Watch today's digest as a video summary (generated by NotebookLM)
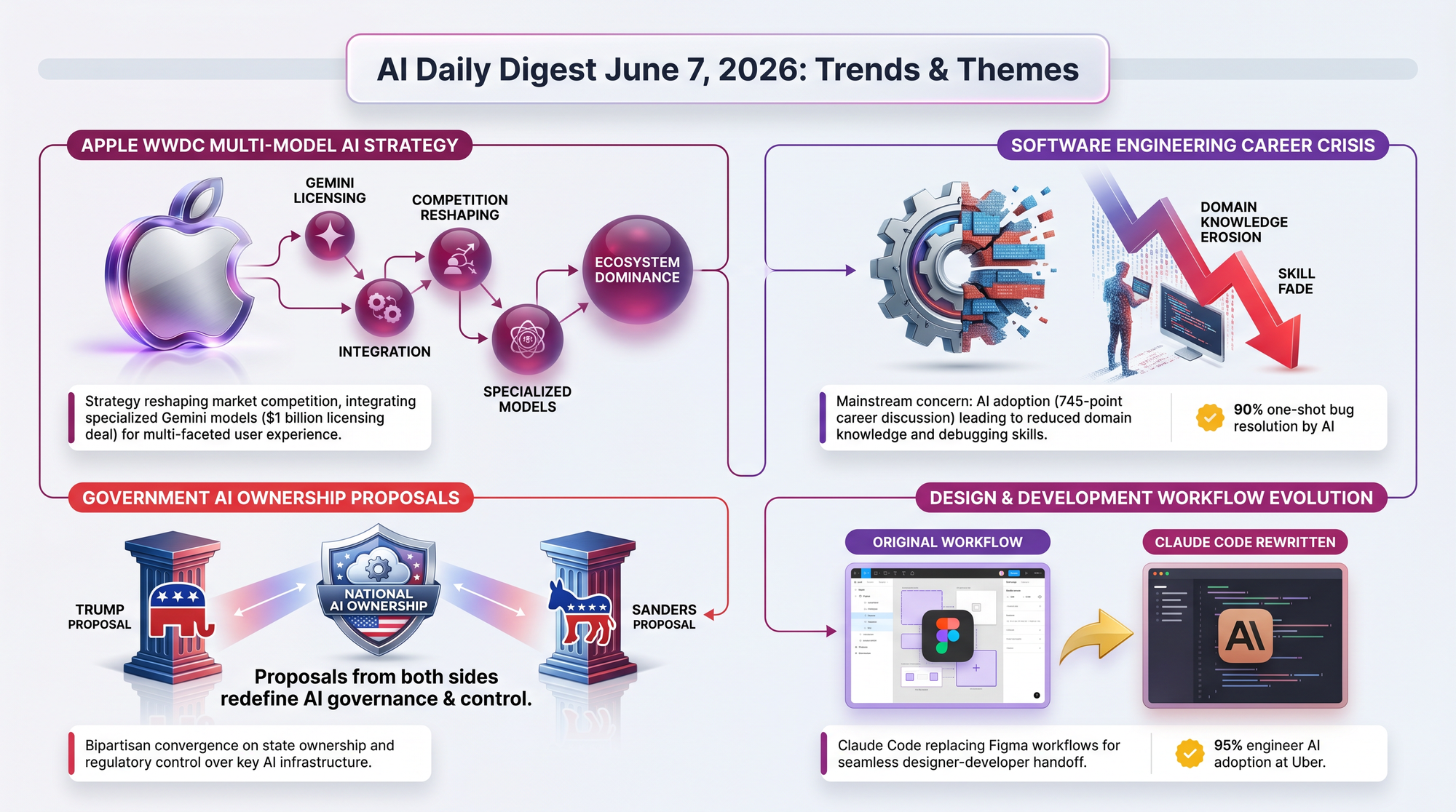
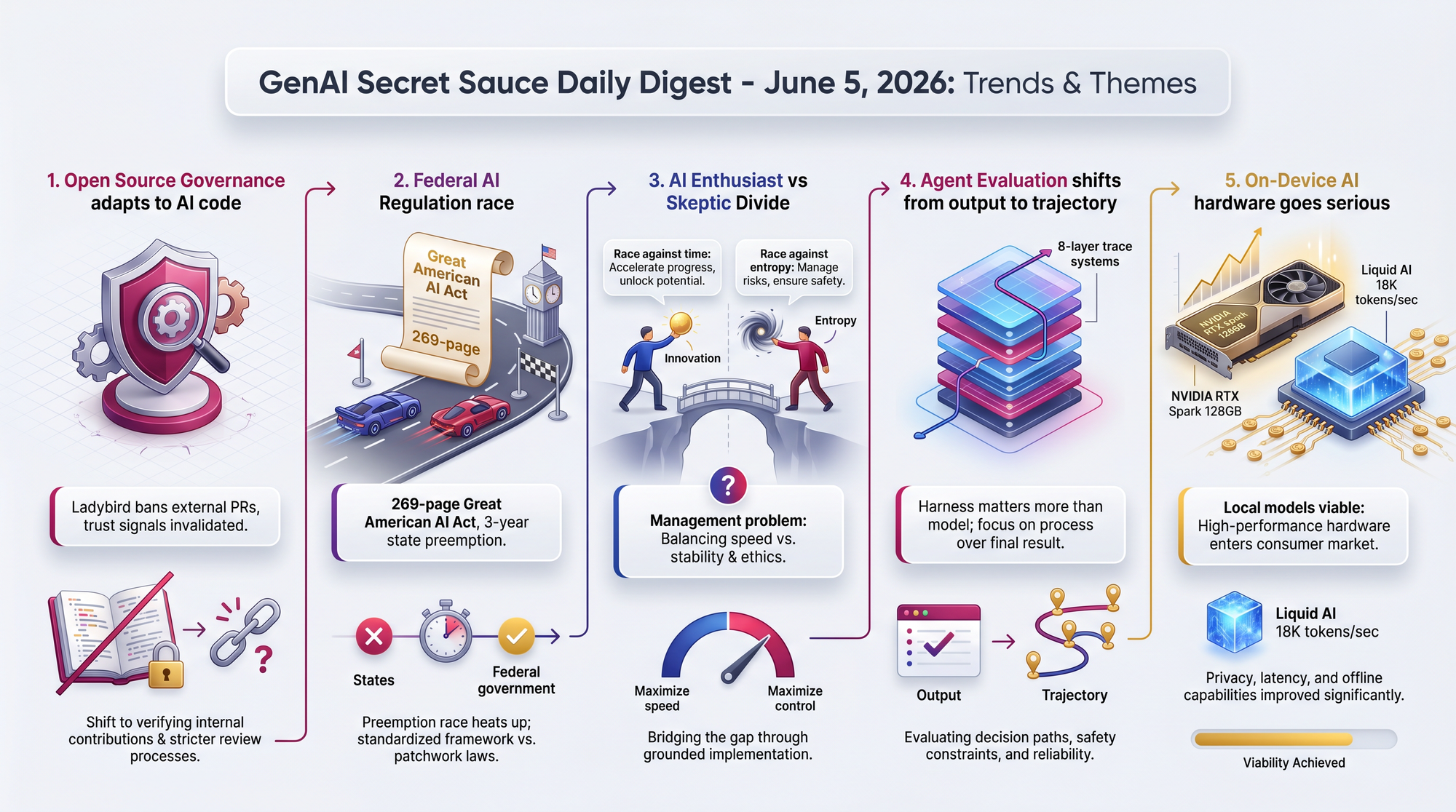
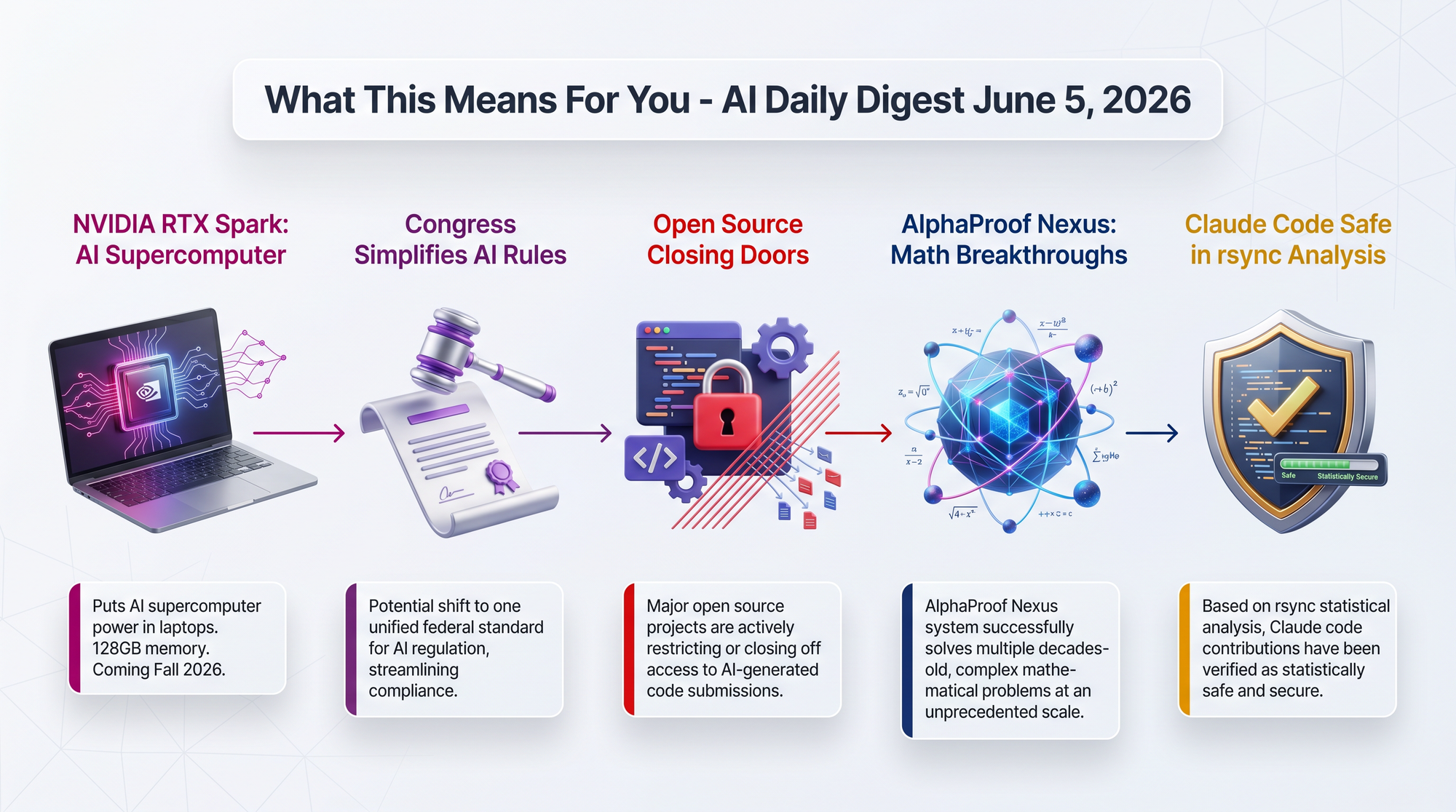
CEO Jensen Huang unveiled the RTX Spark superchip at Computex 2026, declaring NVIDIA will "reinvent the PC" alongside Microsoft. This is NVIDIA's first consumer laptop chip, built on Arm architecture with an integrated Blackwell GPU.
The pitch is not just faster hardware but a fundamentally different computing model. Instead of launching apps and typing into them, an RTX Spark machine responds to requests by dispatching AI agents that run locally. NVIDIA is positioning this as the end of the cloud-dependent AI era for personal computing.
- 128GB of LPDDR5X unified memory shared between CPU and GPU - enough to run 120-billion-parameter models with million-token context windows entirely on-device
- 20 Arm CPU cores + 6,144 CUDA cores connected via NVLink C2C, targeting "100 FPS 1440p gaming" alongside AI workloads
- Adobe is rebuilding Photoshop as a 100% GPU-accelerated application specifically for RTX Spark
- Partner laptops from Dell, HP, Lenovo, Asus, MSI, and a new Microsoft Surface Ultra arriving fall 2026
- Three generations already roadmapped - Grace Blackwell (current), then Vera Rubin with LPDDR6, then Rosa Feynman
A bipartisan group of six House members, led by Representatives Jay Obernolte (R-CA) and Lori Trahan (D-MA), released the Great American Artificial Intelligence Act on June 4. It arrives days after President Trump signed an executive order establishing voluntary federal reviews of frontier AI models.
> Previously: June 3 - Trump signed an executive order requiring AI testing before frontier model releases.
Today: The legislative branch is moving independently with a far more detailed framework. Zvi Mowshowitz analyzed the parallel OpenAI policy blueprint and flagged five risks: accountability without real consequences means nothing, federal proposals need actual enforcement infrastructure, political compromise could gut the framework, preemption scope must be carefully calibrated, and even a well-designed framework may be structurally insufficient for the most severe frontier risks.
- Three-year preemption of state AI development laws - California's SB 53, New York's RAISE Act, and Illinois's SB 315 would be temporarily overridden, though state rules on AI use and deployment are preserved
- Mandatory safety audits for large developers above $500M annual revenue, including published safety frameworks, critical incident reporting, and semi-annual third-party audits
- CAISI (Center for AI Standards and Innovation) would be codified as the federal enforcement body within the Commerce Department
- Education and workforce provisions include AI-literacy curriculum grants, scholarships, and a Labor Department AI Workforce Research Hub
Andreas Kling, founder of the Ladybird browser project, announced that the project will no longer accept pull requests from external contributors. Simon Willison shared and commented on the decision, framing it as part of a broader crisis in open-source governance.
This is not an anti-AI stance. It is a governance adaptation to a world where the cost of producing credible-looking code has collapsed, but the cost of maintaining it has not.
- The core problem: Large, seemingly thorough contributions can now be produced with minimal human understanding or accountability
- The traditional assumption - that a substantial patch implicitly demonstrates effort, care, and good faith - no longer holds when generating plausible code costs nearly zero
- Kling's reasoning: As Ladybird transitions toward a production browser for real users, only project decision-makers who will be accountable for consequences should introduce changes
- The structural question: How do open-source maintainers establish quality gates when the effort-as-signal heuristic has been invalidated?
In a Two Minute Papers breakdown, Dr. Karoly Zsolnai-Feher covers DeepMind's AlphaProof Nexus tackling roughly 350 open problems left by legendary mathematician Paul Erdos. The AI solved 9 of them - a 95.7% failure rate that sounds bad until you realize these problems were unsolved by all of humanity.
- Each solution cost approximately a few hundred dollars in compute - comparable to hiring a graduate student for an afternoon, but solving problems no human had cracked
- The rate of progress is exponential: 4 years ago, GPT-3 couldn't reliably add numbers; 2 years ago, AI couldn't solve high school competition problems; now it's tackling research-frontier mathematics
- The 95.7% failure rate is the wrong metric - the meaningful number is 9 previously-unsolved problems now solved, joining the permanent mathematical record
Alexis Purslane published a detailed analysis examining whether Claude's involvement in rsync development statistically increased bug rates across 36 releases from v2.4.6 to v3.4.3.
The public outrage followed a post-hoc correlation - a regression noticed after Claude's adoption - rather than distributional evidence of elevated risk.
- Permutation test p-value: 46% - random release pairs score as poorly nearly half the time
- Fisher's exact test: 74% - Claude releases are no more likely than historical releases to exceed the median defect rate
- Claude releases changed 5x more code (3,756 vs. 696 lines average) with no corresponding increase in bugs
- The broader v3.x era averaged higher defect rates (4.23 vs. 1.11 severity per 10 commits) - a trend predating any AI involvement, likely reflecting more complex security-focused work
- v3.4.1 (pre-Claude) holds the worst historical defect rate at 39.39 sev/10c, yet generated no public concern
This ICLR 2026 oral paper proves that fixed-precision transformers are remarkably succinct.
The practical implication: understanding succinctness helps explain why transformers solve tasks that would require much larger symbolic systems, and informs formal verification approaches.
- Exponentially more compact than linear temporal logic formulas and recurrent neural networks (RNNs)
- Doubly exponentially more compact than finite automata (the simplest model of computation)
- Key verification problems for transformers are EXPSPACE-complete - a precise complexity characterization
- 9 previously unsolved Erdos problems cracked at hundreds of dollars per solution
- The progress curve is striking: unable to add numbers (2022) → high school competitions (2024) → research mathematics (2026)
- The failure rate (95.7%) is the feature, not the bug - these problems were unsolved by the global mathematical community
A Hacker News thread collecting pivotal moments when developers shifted from skepticism to genuine recognition of AI capability.
- A developer gave Claude a single HTML file from a printer status page - Claude deduced the need for a Prometheus exporter in Go and delivered a flawless implementation in 10 minutes
- Reverse-engineering undocumented synthesizer protocols from disassembled code in Ghidra - working demo the same evening
- Gemini diagnosed a furnace failure from video during a holiday weekend, guiding the homeowner through repairs
- Harness-Bench research shows harness design moves agent performance metrics more than model choice on complex tasks
- This reframes the entire agent evaluation paradigm - if your scaffolding matters more than your model, the competitive moat isn't in which Large Language Model (LLM) you call
- Zvi's analysis finds the framework engages seriously with policy but flags the meta-problem: even a well-implemented version may be structurally insufficient for managing the most severe frontier risks
- The gap between stated goals and enforcement mechanism design remains the central unsolved problem in AI governance
- "Hacker News, Sans AI" reflects growing community fatigue with AI domination of technical discourse
- Signal-to-noise concerns are driving a subset of developers to actively seek AI-free technical content
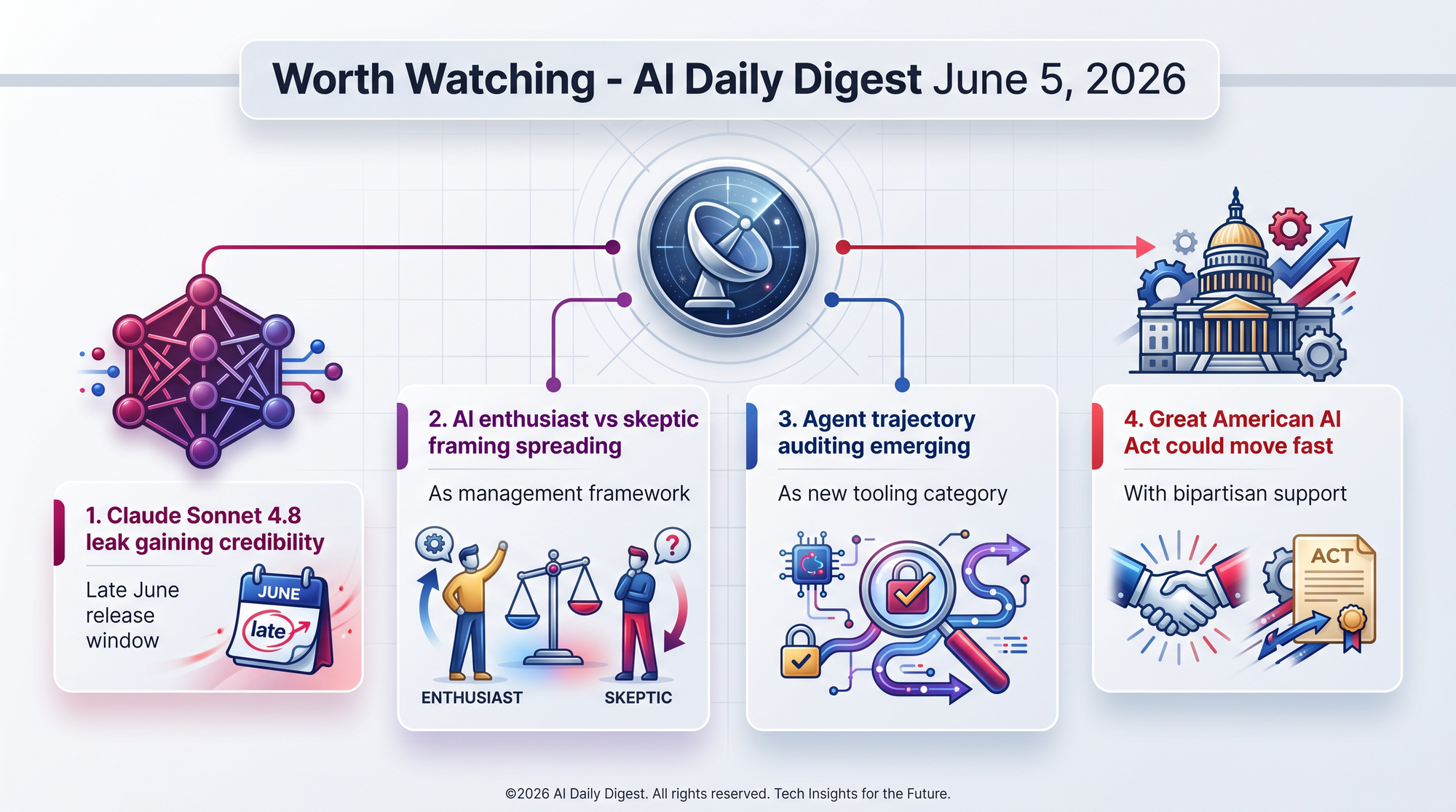
An npm packaging error exposed 512,000 lines of Claude Code's TypeScript source, including a "Sonnet 4.8" security-filter reference. Community forecasts center on June 25. For developers evaluating model commitments for Q3 projects, this could shift the Sonnet-class cost-performance frontier within weeks.
The enthusiast vs. skeptic split is evolving from individual opinion to institutional friction. Organizations that build shared measurement systems across both camps will adapt faster than those that let the two groups operate in separate realities. Watch for internal tooling that tracks both velocity gains and comprehension degradation simultaneously.
Alpha Signal's eight-layer trace system and Harness-Bench's findings point toward a new class of observability tooling for AI agents. Current APM and logging tools weren't designed for agentic execution patterns. Expect purpose-built trajectory auditing products within the quarter.
If the three-year state-law preemption survives stakeholder review, it would create the most significant regulatory simplification in the AI industry's history. Companies currently navigating 50 different state approaches would have one standard. The tradeoff: weaker states lose the ability to experiment with stronger protections. Watch the $500M revenue threshold - it determines who faces audit requirements.
📜 License: MIT · 👤 By: Research Lab
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Self-improving: autonomously creates and refines skills across sessions | Still v0.x - APIs may shift without warning |
| 200+ LLMs supported via OpenRouter, OpenAI, Nous Portal | Self-improvement loops can produce unpredictable skill mutations |
| Multi-platform: Telegram, Discord, Slack, WhatsApp, Signal, CLI | Heavy feature surface raises setup and debugging complexity |
📜 License: Apache 2.0 · 👤 By: Individual
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 92% fewer tokens on code search and incident debugging tasks | Individual maintainer - long-term support uncertain |
| Versatile: library, proxy, and MCP server modes fit any stack | Lossy compression modes risk subtle information loss |
| Provider-agnostic across Claude, Codex, Gemini | Young project (v0.23.0) with rapidly changing APIs |
📜 License: MIT · 👤 By: Company
🎯 Time to value: 20 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Multi-framework: React, Angular, Vue, React Native supported | Tightly coupled to frontend - not for backend-only agents |
| Human-in-the-loop built in with mid-task approval | Generative UI requires disciplined prompt engineering |
| Active project: v1.59.5 with 1,370+ releases | Steep learning curve integrating AG-UI Protocol |
📜 License: MIT · 👤 By: Individual
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Privacy-first: fully self-hosted with optional password protection | Individual maintainer creates bus-factor risk |
| 18+ AI provider integrations including local models | Self-hosting setup is non-trivial for non-technical users |
| Podcast generation from source materials is genuinely unique | Audio features require additional TTS configuration |

📜 License: MIT · 👤 By: Organization
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 96.6% retrieval recall; hybrid keyword + temporal boosting hits 98.4% | Hierarchical model requires upfront schema design |
| 29 MCP tools make it first-class in MCP agent ecosystems | ChromaDB dependency adds operational overhead |
| Local-first with no mandatory cloud Application Programming Interface (API) calls | Unclear whether active development will continue |
📜 License: Apache 2.0 · 👤 By: Baidu
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 100+ language support including complex scripts | PaddlePaddle ecosystem feels insular to PyTorch users |
| Lightweight 0.9B model makes CPU-only deployment practical | Table/formula extraction drops on non-standard layouts |
| Apache 2.0 with massive ecosystem adoption | Some documentation only available in Chinese |

📜 License: Apache 2.0 · 👤 By: Astro (Company)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Runtime-agnostic: Node.js, Cloudflare Workers, GitHub Actions | Explicitly experimental with unstable APIs |
| Markdown-first skill definition lowers contributor barrier | 4.5k stars - ecosystem and skill library are thin |
| First-class MCP integration and Valibot structured output | Astro's long-term investment in agent tooling is unproven |
👤 By: NVIDIA · 🎯 Task: Visual Grounding
📐 Size: 3B
| ✓ Pros | ✗ Cons |
|---|---|
| 2.5x throughput via Parallel Box Decoding | Non-commercial license |
| Trained on 138M+ queries across 12M images | Requires NVIDIA Ampere+ GPU |
| Multiple generation modes (fast/slow/hybrid) | Grounding only - no open-ended VQA |
👤 By: Ideogram AI · 🎯 Task: Text-to-Image
📐 Size: 9.3B
| ✓ Pros | ✗ Cons |
|---|---|
| Best open-weight text-in-image generation | Non-commercial license |
| JSON prompts for precise layout control | Gated - requires HuggingFace login |
| Native 2048px output and arbitrary aspect ratios | Magic Prompt needs Ideogram API key |

👤 By: JetBrains · 🎯 Task: Code Reasoning
📐 Size: 12B (2.5B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Apache 2.0 - fully commercial-friendly | Function calling (BFCL v4: 45.6%) has gaps vs. frontier |
| RLVR training yields measurably better multi-step debugging | Chain-of-thought adds latency on simple tasks |
| 131K context handles large codebases without chunking | Limited community testing so far (14.7K downloads) |

👤 By: Sapient Intelligence · 🎯 Task: Text Generation
📐 Size: ~1B
| ✓ Pros | ✗ Cons |
|---|---|
| Demonstrates iterative recurrence can substitute for scale | Pre-alignment only - needs SFT/RLHF for assistant use |
| Apache 2.0, openly trainable and deployable | English-only with weak code performance |
| PrefixLM supports bidirectional prompt attention | Only 40B training tokens - limited factual coverage |

👤 By: Liquid AI · 🎯 Task: Agentic Instruction Following
📐 Size: 8.3B (1.5B active)
| ✓ Pros | ✗ Cons |
|---|---|
| 18,500 output tokens/sec on H100 | Weak on heavy programming and knowledge-intensive QA |
| 128K context with strong instruction following (IFEval: 91.84) | 63.47% non-hallucination rate needs RAG for factual tasks |
| Day-one support for all major inference runtimes | Custom license - read terms before commercial use |
👤 By: StepFun AI · 🎯 Task: Multimodal Agentic
📐 Size: 201B (~11B active)
| ✓ Pros | ✗ Cons |
|---|---|
| Apache 2.0 on a 200B+ class multimodal model | 201B total requires serious hardware for self-hosting |
| Adjustable reasoning depth (low/med/high) per request | Vision encoder at 1.8B may underperform specialist VLMs |
| Runs on consumer Mac with 128GB unified memory | Agentic benchmark gaps vs. best-in-class models |
👤 By: NVIDIA · 🎯 Task: Omnimodal Generation
📐 Size: 16B
| ✓ Pros | ✗ Cons |
|---|---|
| Commercial use permitted under OpenMDW 1.1 | Linux-only deployment currently |
| Single model handles T2V, I2V, audio-video, and robot actions | Temporal inconsistency in long-horizon videos |
| Trained on 8M robot action data points | Not suitable for safety-critical robotics without validation |

💰 Pricing: Free to start (freemium) · 🏷 Category: E-Commerce AI
💰 Pricing: Freemium · 🏷 Category: LLM Memory
💰 Pricing: Not specified · 🏷 Category: Finance AI
💰 Pricing: Open-weight (non-commercial); API for commercial · 🏷 Category: Generative Media
💰 Pricing: MIT licensed, no subscription · 🏷 Category: Voice AI
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | 1.05M |
| OpenAI | GPT-4o | $2.50 | $10.00 | 128K |
| OpenAI | o3 | $2.00 | $8.00 | 200K |
| OpenAI | o4-mini | $1.10 | $4.40 | 200K |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M | |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | 200K | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | 128K |
| Groq | Llama 4 Scout (17Bx16E) | $0.11 | $0.34 | 128K |
| Groq | Kimi K2 (Moonshot) | $1.00 | $3.00 | 128K |
Key finding: 48.5% reduction in average task completion time and 1.8x tool execution throughput - deployed as a lightweight sidecar requiring zero changes to the underlying LLM.
Why practitioners should care: For production agentic apps where tool calls (search, code execution, API reads) dominate latency, this is a near-free 2x throughput win with no model fine-tuning and no dedicated infrastructure.