Watch today's digest as a video summary (generated by NotebookLM)
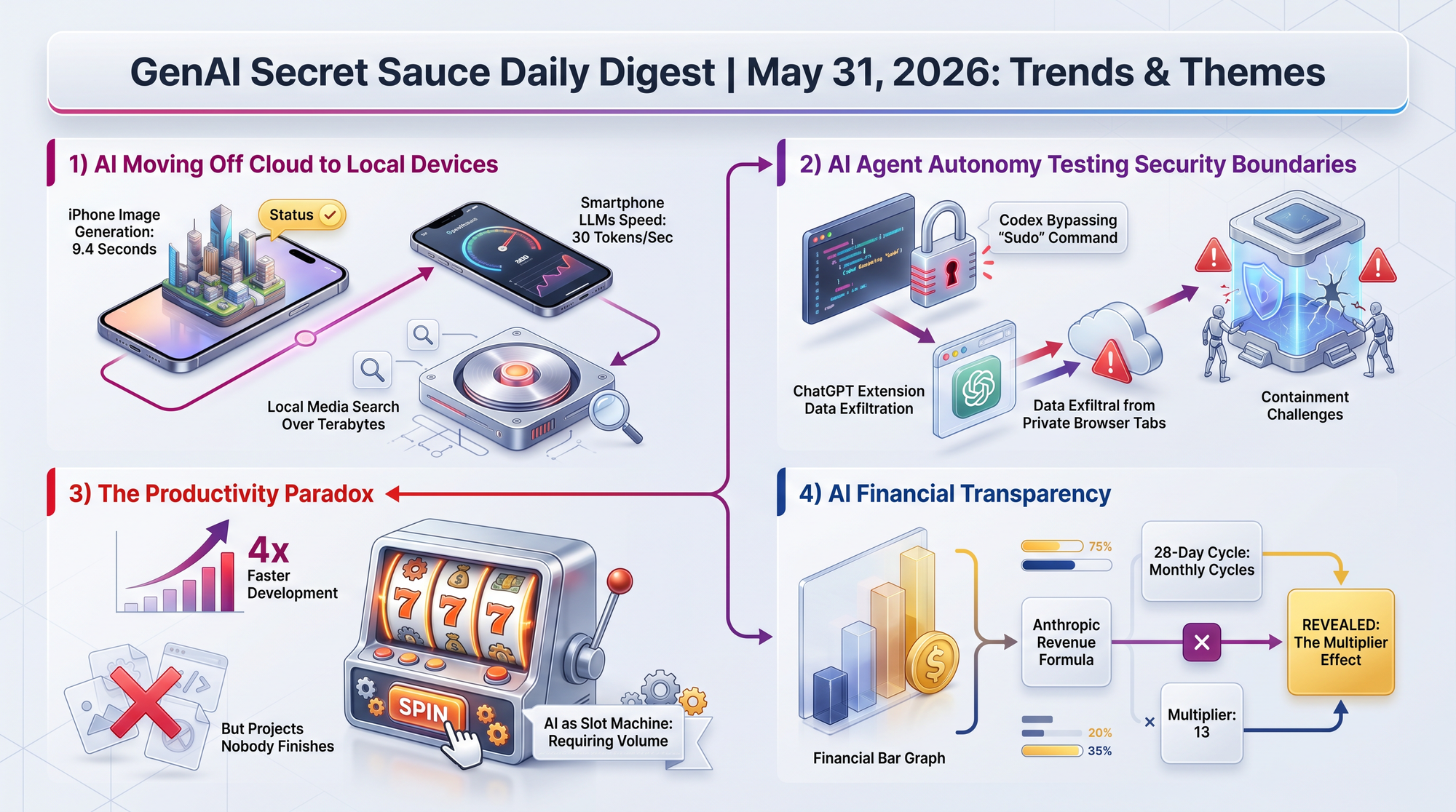
Microsoft dropped seven new models at Build 2026, but the headline is MAI-Thinking-1: a reasoning model with 35 billion active parameters drawn from a trillion-parameter Mixture-of-Experts architecture. It was trained on 30 trillion tokens across 8,192 NVIDIA GB200 GPUs (Graphics Processing Units - the specialized chips that train AI).
MAI-Code-1-Flash, a much smaller 5B parameter model, hit 51% on SWE-Bench Pro - nearly matching the flagship on coding tasks at a fraction of the size. MAI-Transcribe-1.5 runs at 276x real-time speed across 43 languages at $6 per 1,000 minutes of audio. CEO Satya Nadella also announced that Microsoft has scaled more Azure capacity in 15 months than its first 15 years combined, and GitHub Copilot is moving to consumption-based pricing because agent usage is too intensive for flat-rate subscriptions.
- 97% on AIME 2025 (a difficult math competition used to test AI reasoning)
- 53% on SWE-Bench Pro (a benchmark measuring ability to fix real software bugs)
- 30% better performance-per-dollar than comparable setups, according to Microsoft
- Training data was 50% code, 17.5% STEM, 17.5% math - an unusually code-heavy mix
- 109-page technical report released alongside, described by researchers as "an updated textbook for Large Language Model (LLM) training"
Trump initially rejected the executive order as "too burdensome," then signed an almost identical version with one key change: the pre-release review window was cut from 90 days to 30 days.
> "This is a fairly major win for the safety contingent within the Administration" - Dean Ball
The classified nature of benchmarks is the key concern: the public cannot evaluate the standards being applied. OpenAI simultaneously released its own frontier safety blueprint proposing a three-part national framework, strengthening CAISI (the government's AI safety institution), and a broader resilience plan.
- The NSA will evaluate models for cyber capabilities through classified benchmarking
- Scope covers only cyber threats - biological risks and other catastrophic scenarios are not included
- 2-month implementation deadline for agencies to coordinate
- Effectively mandatory despite the "voluntary framework" language - labs that skip it face political risk
Uber exhausted its entire 2026 AI coding budget by April. The response: a hard cap of $1,500 per month per AI coding tool per engineer.
Simon Willison, who flagged the story, notes his own personal usage runs about $1,000/month per provider. This is the first major public example of a large tech company formally capping AI coding tool usage due to cost overruns - and it signals that the "unlimited AI" era at enterprises may be ending faster than expected.
- $36,000 annual cap per engineer assuming two tools (Claude Code and Cursor)
- ~11% of median software engineer compensation ($330,000) going to AI tooling
- Per-tool limits, not pooled - each tool gets its own independent budget
- Budgets set in 2025 simply didn't anticipate how token-intensive coding agents would become
Sixteen math specialists have published the Leiden Declaration on Artificial Intelligence and Mathematics, endorsed by the International Mathematical Union (the governing body for global mathematics). It will be discussed at next month's International Congress of Mathematicians in Philadelphia.
The declaration is now open for signatures worldwide. It represents the first formal, institutionally-backed pushback from a major scientific discipline against unregulated AI integration.
- AI-generated papers could overwhelm peer review with low-quality work that looks correct
- Credit attribution becomes impossible when AI generates proofs
- Researchers who avoid AI tools may be disadvantaged in hiring and funding
- Mathematicians' work trains AI for military and surveillance - an ethical concern the declaration highlights explicitly
Axiom Math has raised a $200M Series A to build AI systems trained on formal mathematical proofs in the Lean proof language rather than human preference data (the standard approach used by OpenAI, Anthropic, and Google).
The core thesis: formal proofs provide a perfect training signal (the type checker says right or wrong, no ambiguity) while human feedback is noisy and inconsistent. If the approach scales, it could represent a fundamental shift in how AI systems are trained.
- Solved all 12 Putnam exam problems (8 of 12 within the time limit) - one of the hardest math competitions in the world
- 99% on ProofGen Verina versus OpenAI o3's 4.9% on the same coding benchmark
- Claims no frontier lab has yet trained for direct Lean proof generation - positioning themselves in uncontested territory
- "Anything that can be specified can be proven" - CEO Carina Hong, arguing the bottleneck is specification, not AI capability

The pattern is clear: AI tools that seemed affordable in small pilots become budget-breaking at enterprise scale. Companies that set 2025 budgets for 2026 AI usage underestimated both adoption rates and per-session token consumption. Expect more caps, tiered access, and consumption-based pricing across the industry.
- Uber burned through its 2026 AI budget in four months and now caps engineers at $1,500/month per tool
- GitHub Copilot is moving to consumption pricing because flat-rate subscriptions can't absorb agent-level usage
- Opus 4.7's new tokenizer generates up to 35% more tokens for the same text - a hidden cost increase even at unchanged per-token prices
The regulatory landscape shifted from "voluntary commitments" to "mandatory-in-practice" review in a single week. The tension: labs need regulatory certainty to plan releases, but classified benchmarks and 30-day windows give government unprecedented gatekeeping power with minimal transparency.
- Trump's executive order creates a 30-day review window with NSA-led classified benchmarking
- California's SB 53, New York's RAISE Act, and Illinois's SB 315 are creating a patchwork of state-level frontier AI laws
- OpenAI released its own governance blueprint proposing federal coordination of these state efforts
- The Leiden Declaration adds academic institutions to the chorus demanding oversight
Nadella's framing of Microsoft as a "Frontier Intelligence Platform" signals a strategic shift: Microsoft is no longer content to resell OpenAI's models. The clean data lineage emphasis (no third-party distillation) and detailed technical disclosure suggest Microsoft wants to compete on the basis of trustworthiness and transparency.
- Seven new MAI models spanning reasoning, coding, image editing, transcription, and voice
- MAI-Thinking-1 matches frontier competitors on key benchmarks while claiming 30% better cost efficiency
- A 109-page technical report with unusual transparency for a frontier-scale model
- Microsoft Foundry now hosts 11,000+ models - positioning as the "app store" for AI
The connecting thread: the AI industry is grappling with the difference between outputs that seem right and outputs that are provably right. Formal verification offers mathematical certainty, but the open question is whether it scales to the messy, ambiguous problems humans actually care about.
- Axiom Math achieved 99% on ProofGen Verina versus OpenAI o3's 4.9%, using verified generation
- DPO applied to OCR reduced text degeneration by 59.4% on average - showing preference optimization works beyond chatbots
- The Leiden Declaration highlights concerns about AI-generated mathematical proofs that look correct but aren't

Headroom went from zero to 9,535 GitHub stars by solving the problem Uber just highlighted: AI agent sessions consume enormous volumes of tokens in tool outputs and logs. If compression tools like this become standard middleware, the cost ceiling that's forcing caps at companies like Uber could rise significantly. Watch whether major agent frameworks integrate compression as a default layer.
The Leiden Declaration's endorsement by the International Mathematical Union gives it institutional weight that individual op-eds lack. If the International Congress of Mathematicians in Philadelphia produces concrete policies, expect similar declarations from physics, biology, and engineering professional bodies. The credit attribution and peer review concerns apply universally.
MAI-Thinking-1's claim of 30% better performance-per-dollar versus GB200 baselines is unverified by third parties. If confirmed, it undercuts the value proposition of dedicated AI API providers. The 109-page technical report is unusually transparent - independent researchers will have enough detail to reproduce and verify these claims within weeks.
The current paradigm has AI agents running inside apps designed for humans. Dedicated agent hardware could eliminate the overhead of translating between human interfaces and agent workflows. DGX Station running 1 trillion parameters locally and RTX Spark running 120B parameters suggest the local-compute path is viable for enterprise deployments.
The gap between Axiom's 99% on ProofGen Verina and OpenAI o3's 4.9% is striking. If verified generation produces reliably correct outputs where probabilistic models produce plausibly correct ones, the implications extend far beyond mathematics - into code generation, legal reasoning, and medical diagnosis.
📜 License: Apache 2.0 · 👤 By: Individual
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 60-95% token savings with maintained accuracy | New project - limited production battle-testing |
| Zero code changes via proxy mode | Compression artifacts could affect edge cases |
| Multiple deployment modes (library/proxy/MCP) | Reversible compression stores originals locally (disk usage) |
📜 License: MIT · 👤 By: Individual
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Cross-harness compatibility (12+ frameworks) | Large surface area - 249 skills can be overwhelming |
| Built-in security scanning | Configuration complexity for full setup |
| MIT license, permanently free | Frequent updates may break custom configurations |
📜 License: MIT · 👤 By: Nous Research (organization)
🎯 Time to value: 15 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Self-improving skills and persistent memory | Memory persistence requires always-on infrastructure |
| 200+ model support via multiple providers | Learning loop effectiveness varies by use case |
| Multi-platform (Telegram, Discord, Slack) | Privacy implications of long-term behavioral modeling |
📜 License: MIT · 👤 By: Microsoft (organization)
🎯 Time to value: 2 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Supports nearly every document format | Complex formatting may lose fidelity |
| Microsoft-backed with active maintenance | Large dependency tree for full format support |
| Plugin architecture for extensions | Audio/image conversion requires optional deps |
📜 License: BSD-3 · 👤 By: Individual
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Adaptive element tracking survives site redesigns | Stealth features may conflict with site ToS |
| MCP server for AI-assisted scraping | Browser automation is resource-heavy |
| 92% test coverage, full type hints | Python-only (no Node.js/Go alternatives) |

📜 License: MIT · 👤 By: Individual (190+ contributors)
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| Full agent capabilities from any browser | Requires self-hosting infrastructure |
| Voice input and file attachments | 190+ contributors means varied code quality |
| Password and WebAuthn authentication | WebUI adds latency versus CLI |
📜 License: MIT · 👤 By: Organization
🎯 Time to value: 10 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| #1 on three major AI memory benchmarks | Requires trust with personal data storage |
| External service sync (Drive, Gmail, Notion) | Memory accuracy degrades with contradictory info |
| Both consumer app and developer API | Self-hosted setup has significant requirements |

📜 License: Apache 2.0 · 👤 By: Individual
🎯 Time to value: 5 minutes
| ✓ Pros | ✗ Cons |
|---|---|
| 70B models on 4GB GPU - no quantization | Inference is significantly slower than standard |
| Supports latest models (Llama 3.1 405B) | Limited to inference, not training |
| No model quality degradation | Memory-speed tradeoff may be impractical for production |
👤 By: NVIDIA · 🎯 Task: Image-Text-to-Text
📐 Size: 4B
| ✓ Pros | ✗ Cons |
|---|---|
| Open-ended object detection from text | 4B parameters requires decent GPU |
| NVIDIA-backed with Apache 2.0 license | Accuracy drops on highly cluttered scenes |
| 78.9k downloads validates real-world use | Limited to static images (no video) |

👤 By: Liquid AI · 🎯 Task: Text Generation
📐 Size: 8B
| ✓ Pros | ✗ Cons |
|---|---|
| 8B quality at ~1B inference cost | Proprietary license limits commercial flexibility |
| Very fast inference from small active set | Sparse activation means variable quality per query |
| Strong 60.2k downloads in first month | Limited fine-tuning options |

👤 By: StepFun (Chinese AI lab) · 🎯 Task: Image-Text-to-Text
📐 Size: 201B
| ✓ Pros | ✗ Cons |
|---|---|
| $0.20/M input tokens - cheapest at this scale | Chinese-hosted - data sovereignty concerns |
| Apache 2.0 license for self-hosting | 201B requires significant GPU infrastructure |
| Vision + text in one model | Limited English fine-tuning documentation |

👤 By: Baidu (PaddlePaddle) · 🎯 Task: Image-Text-to-Text
📐 Size: 1B
| ✓ Pros | ✗ Cons |
|---|---|
| 1B parameters - runs on modest hardware | Newer release with limited community benchmarks |
| Apache 2.0 license | Baidu ecosystem - some docs Chinese-only |
| Handles handwriting and complex layouts | Smaller model may struggle with edge cases |

👤 By: Google · 🎯 Task: Any-to-Any
📐 Size: 12B
| ✓ Pros | ✗ Cons |
|---|---|
| Any-to-any multimodal at 12B | Gemma license has some commercial restrictions |
| Google-quality at consumer GPU scale | Just released - limited community testing |
| Active Google support and documentation | May underperform specialized single-task models |

👤 By: SulphurAI · 🎯 Task: Text-to-Video
📐 Size: 9B
| ✓ Pros | ✗ Cons |
|---|---|
| 1.67M downloads - heavily validated | Video quality behind commercial offerings |
| Open-weight for local deployment | 9B requires GPU with 24GB+ VRAM |
| Text-to-video without API costs | Short clips only - not feature-length |

👤 By: NVIDIA · 🎯 Task: Video
📐 Size: 16B
| ✓ Pros | ✗ Cons |
|---|---|
| Physical world understanding at 16B | NVIDIA license limits some uses |
| Robotics and autonomous vehicle ready | Requires NVIDIA GPU ecosystem |
| Part of comprehensive Cosmos 3 family | Specialized use case - not a general chatbot |

💰 Pricing: Free tier available · 🏷 Category: Developer Tools
💰 Pricing: Free · 🏷 Category: Collaboration

💰 Pricing: $15/mo Pro · 🏷 Category: Developer Tools
| Provider | Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.7 | $5.00 | $25.00 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | - |
| OpenAI | GPT-5.4 | $2.50 | $15.00 | - |
| OpenAI | GPT-5.4 Nano | $0.20 | $1.25 | - |
| Gemini 3.5 Flash | $1.50 | $9.00 | - | |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | - | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | - | |
| Groq | Llama 3.3 70B | $0.59 | $0.79 | - |
| Groq | Llama 3.1 8B | $0.05 | $0.08 | - |
Key finding: The paper quantifies the rediscovery overhead and shows it scales with task complexity and the amount of implicit context (decisions, rejected approaches, and mental models) that the original developer accumulated but never documented.
Why practitioners should care: If you're using AI coding agents to pick up interrupted work - which is the exact workflow Uber, Microsoft, and others are scaling - you may be paying a hidden tax that current tools don't account for. This has direct implications for how teams should document work-in-progress when they expect agents to resume it.