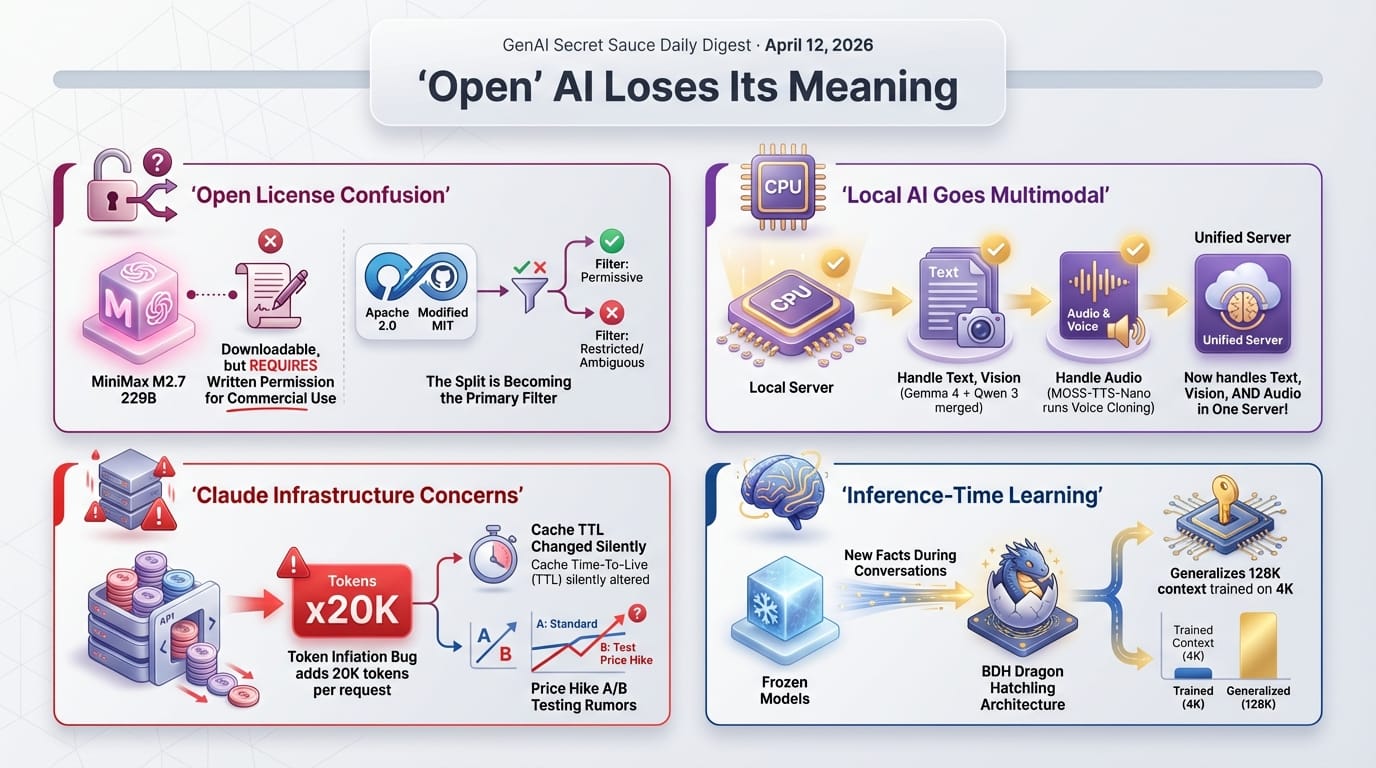
The local LLM community's reaction was swift and negative - multiple threads calling it "DOA" (dead on arrival) relative to Apache 2.0 models like Llama or Qwen3. The license restrictions carry through to all quantized versions.
- The license problem: Modified MIT terms prohibit commercial use without written authorization from MiniMax ([email protected]). Authorized users must display "Built with MiniMax M2.7" on their product
- Hardware reality: The smallest quantized version (UD-IQ1_M) runs at 60.7 GB - requiring at least a dual-Graphics Processing Unit (GPU) setup or Mac Studio with 64GB+ RAM
- Unsloth responded fast: Dynamic 2.0 quantizations from 1-bit to 16-bit BF16 are already uploaded; the community quickly noted the commercial restrictions apply to all quantized variants
Two audio-related pull requests merged into llama.cpp this week. The first adds a 12-layer Conformer encoder (a type of audio processing architecture) for Gemma 4 models, converting raw audio waveforms into embeddings the model can process. Simon Willison confirmed it works with a simple uv run command using the Gemma 4 E2B model (10.28 GB download) on Apple Silicon. The second PR adds audio support for Qwen3-Omni (text, vision, and audio) and Qwen3-ASR (audio-only transcription), processing audio in 30-second chunks through a Whisper-like transformer encoder.
A key technical finding from the Gemma 4 audio PR: the multimodal projector is highly sensitive to quantization precision - BF16 (16-bit brain float) is required for reliable results, and lower precision formats cause numerical drift. One community member also reported a 29% tokens-per-second improvement using speculative decoding with the Gemma 4 31B model paired with E2B as a draft model.
- What's now possible locally: Speech-to-text, audio Q&A, and multimodal text+vision+audio conversations - all without cloud APIs
- Supported models: Gemma 4 E2B and E4B (via mlx-vlm or llama-server), Qwen3-Omni, Qwen3-ASR
- The llama-server path: Audio processing uses the same Application Programming Interface (API) endpoint format as image processing - send an audio file, get a text response
Starting with Claude Code version 2.1.100, users are reporting approximately 20,000 extra cache-creation input tokens billed per request compared to version 2.1.98, even though the actual payload being sent is smaller. This creates roughly a 40% overhead, hitting the Claude Max usage cap significantly faster than expected.
The evidence points to server-side token injection triggered by the newer User-Agent string sent by the updated client. A parallel GitHub issue documents that Anthropic deliberately changed the prompt cache time-to-live (TTL - how long cached prompts are stored) from 1 hour to 5 minutes around March 6th, based on analysis of 119,866 API calls. Anthropic's response to the cache TTL issue was that this was intentional optimization: 1-hour writes cost approximately twice as much as 5-minute writes, so the shorter TTL actually saves most users money.
- Workaround for version 2.1.100 inflation: Either downgrade to version 2.1.98 via
npx @anthropic-ai/[email protected]or setANTHROPIC_CUSTOM_HEADERSto spoof the older User-Agent header - The cache TTL issue (separate): Anthropic says TTL is now selected per-request based on predicted cache reuse patterns, not uniformly set to 5 minutes
- Community frustration: Users cannot audit what server-side content is being added, raising questions about hidden system prompt content competing with user CLAUDE.md files
A blog post arguing that large language models (LLMs) "learn backwards" has been making rounds in r/MachineLearning. The core claim: humans develop causal reasoning before accumulating knowledge (infants test physics through exploration), while LLMs accumulate correlational knowledge without ever building the underlying causal model. The result is what the author calls crystallized intelligence without fluid intelligence - vast stored knowledge, minimal capacity for genuinely novel problem-solving.
The hard evidence cited is stark: ARC-AGI-3, a benchmark specifically designed to test real-time learning and hypothesis testing in unfamiliar environments, shows frontier models scoring under 1%. These are the same models that pass bar exams and write production code. Recent gains haven't come from scaling pre-training data - they've come from post-training interventions: RLHF (Reinforcement Learning from Human Feedback), tool use, chain-of-thought prompting. The "bitter lesson" (that human cleverness doesn't scale) is being violated by more and more human-engineered scaffolding. Gary Marcus's response to the leaked Claude Code system prompt made a similar point this week: thousands of words of explicit behavioral instructions reveal a gap between benchmark performance and deployment reliability.
- ARC-AGI-3: Tests novel pattern recognition in contexts the model has never seen - designed specifically to resist memorization
- The training data problem: Pre-training is nearing the ceiling of available human-generated text; gains require more intervention, not more scale
- What comes next: Architectures that learn dynamic world models through interaction, not static pattern matching over text
KIV (K-Indexed V Materialization) is open-source middleware that extends context windows to 1 million tokens without modifying model weights. The key insight is an asymmetry in transformer attention: K (key) vectors are smooth and indexable, while V (value) vectors carry actual content and need exact retrieval. KIV exploits this by keeping only a 2,048-token hot cache plus compressed page summaries in the GPU's memory (constant ~36 MB regardless of context length), while full K and V vectors for the entire context live in the computer's main RAM.
At each step, KIV scores page summaries on the GPU, fetches the top-32 pages' K vectors from RAM, selects the top-256 candidate tokens, fetches their V vectors, and runs standard attention on those 2,304 tokens plus the hot cache. Decode latency scales from 77ms per token at 4K context to 243ms at 1M context - slower than native but viable for chat.
- Supported models: Works with Gemma, Qwen, TinyLlama, Phi, and other models via HuggingFace's key-value cache interface
- The tradeoff: Bulk prefill is slow (~4.3 minutes to load 100K tokens upfront), so it's better for incrementally growing chat sessions than one-shot document analysis
- Hardware requirement: 12 GB GPU VRAM minimum; the full context lives in system RAM (need ~50 GB RAM for 1M tokens)

The pattern from Chinese AI labs in particular shows a recurring tension: frontier-class weights released to claim open-source credibility while commercial restrictions preserve revenue potential. The community has become expert at immediately parsing license files and distributing the verdict.
- MiniMax M2.7 requires written commercial authorization from MiniMax despite being downloadable from HuggingFace - the community reaction was immediate and negative
- FernflowerAI (Qwen3.5-35B) - an uncensored, "no refusals" variant - shows the opposite pressure: community members are removing restrictions Anthropic and others intentionally add
- HauhauCS Aggressive variant of Qwen3.5-35B reports over 1 million downloads per month, suggesting massive demand for genuinely unconstrained models
- The Apache 2.0 vs. Modified MIT split is becoming the primary filter in local LLM communities: Apache 2.0 means build freely, Modified MIT may mean write us first
The trajectory points toward a local AI stack (llama-server + llama.cpp) that handles the full multimodal pipeline with no cloud dependencies by mid-2026.
- Audio for Gemma 4 and Qwen3 merged into llama-server this week - text + vision + audio now in a single local endpoint
- MOSS-TTS-Nano (0.1B parameters, 20 languages, runs on CPU) provides local text-to-speech with voice cloning from a short reference clip, free for commercial use under Apache 2.0
- Gemma 4 on Android running real shell commands appeared in r/LocalLLaMA - multimodal models are now reaching mobile on-device deployment
- Speculative decoding with Gemma 4 31B + E2B draft model provides a 29% throughput improvement, making the hardware cost of local inference more manageable
These issues individually are manageable. Collectively, they represent eroding trust among the developer community that Claude built its early advantage with.
- Version 2.1.100 token inflation adds ~20,000 cache-creation tokens per request invisibly, documented in a public GitHub issue with no Anthropic response yet
- Cache TTL change (1 hour to 5 minutes on March 6th) was intentional but undocumented until users spent weeks investigating their API bills
- Price hike A/B testing - community speculation is growing that Anthropic is testing higher pricing for a subset of users who see different rate limits
- The "how dare you" to "running out of tokens" PSA threads on r/ClaudeAI reflect an audience hitting practical limits regularly
If this line of research matures, AI models could be updated with new facts post-deployment without expensive fine-tuning - solving one of the most persistent practical problems with LLMs in rapidly changing domains.
- BDH (Dragon Hatchling) architecture achieves GPT-2-level performance while supporting Hebbian fast weights (a type of in-session learning based on brain synapse strengthening) - facts encoded at inference time survive checkpoint saves
- Fast-weight Product Key Memory (FwPKM) achieves 128K-context generalization while trained only on 4K sequences - suggests fast weights encode structural retrieval patterns, not just memorized sequences
- BDH-fast-weights repository demonstrates a frozen model correctly retrieving all 20 jointly-encoded unrelated facts with p > 0.997 accuracy
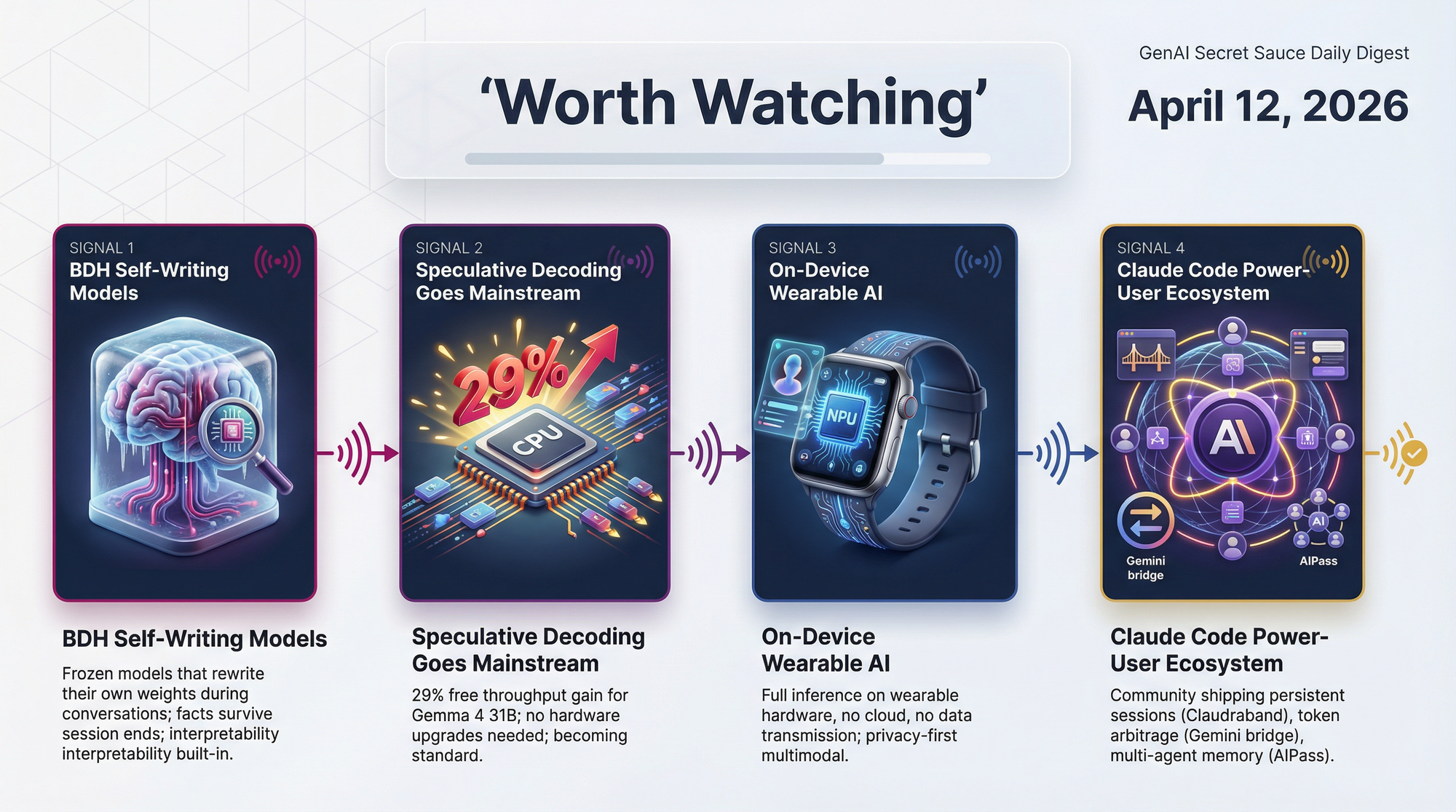
The Dragon Hatchling architecture lets a frozen language model strengthen specific internal connections during inference - based on what the current conversation needs - without any retraining. Facts encoded in one session survive checkpoint saves. If this approach scales, it represents a path to models that update their own knowledge without expensive fine-tuning cycles. The team achieved GPT-2-level performance while incorporating biological memory mechanisms. The kicker: interpretability is an inherent architectural property, not a post-hoc analysis layer.
What changes for ordinary people if this plays out: AI tools that actually get smarter about your specific work and context over time, without you having to re-explain things or a company having to charge for custom fine-tuning.
Community reports of 29% throughput gains using speculative decoding with Gemma 4 31B + E2B as a draft model, combined with growing tool support in llama.cpp, suggest this is moving from experimental to standard practice. Speculative decoding (using a small model to guess tokens, then verifying in bulk with the large model) adds no hardware cost and requires no model changes - it's pure inference-time efficiency.
What changes for ordinary people if this plays out: Consumer hardware that previously felt too slow for comfortable local AI becomes noticeably faster, without any hardware upgrades or model quality tradeoffs.
A developer project building a wearable AI that does all inference locally - no cloud, no data transmitted - represents the leading edge of what privacy-preserving AI hardware looks like in practice. The engineering constraints are severe (power, thermal, compute all severely limited on wearable form factors), but the capability trend from this week's multimodal advances in llama.cpp suggests the gap is closing faster than expected.
What changes for ordinary people if this plays out: A wearable device that sees and hears everything you do, helps you in real time, and sends none of it to a server. The privacy vs. capability tradeoff that has defined AI assistant products since Siri gets resolved in privacy's favor.
Claudraband (persistent sessions via tmux), the Gemini-Claude MCP bridge (token arbitrage), and AIPass (multi-agent memory) all shipped this week. The pattern: users are building the infrastructure around Claude Code that Anthropic hasn't built yet. Session persistence, inter-model routing, and multi-agent memory are three of the most-requested features - and the open-source community is shipping them without waiting.
What changes for ordinary people if this plays out: Claude Code goes from a powerful but session-ephemeral coding tool to a persistent engineering partner that remembers your project context, routes expensive tasks to cheaper models automatically, and coordinates multiple agents on your behalf.